This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
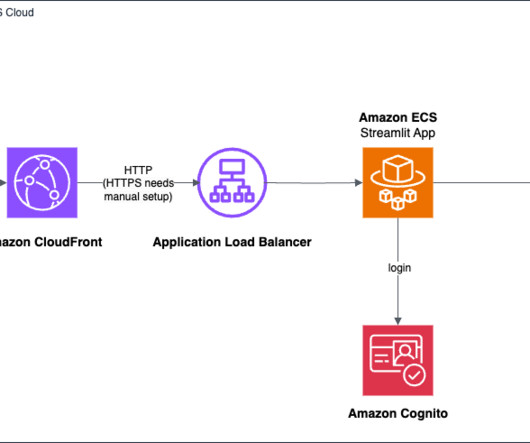
AWS provides a powerful set of tools and services that simplify the process of building and deploying generative AI applications, even for those with limited experience in frontend and backend development. The AWS deployment architecture makes sure the Python application is hosted and accessible from the internet to authenticated users.
To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023. In this blog post, we showcase how you can perform efficient supervised fine tuning for a Meta Llama 3 model using PEFT on AWS Trainium with SageMaker HyperPod. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
Prerequisites To implement the proposed solution, make sure that you have the following: An AWS account and a working knowledge of FMs, Amazon Bedrock , Amazon SageMaker , Amazon OpenSearch Service , Amazon S3 , and AWS Identity and Access Management (IAM). Amazon Titan Multimodal Embeddings model access in Amazon Bedrock.
It simplifies the often complex and time-consuming tasks involved in setting up and managing an MLflow environment, allowing ML administrators to quickly establish secure and scalable MLflow environments on AWS. For example, you can give users access permission to download popular packages and customize the development environment.
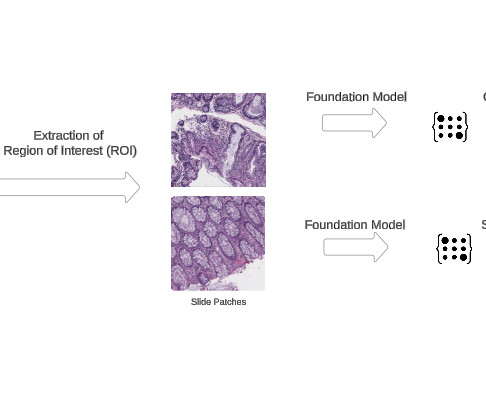
Solution overview Our solution uses the AWS integrated ecosystem to create an efficient scalable pipeline for digital pathology AI workflows. Prerequisites We assume you have access to and are authenticated in an AWS account. The AWS CloudFormation template for this solution uses t3.medium
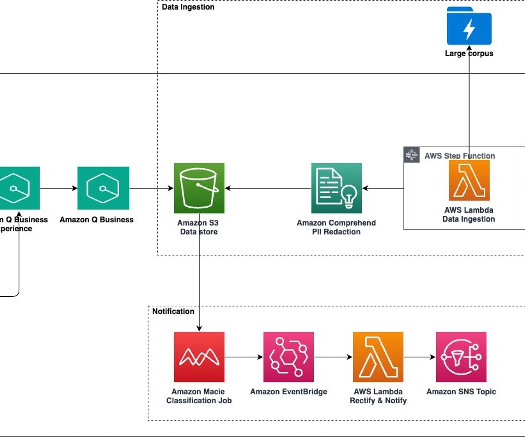
Earlier this year, we published the first in a series of posts about how AWS is transforming our seller and customer journeys using generative AI. Field Advisor serves four primary use cases: AWS-specific knowledge search With Amazon Q Business, weve made internal data sources as well as public AWS content available in Field Advisors index.
David Copland, from QARC, and Scott Harding, a person living with aphasia, used AWS services to develop WordFinder, a mobile, cloud-based solution that helps individuals with aphasia increase their independence through the use of AWS generative AI technology. The following diagram illustrates the solution architecture on AWS.
Introduction S3 is Amazon Web Services cloud-based object storage service (AWS). S3 provides a simple web interface for uploading and downloading data and a powerful set of APIs for developers to integrate S3. S3 […] The post Top 6 Amazon S3 Interview Questions appeared first on Analytics Vidhya.
Using vLLM on AWS Trainium and Inferentia makes it possible to host LLMs for high performance inference and scalability. Deploy vLLM on AWS Trainium and Inferentia EC2 instances In these sections, you will be guided through using vLLM on an AWS Inferentia EC2 instance to deploy Meta’s newest Llama 3.2 You will use inf2.xlarge
Enhancing AWS Support Engineering efficiency The AWS Support Engineering team faced the daunting task of manually sifting through numerous tools, internal sources, and AWS public documentation to find solutions for customer inquiries. Then we introduce the solution deployment using three AWS CloudFormation templates.
