This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In India, the KYC verification usually involves identity verification through identification documents for Indian citizens, such as a PAN card or Aadhar card, address verification, and income verification. Amazon Textract is used to extract text information from the uploaded documents. I need a loan for 150000.
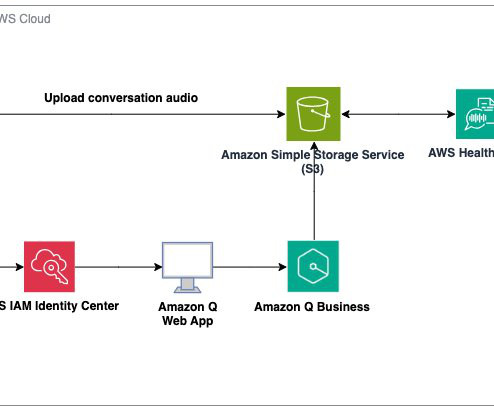
With the advent of generative AI and machinelearning, new opportunities for enhancement became available for different industries and processes. AWS HealthScribe combines speech recognition and generative AI trained specifically for healthcare documentation to accelerate clinical documentation and enhance the consultation experience.
By Jayita Gulati on June 23, 2025 in MachineLearning Image by Editor (Kanwal Mehreen) | Canva Machinelearning projects involve many steps. It manages the entire machinelearning lifecycle. It also works with cloud services like AWS SageMaker. Keeping track of experiments and models can be hard.
If youre an AI-focused developer, technical decision-maker, or solution architect working with Amazon Web Services (AWS) and language models, youve likely encountered these obstacles firsthand. Why MCP matters for AWS users For AWS customers, MCP represents a particularly compelling opportunity. What is the MCP?
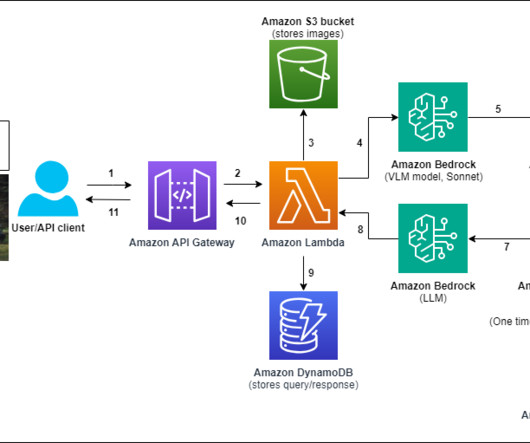
Enterprises in industries like manufacturing, finance, and healthcare are inundated with a constant flow of documents—from financial reports and contracts to patient records and supply chain documents. The Amazon S3 upload triggers an AWS Lambda function execution.
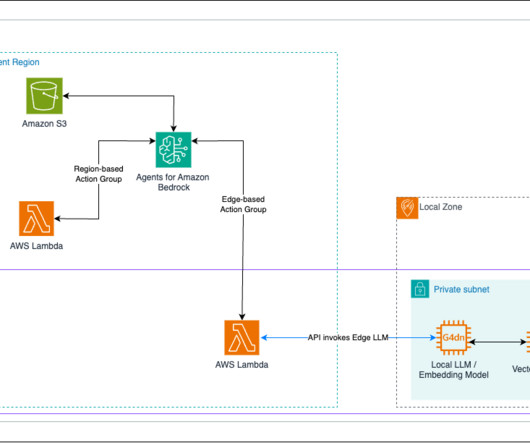
In this post, we show how to extend Amazon Bedrock Agents to hybrid and edge services such as AWS Outposts and AWS Local Zones to build distributed Retrieval Augmented Generation (RAG) applications with on-premises data for improved model outcomes.
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. Third, we’ll explore the robust infrastructure services from AWS powering AI innovation, featuring Amazon SageMaker , AWS Trainium , and AWS Inferentia under AI/ML, as well as Compute topics.
Machinelearning (ML) has emerged as a powerful tool to help nonprofits expedite manual processes, quickly unlock insights from data, and accelerate mission outcomesfrom personalizing marketing materials for donors to predicting member churn and donation patterns. For a full list of custom model types, check out this documentation.
Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles. Principal also used the AWS open source repository Lex Web UI to build a frontend chat interface with Principal branding.
The solution proposed in this post relies on LLMs context learning capabilities and prompt engineering. It enables you to use an off-the-shelf model as is without involving machinelearning operations (MLOps) activity. The solution offers two TM retrieval modes for users to choose from: vector and document search.
