This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
The solution offers two TM retrieval modes for users to choose from: vector and document search. When using the Amazon OpenSearch Service adapter (document search), translation unit groupings are parsed and stored into an index dedicated to the uploaded file. This is covered in detail later in the post.
Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. Complete the following steps: Choose an AWS Region Amazon Q supports (for this post, we use the us-east-1 Region). aligned identity provider (IdP).
Lets assume that the question What date will AWS re:invent 2024 occur? The corresponding answer is also input as AWS re:Invent 2024 takes place on December 26, 2024. If the question was Whats the schedule for AWS events in December?, This setup uses the AWS SDK for Python (Boto3) to interact with AWS services.
Summary: This guide explores the top list of ETL tools, highlighting their features and use cases. To harness this data effectively, businesses rely on ETL (Extract, Transform, Load) tools to extract, transform, and load data into centralized systems like data warehouses. What is ETL? What are ETL Tools?
This brings reliability to data ETL (Extract, Transform, Load) processes, query performances, and other critical data operations. Documentation and Disaster Recovery Made Easy Data is the lifeblood of any organization, and losing it can be catastrophic. So why using IaC for Cloud Data Infrastructures?
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. Though it’s worth mentioning that Airflow isn’t used at runtime as is usual for extract, transform, and load (ETL) tasks.
Overview of RAG The RAG pattern lets you retrieve knowledge from external sources, such as PDF documents, wiki articles, or call transcripts, and then use that knowledge to augment the instruction prompt sent to the LLM. For more information about AWS CDK installation, refer to Getting started with the AWS CDK.
This post presents a solution that uses a workflow and AWS AI and machine learning (ML) services to provide actionable insights based on those transcripts. We use multiple AWS AI/ML services, such as Contact Lens for Amazon Connect and Amazon SageMaker , and utilize a combined architecture. im', 0.08224299065420558), ('jun 23.
Kafka And ETL Processing: You might be using Apache Kafka for high-performance data pipelines, stream various analytics data, or run company critical assets using Kafka, but did you know that you can also use Kafka clusters to move data between multiple systems. A three-step ETL framework job should do the trick. Conclusion.
Summary: This article explores the significance of ETL Data in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
In this post, we show you how SnapLogic , an AWS customer, used Amazon Bedrock to power their SnapGPT product through automated creation of these complex DSL artifacts from human language. SnapLogic background SnapLogic is an AWS customer on a mission to bring enterprise automation to the world.
The Product Stewardship department is responsible for managing a large collection of regulatory compliance documents. Example questions might be “What are the restrictions for CMR substances?”, “How long do I need to keep the documents related to a toluene sale?”, or “What is the reach characterization ratio and how do I calculate it?”
The following figure shows an example diagram that illustrates an orchestrated extract, transform, and load (ETL) architecture solution. Using architecture diagrams as an example, the solution needs to search through reference links and technical documents for architecture diagrams and identify the services present.
When the automated content processing steps are complete, you can use the output for downstream tasks, such as to invoke different components in a customer service backend application, or to insert the generated tags into metadata of each document for product recommendation. The Step Functions workflow starts.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
The service, which was launched in March 2021, predates several popular AWS offerings that have anomaly detection, such as Amazon OpenSearch , Amazon CloudWatch , AWS Glue Data Quality , Amazon Redshift ML , and Amazon QuickSight. To learn more, see the documentation. To learn more, see the documentation.
Text analytics: Text analytics, also known as text mining, deals with unstructured text data, such as customer reviews, social media comments, or documents. A well-documented case is the UK government’s failed attempt to create a unified healthcare records system, which wasted billions of taxpayer dollars.
Extraction, Transform, Load (ETL). AWS Glue helps users to build data catalogues, and Quicksight provides data visualisation and dashboard construction. The services from AWS can be catered to meet the needs of each business user. It allows users to organise, monitor and schedule ETL processes through the use of Python.
AWS provides several tools to create and manage ML model deployments. 2 If you are somewhat familiar with AWS ML base tools, the first thing that comes to mind is “Sagemaker”. AWS Sagemeaker is in fact a great tool for machine learning operations (MLOps) to automate and standardize processes across the ML lifecycle. S3 buckets.
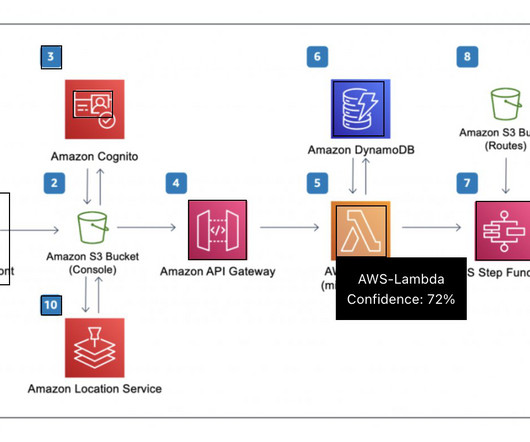
Amazon Comprehend is a fully managed and continuously trained natural language processing (NLP) service that can extract insight about the content of a document or text. API Gateway passes the request to AWS Lambda and calls the API from Amazon DynamoDB and Amazon Comprehend in Steps 3 and 4.
Each triplet describes a fact, and an encapsulation of the fact as a question-answer pair to emulate an ideal response, derived from a knowledge source document. We used Amazon’s Q2 2023 10Q report as the source document from the SEC’s public EDGAR dataset to create 10 question-answer-fact triplets.