Prerequisites To perform this solution, complete the following: Create and activate an AWS account. Make sure your AWS credentials are configured correctly. This tutorial assumes you have the necessary AWS Identity and Access Management (IAM) permissions. For this walkthrough, we will use the AWS CLI to trigger the processing.
Hybrid architecture with AWS Local Zones To minimize the impact of network latency on TTFT for users regardless of their locations, a hybrid architecture can be implemented by extending AWS services from commercial Regions to edge locations closer to end users. Next, create a subnet inside each Local Zone. Amazon Linux 2).
SageMaker Unified Studio combines various AWS services, including Amazon Bedrock , Amazon SageMaker , Amazon Redshift , Amazon Glue , Amazon Athena , and Amazon Managed Workflows for Apache Airflow (MWAA) , into a comprehensive data and AI development platform. Navigate to the AWS Secrets Manager console and find the secret -api-keys.
Global Resiliency is a new Amazon Lex capability that enables near real-time replication of your Amazon Lex V2 bots in a second AWS Region. Additionally, we discuss how to handle integrations with AWS Lambda and Amazon CloudWatch after enabling Global Resiliency. We walk through the instructions to replicate the bot later in this post.
In this post, we explore how to deploy distilled versions of DeepSeek-R1 with Amazon Bedrock Custom Model Import, making them accessible to organizations looking to use state-of-the-art AI capabilities within the secure and scalable AWS infrastructure at an effective cost. You can monitor costs with AWS Cost Explorer.
Introduction This article shows how to monitor a model deployed on AWS Sagemaker for quality, bias and explainability, using IBM Watson OpenScale on the IBM Cloud Pak for Data platform. This article shows how to use the endpoint generated from that tutorial to demonstrate how to monitor the AWS deployment with Watson OpenScale.
Today at AWS re:Invent 2024, we are excited to announce the new Container Caching capability in Amazon SageMaker, which significantly reduces the time required to scale generative AI models for inference. Container Caching addresses this scaling challenge by pre-caching the container image, eliminating the need to download it when scaling up.
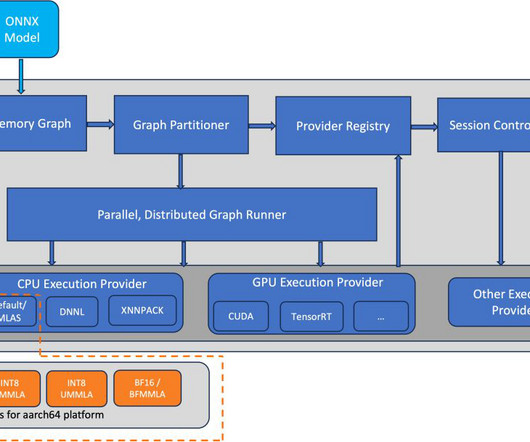
AWS Graviton3 processors are optimized for ML workloads, including support for bfloat16, Scalable Vector Extension (SVE), and Matrix Multiplication (MMLA) instructions. In this post, we show how to run ONNX Runtime inference on AWS Graviton3-based EC2 instances and how to configure them to use optimized GEMM kernels.
Today, we’re excited to announce the availability of Meta Llama 3 inference on AWS Trainium and AWS Inferentia based instances in Amazon SageMaker JumpStart. In this post, we demonstrate how easy it is to deploy Llama 3 on AWS Trainium and AWS Inferentia based instances in SageMaker JumpStart.
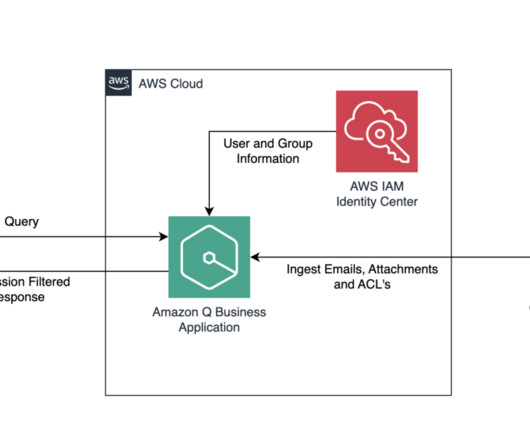
Amazon Q Business uses AWS IAM Identity Center to record the workforce users you assign access to and their attributes, such as group associations. IAM Identity Center is used by many AWS managed applications such as Amazon Q. Why use trusted identity propagation? Promotes software design principles rooted in user privacy.
