This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With access to a wide range of generative AI foundation models (FM) and the ability to build and train their own machine learning (ML) models in Amazon SageMaker , users want a seamless and secure way to experiment with and select the models that deliver the most value for their business.
To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023. In this blog post, we showcase how you can perform efficient supervised fine tuning for a Meta Llama 3 model using PEFT on AWS Trainium with SageMaker HyperPod. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
Prerequisites To implement the proposed solution, make sure that you have the following: An AWS account and a working knowledge of FMs, Amazon Bedrock , Amazon SageMaker , Amazon OpenSearch Service , Amazon S3 , and AWS Identity and Access Management (IAM). Amazon Titan Multimodal Embeddings model access in Amazon Bedrock.
Solution overview Our solution uses the AWS integrated ecosystem to create an efficient scalable pipeline for digital pathology AI workflows. Prerequisites We assume you have access to and are authenticated in an AWS account. The AWS CloudFormation template for this solution uses t3.medium
Enhancing AWS Support Engineering efficiency The AWS Support Engineering team faced the daunting task of manually sifting through numerous tools, internal sources, and AWS public documentation to find solutions for customer inquiries. Then we introduce the solution deployment using three AWS CloudFormation templates.
Amazon SageMaker supports geospatial machine learning (ML) capabilities, allowing data scientists and ML engineers to build, train, and deploy ML models using geospatial data. SageMaker Processing provisions cluster resources for you to run city-, country-, or continent-scale geospatial ML workloads.
This post is co-authored by Manuel Lopez Roldan, SiMa.ai, and Jason Westra, AWS Senior Solutions Architect. Are you looking to deploy machine learning (ML) models at the edge? Edgematic with SageMaker JupyterLab to deploy an ML model, YOLOv7 , to the edge. If you dont have an AWS account, you can create one.
Machine learning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. Let’s learn about the services we will use to make this happen.
Using vLLM on AWS Trainium and Inferentia makes it possible to host LLMs for high performance inference and scalability. Deploy vLLM on AWS Trainium and Inferentia EC2 instances In these sections, you will be guided through using vLLM on an AWS Inferentia EC2 instance to deploy Meta’s newest Llama 3.2 You will use inf2.xlarge
Getting started with SageMaker JumpStart SageMaker JumpStart is a machine learning (ML) hub that can help accelerate your ML journey. This feature eliminates one of the major bottlenecks in deployment scaling by pre-caching container images, removing the need for time-consuming downloads when adding new instances.
To address this need, AWS generative AI best practices framework was launched within AWS Audit Manager , enabling auditing and monitoring of generative AI applications. Figure 1 depicts the systems functionalities and AWS services. Select AWS Generative AI Best Practices Framework for assessment. Choose Create assessment.
Building generative AI applications presents significant challenges for organizations: they require specialized ML expertise, complex infrastructure management, and careful orchestration of multiple services. You can obtain the SageMaker Unified Studio URL for your domains by accessing the AWS Management Console for Amazon DataZone.
Today at AWS re:Invent 2024, we are excited to announce the new Container Caching capability in Amazon SageMaker, which significantly reduces the time required to scale generative AI models for inference. Container Caching addresses this scaling challenge by pre-caching the container image, eliminating the need to download it when scaling up.
Amazon SageMaker AI provides a fully managed service for deploying these machine learning (ML) models with multiple inference options, allowing organizations to optimize for cost, latency, and throughput. AWS has always provided customers with choice. That includes model choice, hardware choice, and tooling choice.
To address these challenges, AWS has expanded Amazon SageMaker with a comprehensive set of data, analytics, and generative AI capabilities. SageMaker AI is a fully managed service to build, train, and deploy ML models—including FMs—for different use cases by bringing together a broad set of tools to enable high-performance, low-cost ML.
Today at AWS re:Invent 2024, we are excited to announce a new feature for Amazon SageMaker inference endpoints: the ability to scale SageMaker inference endpoints to zero instances. This long-awaited capability is a game changer for our customers using the power of AI and machine learning (ML) inference in the cloud.
These models are now seamlessly integrated into Amazon Web Services (AWS) services, unlocking powerful deployment options for developers and enterprises. set up the AWS account : Create an AWS account. For more details, refer to the Mistral Model Deployments on AWS section later in this post.) Use the following steps.To
You can chat with your structured data by setting up structured data ingestion from AWS Glue Data Catalog tables and Amazon Redshift clusters in a few steps, using the power of Amazon Bedrock Knowledge Bases structured data retrieval. In this post, we discuss a common data ingestion use case using Amazon S3, AWS Glue, and Amazon Redshift.