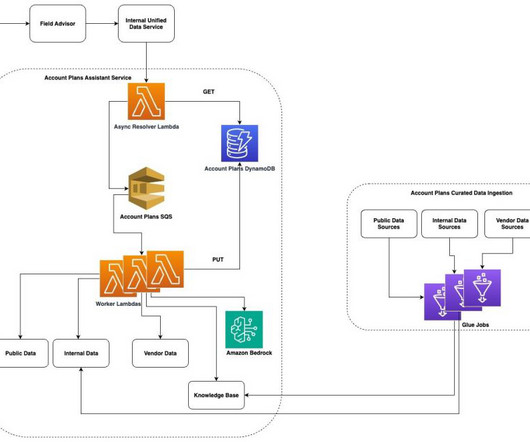
Earlier this year, we published the first in a series of posts about how AWS is transforming our seller and customer journeys using generative AI. Field Advisor serves four primary use cases: AWS-specific knowledge search With Amazon Q Business, weve made internal data sources as well as public AWS content available in Field Advisors index.
Syngenta and AWS collaborated to develop Cropwise AI , an innovative solution powered by Amazon Bedrock Agents , to accelerate their sales reps’ ability to place Syngenta seed products with growers across North America. The collaboration between Syngenta and AWS showcases the transformative power of LLMs and AI agents.
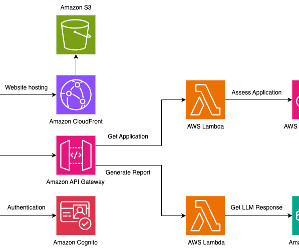
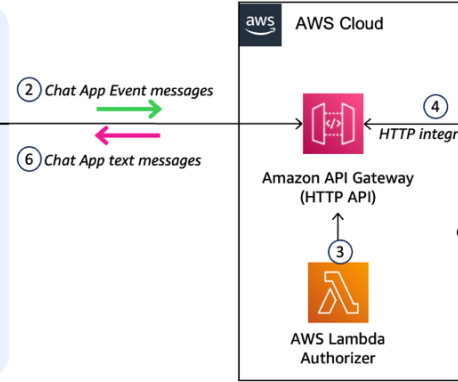
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. You can use AWS services such as Application Load Balancer to implement this approach. API Gateway also provides a WebSocket API. These components are illustrated in the following diagram.
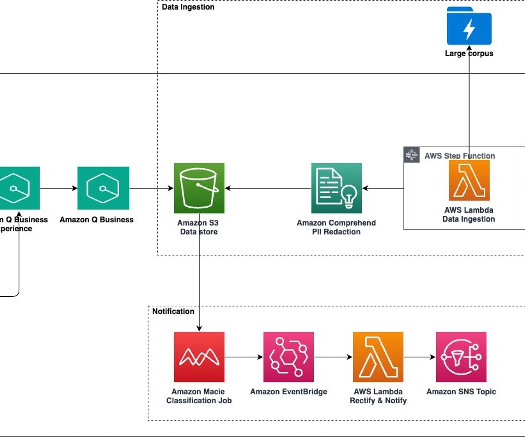
Large-scale data ingestion is crucial for applications such as document analysis, summarization, research, and knowledge management. These tasks often involve processing vast amounts of documents, which can be time-consuming and labor-intensive. Then we introduce the solution deployment using three AWS CloudFormation templates.
Every year, AWS Sales personnel draft in-depth, forward looking strategy documents for established AWS customers. These documents help the AWS Sales team to align with our customer growth strategy and to collaborate with the entire sales team on long-term growth ideas for AWS customers.
For businesses, RAG offers a powerful way to use internal knowledge by connecting company documentation to a generative AI model. When an employee asks a question, the RAG system retrieves relevant information from the company’s internal documents and uses this context to generate an accurate, company-specific response.
Traditional keyword-based search mechanisms are often insufficient for locating relevant documents efficiently, requiring extensive manual review to extract meaningful insights. This solution improves the findability and accessibility of archival records by automating metadata enrichment, document classification, and summarization.
In the mortgage servicing industry, efficient document processing can mean the difference between business growth and missed opportunities. Onity processes millions of pages across hundreds of document types annually, including legal documents such as deeds of trust where critical information is often contained within dense text.
A large portion of that information is found in text narratives stored in various document formats such as PDFs, Word files, and HTML pages. Some information is also stored in tables (such as price or product specification tables) embedded in those same document types, CSVs, or spreadsheets.
