This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
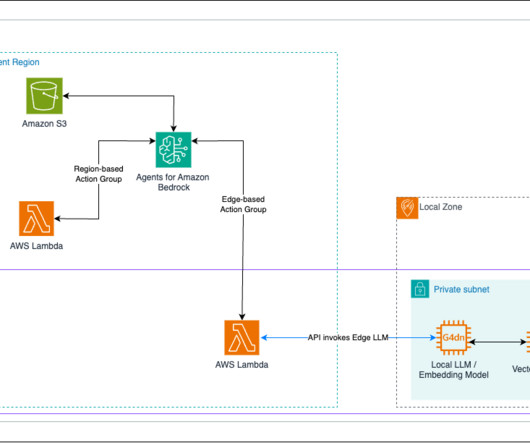
In this post, we show how to extend Amazon Bedrock Agents to hybrid and edge services such as AWS Outposts and AWS Local Zones to build distributed Retrieval Augmented Generation (RAG) applications with on-premises data for improved model outcomes.
Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles. Principal also used the AWS open source repository Lex Web UI to build a frontend chat interface with Principal branding.
Syngenta and AWS collaborated to develop Cropwise AI , an innovative solution powered by Amazon Bedrock Agents , to accelerate their sales reps’ ability to place Syngenta seed products with growers across North America. The collaboration between Syngenta and AWS showcases the transformative power of LLMs and AI agents.
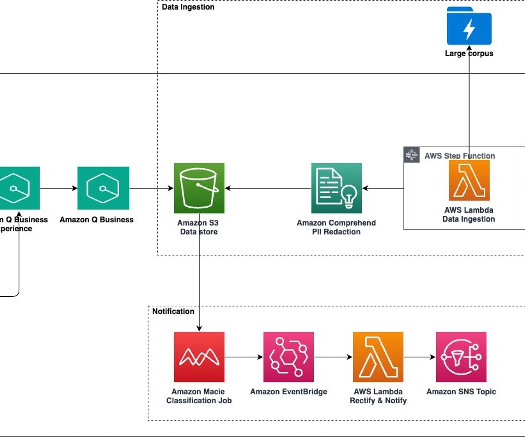
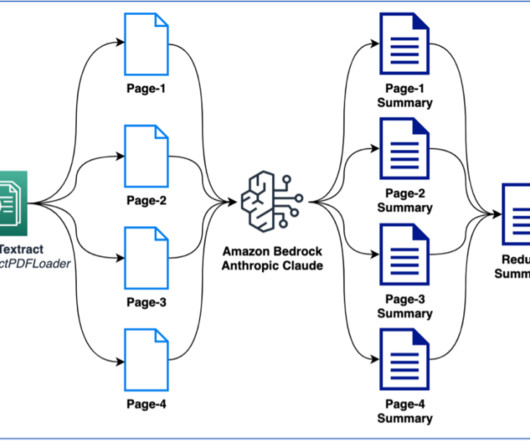
Large-scale data ingestion is crucial for applications such as document analysis, summarization, research, and knowledge management. These tasks often involve processing vast amounts of documents, which can be time-consuming and labor-intensive. Then we introduce the solution deployment using three AWS CloudFormation templates.
Traditional keyword-based search mechanisms are often insufficient for locating relevant documents efficiently, requiring extensive manual review to extract meaningful insights. This solution improves the findability and accessibility of archival records by automating metadata enrichment, document classification, and summarization.
Investment professionals face the mounting challenge of processing vast amounts of data to make timely, informed decisions. The traditional approach of manually sifting through countless research documents, industry reports, and financial statements is not only time-consuming but can also lead to missed opportunities and incomplete analysis.
By narrowing down the search space to the most relevant documents or chunks, metadata filtering reduces noise and irrelevant information, enabling the LLM to focus on the most relevant content. This approach narrows down the search space to the most relevant documents or passages, reducing noise and irrelevant information.
Precise), an Amazon Web Services (AWS) Partner , participated in the AWS Think Big for Small Business Program (TBSB) to expand their AWS capabilities and to grow their business in the public sector. The platform helped the agency digitize and process forms, pictures, and other documents.
Large language models (LLMs) have revolutionized the field of naturallanguageprocessing, enabling machines to understand and generate human-like text with remarkable accuracy. However, despite their impressive language capabilities, LLMs are inherently limited by the data they were trained on.