We demonstrate this solution by walking you through a comprehensive step-by-step guide on how to fine-tune YOLOv8 , a real-time object detection model, on Amazon Web Services (AWS) using a custom dataset. An AWS account. Install AWS Command Line Interface (AWS CLI) and use aws configure to set up your IAM credentials securely.
AWS recently announced the general availability of Amazon Bedrock Data Automation , a feature of Amazon Bedrock that automates the generation of valuable insights from unstructured multimodal content such as documents, images, video, and audio. Amazon Bedrock Data Automation serves as the primary engine for information extraction.
Creating professional AWS architecture diagrams is a fundamental task for solutions architects, developers, and technical teams. By using generative AI through natural language prompts, architects can now generate professional diagrams in minutes rather than hours, while adhering to AWS best practices.
Amazon SageMaker is a comprehensive, fully managed machine learning (ML) platform that revolutionizes the entire ML workflow. It offers an unparalleled suite of tools that cater to every stage of the ML lifecycle, from data preparation to model deployment and monitoring. If so, skip to the next section in this post.
DGX Cloud on Amazon Web Services (AWS) represents a significant leap forward in democratizing access to high-performance AI infrastructure. By combining NVIDIA GPU expertise with AWS scalable cloud services, organizations can accelerate their time-to-train, reduce operational complexity, and unlock new business opportunities.
Global Resiliency is a new Amazon Lex capability that enables near real-time replication of your Amazon Lex V2 bots in a second AWS Region. Additionally, we discuss how to handle integrations with AWS Lambda and Amazon CloudWatch after enabling Global Resiliency. We walk through the instructions to replicate the bot later in this post.
For example, marketing and software as a service (SaaS) companies can personalize artificial intelligence and machine learning (AI/ML) applications using each of their customer’s images, art style, communication style, and documents to create campaigns and artifacts that represent them. For details, refer to Create an AWS account.
Today at AWS re:Invent 2024, we are excited to announce a new capability in Amazon SageMaker Inference that significantly reduces the time required to deploy and scale LLMs for inference using LMI: Fast Model Loader. To reduce the time it takes to download and load the container image, SageMaker now supports container caching.
The integrated approach and ease of use of Amazon Bedrock in deploying large language models (LLMs), along with built-in features that facilitate seamless integration with other AWS services like Amazon Kendra, made it the preferred choice. This workflow integrates AWS services to extract, process, and make content available for querying.
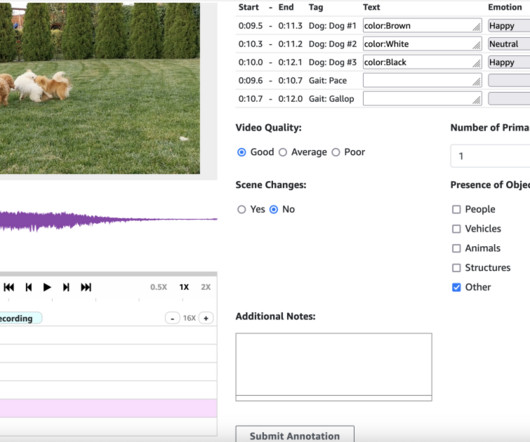
We guide you through deploying the necessary infrastructure using AWS CloudFormation , creating an internal labeling workforce, and setting up your first labeling job. Solution overview This audio/video segmentation solution combines several AWS services to create a robust annotation workflow. We demonstrate how to use Wavesurfer.js
Implementation details We spin up the cluster by calling the SageMaker control plane through APIs or the AWS Command Line Interface (AWS CLI) or using the SageMaker AWS SDK. To request a service quota increase, on the AWS Service Quotas console , navigate to AWS services , Amazon SageMaker , and choose ml.p4d.24xlarge
However, the rise of intelligent document processing (IDP), which uses the power of artificial intelligence and machine learning (AI/ML) to automate the extraction, classification, and analysis of data from various document types is transforming the game. The Amazon S3 upload triggers an AWS Lambda function execution.
Solution overview The NER & LLM Gen AI Application is a document processing solution built on AWS that combines NER and LLMs to automate document analysis at scale. Click here to open the AWS console and follow along. The endpoint lifecycle is orchestrated through dedicated AWS Lambda functions that handle creation and deletion.