Between monitoring, analyzing, and documenting architectural findings, a lack of crucial information can leave your organization vulnerable to potential risks and inefficiencies. Prerequisites For this walkthrough, the following are required: An AWS account. AWS Management Console access. A Python 3.12 environment.
The traditional approach of manually sifting through countless research documents, industry reports, and financial statements is not only time-consuming but can also lead to missed opportunities and incomplete analysis. Along the way, it also simplified operations as Octus is an AWS shop more generally.
Creating professional AWS architecture diagrams is a fundamental task for solutions architects, developers, and technical teams. These diagrams serve as essential communication tools for stakeholders, documentation of compliance requirements, and blueprints for implementation teams.
Exclusive to Amazon Bedrock, the Amazon Titan family of models incorporates 25 years of experience innovating with AI and machinelearning at Amazon. The AWS Command Line Interface (AWS CLI) installed on your machine to upload the dataset to Amazon S3. If enabled, its status will display as Access granted.
To address this need, AWS generative AI best practices framework was launched within AWS Audit Manager , enabling auditing and monitoring of generative AI applications. Figure 1 depicts the systems functionalities and AWS services. Select AWS Generative AI Best Practices Framework for assessment. Choose Create assessment.
The market size for multilingual content extraction and the gathering of relevant insights from unstructured documents (such as images, forms, and receipts) for information processing is rapidly increasing. These languages might not be supported out of the box by existing document extraction software.
This post explores how OMRON Europe is using Amazon Web Services (AWS) to build its advanced ODAP and its progress toward harnessing the power of generative AI. Some of these tools included AWS Cloud based solutions, such as AWS Lambda and AWS Step Functions.
The potential for such large business value is galvanizing tens of thousands of enterprises to build their generative AI applications in AWS. This post addresses these cost considerations so you can optimize your generative AI costs in AWS. Annual costs (directional)*. These costs are based on assumptions.
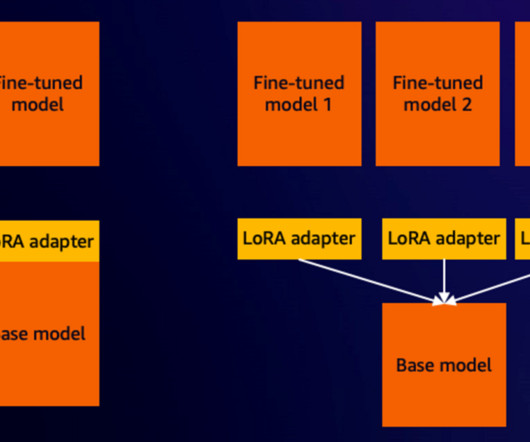
Building upon a previous MachineLearning Blog post to create personalized avatars by fine-tuning and hosting the Stable Diffusion 2.1 We show how to then prepare the fine-tuned model to run on AWS Inferentia2 powered Amazon EC2 Inf2 instances , unlocking superior price performance for your inference workloads.
For instance, consider an AI-driven legal document analysis system designed for businesses of varying sizes, offering two primary subscription tiers: Basic and Pro. Meanwhile, the business analysis interface would focus on text summarization for analyzing various business documents. This is illustrated in the following figure.
Were excited to announce the open source release of AWS MCP Servers for code assistants a suite of specialized Model Context Protocol (MCP) servers that bring Amazon Web Services (AWS) best practices directly to your development workflow. This post is the first in a series covering AWS MCP Servers.
The banking industry has long struggled with the inefficiencies associated with repetitive processes such as information extraction, document review, and auditing. By using cutting-edge generative AI and deep learning technologies, Apoidea has developed innovative AI-powered solutions that address the unique needs of multinational banks.
For many of these use cases, businesses are building Retrieval Augmented Generation (RAG) style chat-based assistants, where a powerful LLM can reference company-specific documents to answer questions relevant to a particular business or use case. Generate a grounded response to the original question based on the retrieved documents.