John Snow Labs’ Medical Language Models is by far the most widely used naturallanguageprocessing (NLP) library by practitioners in the healthcare space (Gradient Flow, The NLP Industry Survey 2022 and the Generative AI in Healthcare Survey 2024 ). You will be redirected to the listing on AWS Marketplace.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies and AWS. For example, imagine a consulting firm that manages documentation for multiple healthcare providerseach customers sensitive patient records and operational documents must remain strictly separated.
Research papers and engineering documents often contain a wealth of information in the form of mathematical formulas, charts, and graphs. Navigating these unstructured documents to find relevant information can be a tedious and time-consuming task, especially when dealing with large volumes of data.
In today’s data-driven business landscape, the ability to efficiently extract and process information from a wide range of documents is crucial for informed decision-making and maintaining a competitive edge.
This solution uses decorators in your application code to capture and log metadata such as input prompts, output results, run time, and custom metadata, offering enhanced security, ease of use, flexibility, and integration with native AWS services.
Using an Amazon Q Business custom data source connector , you can gain insights into your organizations third party applications with the integration of generative AI and naturallanguageprocessing. You must create and run the crawler that determines the documents your data source indexes.
AWS customers in healthcare, financial services, the public sector, and other industries store billions of documents as images or PDFs in Amazon Simple Storage Service (Amazon S3). In this post, we focus on processing a large collection of documents into raw text files and storing them in Amazon S3.
At AWS, we believe the long-term success of AI depends on the ability to inspire trust among users, customers, and society. Achieving ISO/IEC 42001 certification means that an independent third party has validated that AWS is taking proactive steps to manage risks and opportunities associated with AI development, deployment, and operation.
The learning program is typically designed for working professionals who want to learn about the advancing technological landscape of language models and learn to apply it to their work. It covers a range of topics including generative AI, LLM basics, naturallanguageprocessing, vector databases, prompt engineering, and much more.
It provides a common framework for assessing the performance of naturallanguageprocessing (NLP)-based retrieval models, making it straightforward to compare different approaches. You may be prompted to subscribe to this model through AWS Marketplace. On the AWS Marketplace listing , choose Continue to subscribe.
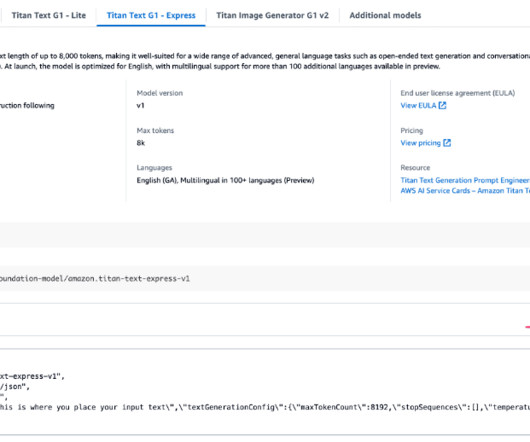
Tools like LangChain , combined with a large language model (LLM) powered by Amazon Bedrock or Amazon SageMaker JumpStart , simplify the implementation process. Click here to open the AWS console and follow along. To use one of these models, AWS offers the fully managed service Amazon Bedrock.
Most companies produce and consume unstructured data such as documents, emails, web pages, engagement center phone calls, and social media. In this post, we discuss how AWS can help you successfully address the challenges of extracting insights from unstructured data. Let’s understand how these AWS services are integrated in detail.
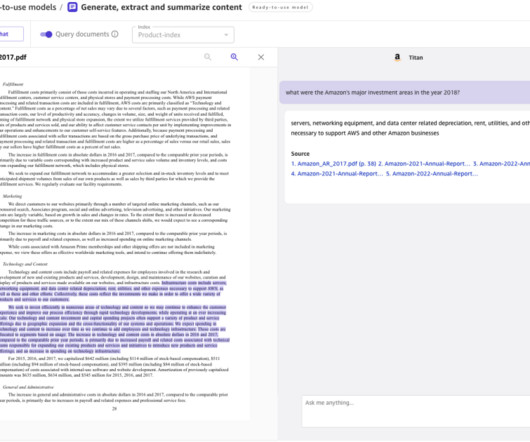
This post demonstrates how to seamlessly automate the deployment of an end-to-end RAG solution using Knowledge Bases for Amazon Bedrock and AWS CloudFormation , enabling organizations to quickly and effortlessly set up a powerful RAG system. An S3 bucket where your documents are stored in a supported format (.txt,md,html,doc/docx,csv,xls/.xlsx,pdf).