In the context of enterprise data asset search powered by a metadata catalog hosted on services such Amazon DataZone, AWS Glue, and other third-party catalogs, knowledge graphs can help integrate this linked data and also enable a scalable search paradigm that integrates metadata that evolves over time.
Fortunately, AWS uses powerful AI/ML applications within Amazon SageMaker AI that can address these needs. Key concepts In this section, we discuss some key concepts of spacecraft dynamics and machine learning (ML) in this solution. Results The script generates plots for positions, velocities, and quaternions.
To achieve these goals, the AWS Well-Architected Framework provides comprehensive guidance for building and improving cloud architectures. This allows teams to focus more on implementing improvements and optimizing AWS infrastructure. This systematic approach leads to more reliable and standardized evaluations.
These recipes include a training stack validated by Amazon Web Services (AWS) , which removes the tedious work of experimenting with different model configurations, minimizing the time it takes for iterative evaluation and testing. All of this runs under the SageMaker managed environment, providing optimal resource utilization and security.
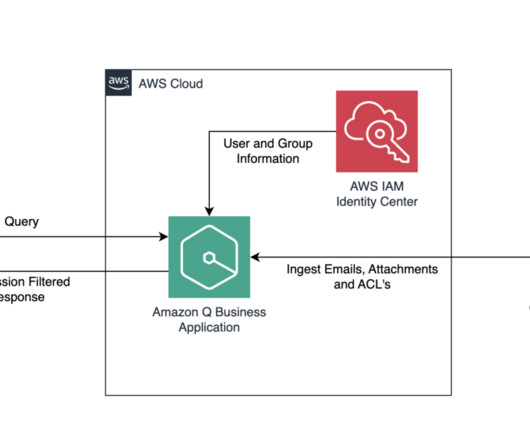
The web application that the user uses to retrieve answers is connected to an identity provider (IdP) or AWS IAM Identity Center. If you haven’t created one yet, refer to Build private and secure enterprise generative AI apps with Amazon Q Business and AWS IAM Identity Center for instructions. Access to AWS Secrets Manager.
GraphStorm is a low-code enterprise graph machine learning (ML) framework that provides ML practitioners a simple way of building, training, and deploying graph ML solutions on industry-scale graph data. Today, AWS AI released GraphStorm v0.4. This dataset has approximately 170,000 nodes and 1.2 million edges.
This fragmentation can complicate efforts by organizations to consolidate and analyze data for their machine learning (ML) initiatives. This minimizes the complexity and overhead associated with moving data between cloud environments, enabling organizations to access and utilize their disparate data assets for ML projects.
To configure the labeling job using the AWS Management Console , complete the following steps: On the SageMaker AI console, under Ground Truth in the navigation pane, choose Labeling job. Use the AWS CLI for command-line interactions. Jesse Manders is a Senior Product Manager on Amazon Bedrock, the AWS Generative AI developer service.
This post explores a solution that uses the power of AWS generative AI capabilities like Amazon Bedrock and OpenSearch vector search to perform damage appraisals for insurers, repair shops, and fleet managers. Download the dataset from the public dataset repository. Specific instructions can be found on the AWS Samples repository.
In this post, we explore how to deploy distilled versions of DeepSeek-R1 with Amazon Bedrock Custom Model Import, making them accessible to organizations looking to use state-of-the-art AI capabilities within the secure and scalable AWS infrastructure at an effective cost. You can monitor costs with AWS Cost Explorer.
Because we used only the radiology report text data, we downloaded just one compressed report file (mimic-cxr-reports.zip) from the MIMIC-CXR website. Data ScientistGenerative AI, Amazon Bedrock, where he contributes to cutting edge innovations in foundational models and generative AI applications at AWS.
Prerequisites To build the solution yourself, there are the following prerequisites: You need an AWS account with an AWS Identity and Access Management (IAM) role that has permissions to manage resources created as part of the solution (for example AmazonSageMakerFullAccess and AmazonS3FullAccess ).
Virginia) AWS Region. Prerequisites To try the Llama 4 models in SageMaker JumpStart, you need the following prerequisites: An AWS account that will contain all your AWS resources. An AWS Identity and Access Management (IAM) role to access SageMaker AI. b64encode(img).decode('utf-8') b64encode(response.content).decode('utf-8')
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content