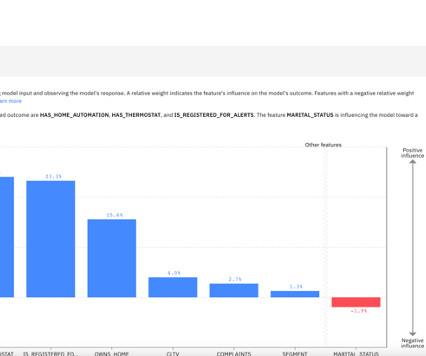
You can then export the model and deploy it on Amazon Sagemaker on Amazon Web Server (AWS). If you are set up with the required systems, you can download the sample project and complete the steps for hands-on learning. The example model predicts how likely a customer is to enroll in a Demand Response Program of a Utilities Company.
Prerequisites Make sure you meet the following prerequisites: Make sure your SageMaker AWS Identity and Access Management (IAM) role has the AmazonSageMakerFullAccess permission policy attached. You may be prompted to subscribe to this model through AWS Marketplace. On the AWS Marketplace listing , choose Continue to subscribe.
Solution overview The NER & LLM Gen AI Application is a document processing solution built on AWS that combines NER and LLMs to automate document analysis at scale. Click here to open the AWS console and follow along. The endpoint lifecycle is orchestrated through dedicated AWS Lambda functions that handle creation and deletion.
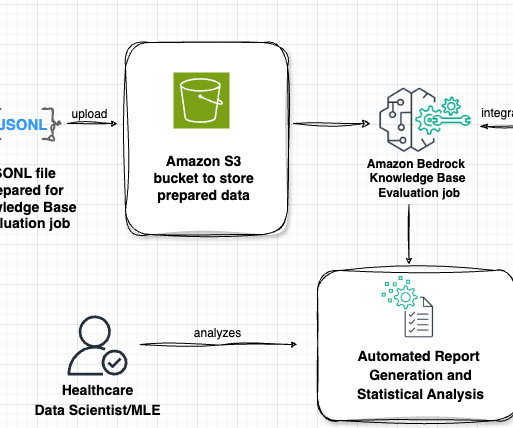
Because we used only the radiology report text data, we downloaded just one compressed report file (mimic-cxr-reports.zip) from the MIMIC-CXR website. Data ScientistGenerative AI, Amazon Bedrock, where he contributes to cutting edge innovations in foundational models and generative AI applications at AWS.
For AWS and Outerbounds customers, the goal is to build a differentiated machine learning and artificial intelligence (ML/AI) system and reliably improve it over time. First, the AWS Trainium accelerator provides a high-performance, cost-effective, and readily available solution for training and fine-tuning large models.
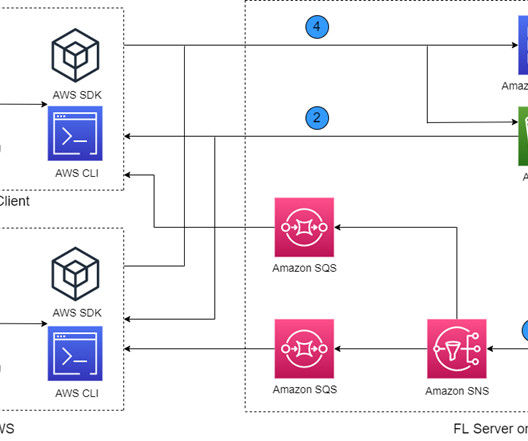
Customers often need to train a model with data from different regions, organizations, or AWS accounts. Existing partner open-source FL solutions on AWS include FedML and NVIDIA FLARE. These open-source packages are deployed in the cloud by running in virtual machines, without using the cloud-native services available on AWS.
In this post, we walk through how to fine-tune Llama 2 on AWS Trainium , a purpose-built accelerator for LLM training, to reduce training times and costs. We review the fine-tuning scripts provided by the AWS Neuron SDK (using NeMo Megatron-LM), the various configurations we used, and the throughput results we saw.
Prerequisites Before you begin, make sure you have the following prerequisites in place: An AWS account and role with the AWS Identity and Access Management (IAM) privileges to deploy the following resources: IAM roles. Open the AWS Management Console, go to Amazon Bedrock, and choose Model access in the navigation pane.
Managing your Amazon Lex bots using AWS CloudFormation allows you to create templates defining the bot and all the AWS resources it depends on. AWS CloudFormation provides and configures those resources on your behalf, removing the risk of human error when deploying bots to new environments. Resources: # 1.
AWS optimized the PyTorch torch.compile feature for AWS Graviton3 processors. the optimizations are available in torch Python wheels and AWS Graviton PyTorch deep learning container (DLC). The goal for the AWS Graviton team was to optimize torch.compile backend for Graviton3 processors. Starting with PyTorch 2.3.1,
In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience. Run the AWS Glue ML transform job.