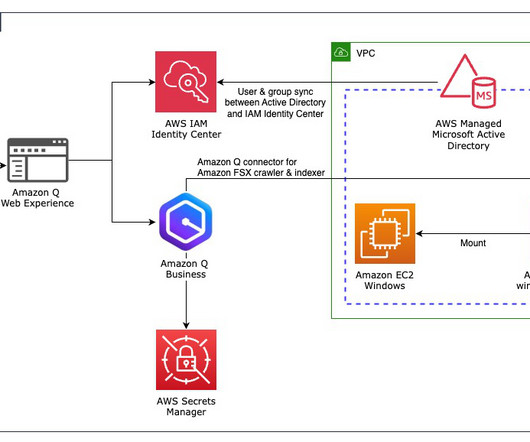
You can use Amazon FSx to lift and shift your on-premises Windows file server workloads to the cloud, taking advantage of the scalability, durability, and cost-effectiveness of AWS while maintaining full compatibility with your existing Windows applications and tooling. For a list of supported connectors, see Supported connectors.
Lets assume that the question What date will AWS re:invent 2024 occur? The corresponding answer is also input as AWS re:Invent 2024 takes place on December 26, 2024. If the question was Whats the schedule for AWS events in December?, This setup uses the AWS SDK for Python (Boto3) to interact with AWS services.
This arduous, time-consuming process is typically the first step in the grant management process, which is critical to driving meaningful social impact. The AWS Social Responsibility & Impact (SRI) team recognized an opportunity to augment this function using generative AI. Here are the steps to follow: 1.
The higher-level abstracted layer is designed for data scientists with limited AWS expertise, offering a simplified interface that hides complex infrastructure details. For the detailed list of pre-set values, refer to the SDK documentation. Admins and users can also overwrite the defaults using the SDK defaults configuration file.
The rise of large language models (LLMs) and foundation models (FMs) has revolutionized the field of naturallanguageprocessing (NLP) and artificial intelligence (AI). Development environment – Set up an integrated development environment (IDE) with your preferred coding language and tools.
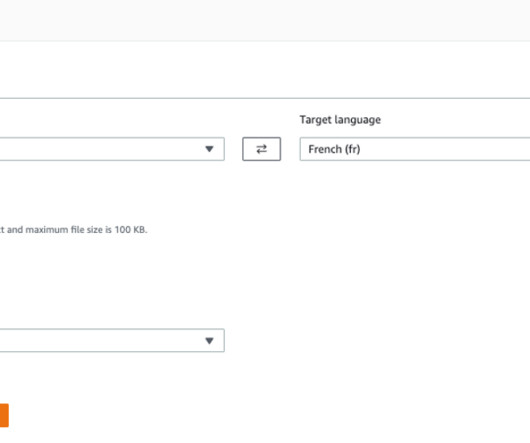
Now, Amazon Translate offers real-time document translation to seamlessly integrate and accelerate content creation and localization. This feature eliminates the wait for documents to be translated in asynchronous batch mode. This feature eliminates the wait for documents to be translated in asynchronous batch mode.
Intelligent documentprocessing , translation and summarization, flexible and insightful responses for customer support agents, personalized marketing content, and image and code generation are a few use cases using generative AI that organizations are rolling out in production.
Eight client teams collaborated with IBM® and AWS this spring to develop generative AI prototypes to address real-world business challenges in the public sector, financial services, energy, healthcare and other industries. The upfront enablement helped teams understand AWS technologies, then put that understanding into practice.
In today’s information age, the vast volumes of data housed in countless documents present both a challenge and an opportunity for businesses. Traditional documentprocessing methods often fall short in efficiency and accuracy, leaving room for innovation, cost-efficiency, and optimizations.
Prerequisites Before proceeding, make sure that you have the necessary AWS account permissions and services enabled, along with access to a ServiceNow environment with the required privileges for configuration. AWS Have an AWS account with administrative access. Each unit is 20,000 documents. Choose Create. Choose Next.
Legal professionals often spend a significant portion of their work searching through and analyzing large documents to draw insights, prepare arguments, create drafts, and compare documents. AWS AI and machine learning (ML) services help address these concerns within the industry.