In this post, we discuss how CCC Intelligent Solutions (CCC) combined Amazon SageMaker with other AWS services to create a custom solution capable of hosting the types of complex artificial intelligence (AI) models envisioned. Step-by-step solution Step 1 A client makes a request to the AWS API Gateway endpoint.
Typical use cases include ETL (Extract, Transform, Load) tasks, data quality enhancement, and data governance across various industries. AWS Glue AWS Glue is a fully managed ETL service provided by Amazon Web Services. It integrates seamlessly with other AWS services like Amazon S3, Redshift, and Athena.
For instance, a notebook that monitors for model data drift should have a pre-step that allows extract, transform, and load (ETL) and processing of new data and a post-step of model refresh and training in case a significant drift is noticed. Refer to SageMaker documentation for detailed instructions. train sst2.train train sst2.train
These teams are as follows: Advanced analytics team (data lake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases. words for English).
They usually operate outside any data governance structure; often, no documentation exists outside the user’s mind. Cloud Storage Upload Snowflake can easily upload files from cloud storage (AWS S3, Azure Storage, GCP Cloud Storage). ETL applications are often expensive and require some level of expertise to run.
Understanding Fivetran Fivetran is a popular Software-as-a-Service platform that enables users to automate the movement of data and ETL processes across diverse sources to a target destination. For a longer overview, along with insights and best practices, please feel free to jump back to the previous blog.
These encoder-only architecture models are fast and effective for many enterprise NLP tasks, such as classifying customer feedback and extracting information from large documents. Integrations between watsonx.data and AWS solutions include Amazon S3, EMR Spark, and later this year AWS Glue, as well as many more to come.
The Lineage & Dataflow API is a good example enabling customers to add ETL transformation logic to the lineage graph. This kit offers an open DQ API, developer documentation, onboarding, integration best practices, and co-marketing support. A pillar of Alation’s platform strategy is openness and extensibility.
And that’s when what usually happens, happened: We came for the ML models, we stayed for the ETLs. But even when the ETLs were well thought out, they were a bit “outdated” in their approach. 2 To teach them how to use the stack considered best for them (mostly focusing on fundamentals of MLOps and AWS Sagemaker / Sagemaker Studio).
Tips When Considering Streamsets Data Collector: As a Snowflake partner, Streamsets includes very intricate documentation on using Data Collector with Snowflake, including this book you can read here. For those looking to migrate to Snowflake who prefer using AWS services, DMS is a great solution.
For instance, if the collected data was a text document in the form of a PDF, the data preprocessing—or preparation stage —can extract tables from this document. The pipeline in this stage can convert the document into CSV files, and you can then analyze it using a tool like Pandas. Unstructured.io
Metadata Management can be performed manually by creating spreadsheets and documents notating information about the various datasets. Thankfully, there are tools available to help with metadata management, such as AWS Glue, Azure Data Catalog, or Alation, that can automate much of the process.
Textual Data Textual data is one of the most common forms of unstructured data and can be in the format of documents, social media posts, emails, web pages, customer reviews, or conversation logs. These capture the semantic relationships between words, facilitating tasks like classification and clustering within ETL pipelines.
This also means that it comes with a large community and comprehensive documentation. Flexibility: Its use cases are wider than just machine learning; for example, we can use it to set up ETL pipelines. Also, it is a bit more difficult to find resources online other than the official documentation.
References : Links to internal or external documentation with background information or specific information used within the analysis presented in the notebook. You could link this section to any other piece of documentation. documentation. Later, you can go through its extensive documentation to understand all of its features.
This brings interpersonal challenges, and the AI/ML teams are encouraged to build good relationships with clients to help support the models by telling people how to use the solution instead of just exposing the endpoint without documentation or telling them how. quality attributes) and metadata enrichment (e.g.,
This typically results in long-running ETL pipelines that cause decisions to be made on stale or old data. Business-Focused Operation Model: Teams can shed countless hours of managing long-running and complex ETL pipelines that do not scale.
At a high level, we are trying to make machine learning initiatives more human capital efficient by enabling teams to more easily get to production and maintain their model pipelines, ETLs, or workflows. For example, let’s take Airflow , AWS SageMaker pipelines. How is DAGWorks different from other popular solutions?
Customers want to search through all of the data and applications across their organization, and they want to see the provenance information for all of the documents retrieved. A state machine in AWS Step Functions defines the workflow of the ingestion process by invoking AWS Lambda functions, as illustrated in the following figure.
Lets say the task at hand is to predict the root cause categories (Customer Education, Feature Request, Software Defect, Documentation Improvement, Security Awareness, and Billing Inquiry) for customer support cases. We suggest consulting LLM prompt engineering documentation such as Anthropic prompt engineering for experiments.
It uses Amazon Bedrock , AWS Health , AWS Step Functions , and other AWS services. Some examples of AWS-sourced operational events include: AWS Health events — Notifications related to AWS service availability, operational issues, or scheduled maintenance that might affect your AWS resources.
Recognizing this challenge as an opportunity for innovation, F1 partnered with Amazon Web Services (AWS) to develop an AI-driven solution using Amazon Bedrock to streamline issue resolution. The objective was to use AWS to replicate and automate the current manual troubleshooting process for two candidate systems.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content