In this post, we explore how you can use Amazon Q Business , the AWS generative AI-powered assistant, to build a centralized knowledge base for your organization, unifying structured and unstructured datasets from different sources to accelerate decision-making and drive productivity. In this post, we use IAM Identity Center as the SAML 2.0-aligned
In this post, we’ll summarize training procedure of GPT NeoX on AWS Trainium , a purpose-built machine learning (ML) accelerator optimized for deep learning training. M tokens/$) trained such models with AWS Trainium without losing any model quality. We’ll outline how we cost-effectively (3.2 billion in Pythia.
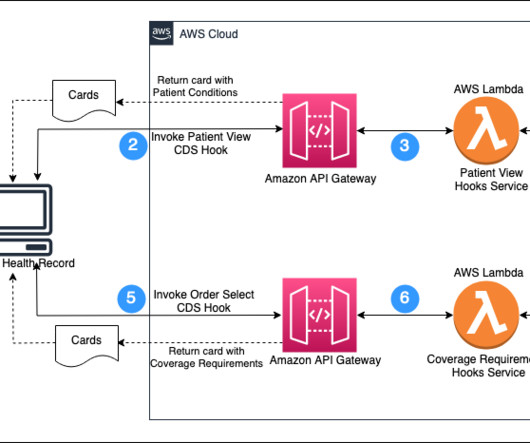
Documentation Templates and Rules (DTR) – This allows providers to download smart questionnaires and rules, such as Clinical Quality Language (CQL), and provides a SMART on FHIR app or EHR app that runs the questionnaires and rules to gather information relevant to a performed or planned service.
This feature eliminates one of the major bottlenecks in deployment scaling by pre-caching container images, removing the need for time-consuming downloads when adding new instances. Prior to joining AWS, Dr. Li held data science roles in the financial and retail industries. Adriana Simmons is a Senior Product Marketing Manager at AWS.
We demonstrate how to build an end-to-end RAG application using Cohere’s language models through Amazon Bedrock and a Weaviate vector database on AWS Marketplace. Additionally, you can securely integrate and easily deploy your generative AI applications using the AWS tools you are already familiar with.
AWS, Arm, Meta and others helped optimize the performance of PyTorch 2.0 As a result, we are delighted to announce that AWS Graviton-based instance inference performance for PyTorch 2.0 times the speed for BERT, making Graviton-based instances the fastest compute optimized instances on AWS for these models. is up to 3.5
The web application that the user uses to retrieve answers is connected to an identity provider (IdP) or AWS IAM Identity Center. If you haven’t created one yet, refer to Build private and secure enterprise generative AI apps with Amazon Q Business and AWS IAM Identity Center for instructions. Access to AWS Secrets Manager.
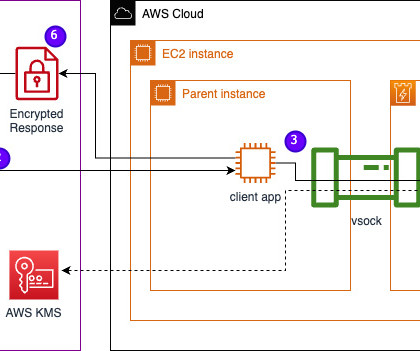
In this post, we discuss how Leidos worked with AWS to develop an approach to privacy-preserving large language model (LLM) inference using AWS Nitro Enclaves. The steps carried out during the inference are as follows: The chatbot app generates temporary AWS credentials and asks the user to input a question. hvm-2.0.20230628.0-x86_64-gp2
Llama2 by Meta is an example of an LLM offered by AWS. To learn more about Llama 2 on AWS, refer to Llama 2 foundation models from Meta are now available in Amazon SageMaker JumpStart. Virginia) and US West (Oregon) AWS Regions, and most recently announced general availability in the US East (Ohio) Region.
Today, we’re excited to announce the availability of Llama 2 inference and fine-tuning support on AWS Trainium and AWS Inferentia instances in Amazon SageMaker JumpStart. In this post, we demonstrate how to deploy and fine-tune Llama 2 on Trainium and AWS Inferentia instances in SageMaker JumpStart.
Additionally, you can use AWS Lambda directly to expose your models and deploy your ML applications using your preferred open-source framework, which can prove to be more flexible and cost-effective. We also show you how to automate the deployment using the AWS Cloud Development Kit (AWS CDK). Now, let’s set up the environment.
AWS Lambda AWS Lambda is a compute service that runs code in response to triggers such as changes in data, changes in application state, or user actions. Prerequisites If youre new to AWS, you first need to create and set up an AWS account. We download the documents and store them under a samples folder locally.
Today at AWS re:Invent 2024, we are excited to announce a new feature for Amazon SageMaker inference endpoints: the ability to scale SageMaker inference endpoints to zero instances. This long-awaited capability is a game changer for our customers using the power of AI and machine learning (ML) inference in the cloud.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content