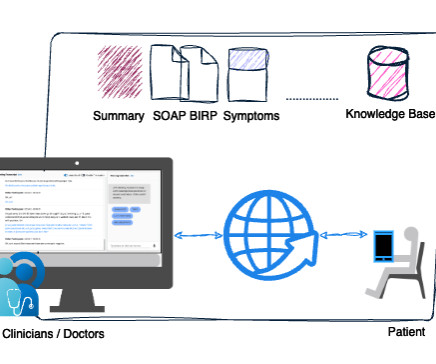
Today, physicians spend about 49% of their workday documenting clinical visits, which impacts physician productivity and patient care. By using the solution, clinicians don’t need to spend additional hours documenting patient encounters. What are the differences between AWS HealthScribe and the LMA for healthcare?
By automating document ingestion, chunking, and embedding, it eliminates the need to manually set up complex vector databases or custom retrieval systems, significantly reducing development complexity and time. The solution’s scalability quickly accommodates growing data volumes and user queries thanks to AWS serverless offerings.
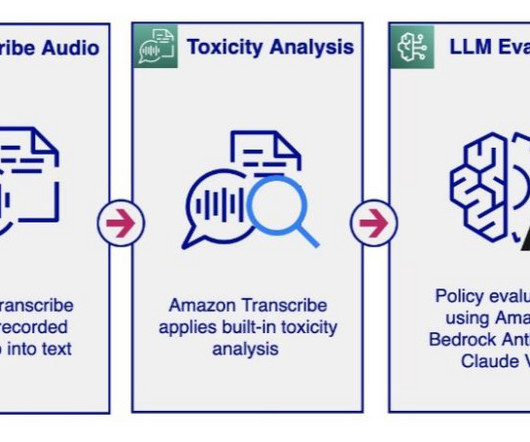
In this post, we introduce solutions that enable audio and text chat moderation using various AWS services, including Amazon Transcribe , Amazon Comprehend , Amazon Bedrock , and Amazon OpenSearch Service. OpenSearch Service is a fully managed service that makes it straightforward to deploy, scale, and operate OpenSearch in the AWS Cloud.
In this post, we explore how to deploy distilled versions of DeepSeek-R1 with Amazon Bedrock Custom Model Import, making them accessible to organizations looking to use state-of-the-art AI capabilities within the secure and scalable AWS infrastructure at an effective cost. You can monitor costs with AWS Cost Explorer.
Large Language Models (LLMs) have revolutionized the field of naturallanguageprocessing (NLP), improving tasks such as language translation, text summarization, and sentiment analysis. Through AWS Step Functions orchestration, the function calls Amazon Comprehend to detect the sentiment and toxicity.
Intelligent documentprocessing (IDP) with AWS helps automate information extraction from documents of different types and formats, quickly and with high accuracy, without the need for machine learning (ML) skills. For more information, refer to Intelligent documentprocessing with AWS AI services: Part 1.
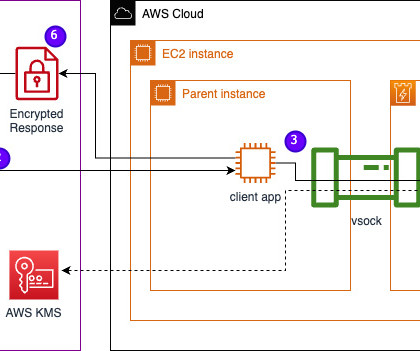
In this post, we discuss how Leidos worked with AWS to develop an approach to privacy-preserving large language model (LLM) inference using AWS Nitro Enclaves. Multi-factor authentication – A security process that requires users to provide multiple authentication methods to verify their identity to gain access to the LLM.
Since its introduction in 2021, Amazon SageMaker Canvas has enabled business analysts to build, deploy, and use a variety of ML models – including tabular, computer vision, and naturallanguageprocessing – without writing a line of code. We describe the set-up process in detail in Setting up Canvas to query documents.
Scalability and performance – The EMR Serverless integration automatically scales the compute resources up or down based on your workload’s demands, making sure you always have the necessary processing power to handle your big data tasks. This flexibility helps optimize performance and minimize the risk of bottlenecks or resource constraints.
There are several ways AWS is enabling ML practitioners to lower the environmental impact of their workloads. Inferentia and Trainium are AWS’s recent addition to its portfolio of purpose-built accelerators specifically designed by Amazon’s Annapurna Labs for ML inference and training workloads.
Measures Assistant is a microservice deployed in a Kubernetes on AWS environment and accessed through a REST API. Extracts of AEP documentation, describing each Measure type covered, its input and output types, and how to use it. The following diagram illustrates the solution architecture.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content