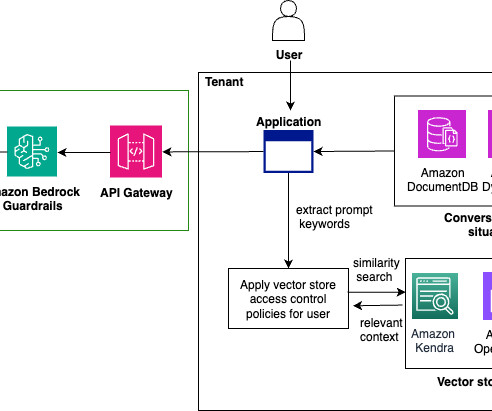
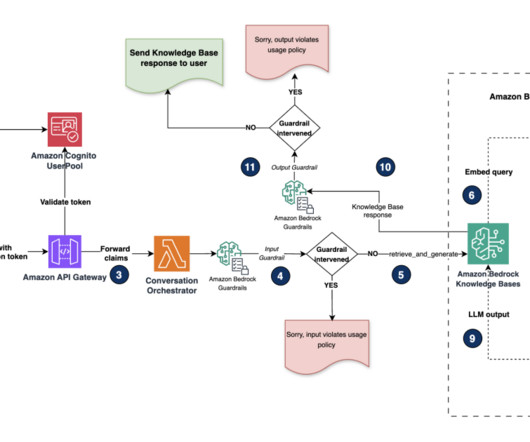
A common adoption pattern is to introduce document search tools to internal teams, especially advanced document searches based on semantic search. In a real-world scenario, organizations want to make sure their users access only documents they are entitled to access. The following diagram depicts the solution architecture.
From summarizing complex legal documents to powering advanced chat-based assistants, AI capabilities are expanding at an increasing pace. The challenge: Analyzing unstructured enterprise documents at scale Despite the widespread adoption of AI, many enterprise AI projects fail due to poor data quality and inadequate controls.
Powered by generative AI services on AWS and large language models (LLMs) multi-modal capabilities, HCLTechs AutoWise Companion provides a seamless and impactful experience. This personalized document helps the customer gain a deeper understanding of the vehicle and supports their decision-making process.
At AWS, were using the power of models in Amazon Bedrock to drive automation of complex processes that have traditionally been challenging to streamline. In this post, we focus on one such complex workflow: document processing. The solution uses the FMs tool use capabilities, accessed through the Amazon Bedrock Converse API.
Using vLLM on AWS Trainium and Inferentia makes it possible to host LLMs for high performance inference and scalability. Deploy vLLM on AWS Trainium and Inferentia EC2 instances In these sections, you will be guided through using vLLM on an AWS Inferentia EC2 instance to deploy Meta’s newest Llama 3.2 You will use inf2.xlarge
This post discusses how to use AWS Step Functions to efficiently coordinate multi-step generative AI workflows, such as parallelizing API calls to Amazon Bedrock to quickly gather answers to lists of submitted questions. sync) pattern, which automatically waits for the completion of asynchronous jobs.
To assist in this effort, AWS provides a range of generative AI security strategies that you can use to create appropriate threat models. Document chunks are then encoded with an embedding model to convert them to document embeddings. For all data stored in Amazon Bedrock, the AWS shared responsibility model applies.
You can try out the models with SageMaker JumpStart, a machinelearning (ML) hub that provides access to algorithms, models, and ML solutions so you can quickly get started with ML. The model is deployed in an AWS secure environment and under your virtual private cloud (VPC) controls, helping provide data security.
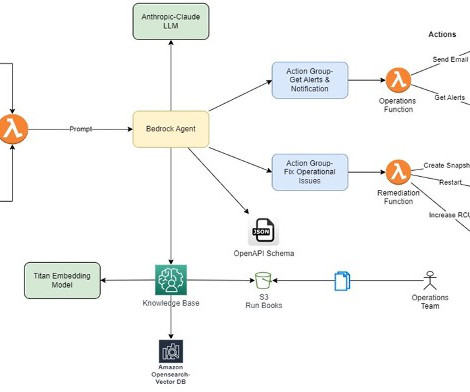
As AWS environments grow in complexity, troubleshooting issues with resources can become a daunting task. Fortunately, AWS provides a powerful tool called AWS Support Automation Workflows , which is a collection of curated AWS Systems Manager self-service automation runbooks. The agent uses Anthropics Claude 3.5
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. The following figure illustrates the high-level design of the solution.
AI for IT operations (AIOps) is the application of AI and machinelearning (ML) technologies to automate and enhance IT operations. This post presents a comprehensive AIOps solution that combines various AWS services such as Amazon Bedrock , AWS Lambda , and Amazon CloudWatch to create an AI assistant for effective incident management.
Gardenia Technologies, a data analytics company, partnered with the AWS Prototyping and Cloud Engineering (PACE) team to develop Report GenAI , a fully automated ESG reporting solution powered by the latest generative AI models on Amazon Bedrock. The agent then works collaboratively with ESG professionals to review and fine-tune responses.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content