This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As organizations look to incorporate AI capabilities into their applications, large language models (LLMs) have emerged as powerful tools for naturallanguageprocessing tasks. AWS has always provided customers with choice. That includes model choice, hardware choice, and tooling choice. The build_and_push.sh
Home Table of Contents Build a Search Engine: Setting Up AWS OpenSearch Introduction What Is AWS OpenSearch? What AWS OpenSearch Is Commonly Used For Key Features of AWS OpenSearch How Does AWS OpenSearch Work? Why Use AWS OpenSearch for Semantic Search? Looking for the source code to this post?
Enhancing AWS Support Engineering efficiency The AWS Support Engineering team faced the daunting task of manually sifting through numerous tools, internal sources, and AWS public documentation to find solutions for customer inquiries. Then we introduce the solution deployment using three AWS CloudFormation templates.
The integrated approach and ease of use of Amazon Bedrock in deploying large language models (LLMs), along with built-in features that facilitate seamless integration with other AWS services like Amazon Kendra, made it the preferred choice. By using Claude 3’s vision capabilities, we could upload image-rich PDF documents.
Global Resiliency is a new Amazon Lex capability that enables near real-time replication of your Amazon Lex V2 bots in a second AWS Region. We showcase the replication process of bot versions and aliases across multiple Regions. Solution overview For this exercise, we create a BookHotel bot as our sample bot.
In this post, we explore how to deploy distilled versions of DeepSeek-R1 with Amazon Bedrock Custom Model Import, making them accessible to organizations looking to use state-of-the-art AI capabilities within the secure and scalable AWS infrastructure at an effective cost. You can monitor costs with AWS Cost Explorer.
We demonstrate this solution by walking you through a comprehensive step-by-step guide on how to fine-tune YOLOv8 , a real-time object detection model, on Amazon Web Services (AWS) using a custom dataset. The process uses a single ml.g5.2xlarge instance (providing one NVIDIA A10G Tensor Core GPU) with SageMaker for fine-tuning.
The integration of modern naturallanguageprocessing (NLP) and LLM technologies enhances metadata accuracy, enabling more precise search functionality and streamlined document management. In this post, we discuss how you can build an AI-powered document processing platform with open source NER and LLMs on SageMaker.
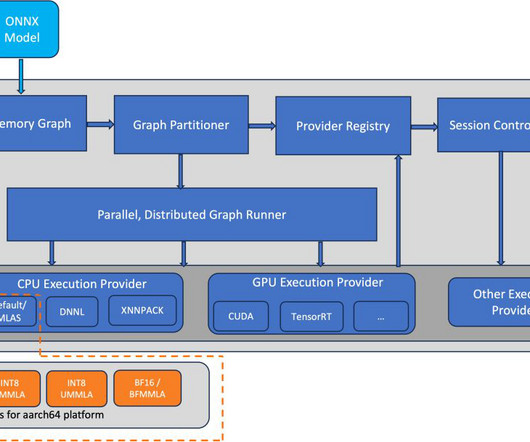
AWS Graviton3 processors are optimized for ML workloads, including support for bfloat16, Scalable Vector Extension (SVE), and Matrix Multiplication (MMLA) instructions. In this post, we show how to run ONNX Runtime inference on AWS Graviton3-based EC2 instances and how to configure them to use optimized GEMM kernels.
AWS optimized the PyTorch torch.compile feature for AWS Graviton3 processors. the optimizations are available in torch Python wheels and AWS Graviton PyTorch deep learning container (DLC). The goal for the AWS Graviton team was to optimize torch.compile backend for Graviton3 processors. Starting with PyTorch 2.3.1,
It provides a common framework for assessing the performance of naturallanguageprocessing (NLP)-based retrieval models, making it straightforward to compare different approaches. You may be prompted to subscribe to this model through AWS Marketplace. On the AWS Marketplace listing , choose Continue to subscribe.
In this post, we walk through how to fine-tune Llama 2 on AWS Trainium , a purpose-built accelerator for LLM training, to reduce training times and costs. We review the fine-tuning scripts provided by the AWS Neuron SDK (using NeMo Megatron-LM), the various configurations we used, and the throughput results we saw.
Historically, naturallanguageprocessing (NLP) would be a primary research and development expense. In 2024, however, organizations are using large language models (LLMs), which require relatively little focus on NLP, shifting research and development from modeling to the infrastructure needed to support LLM workflows.
AWS Lambda AWS Lambda is a compute service that runs code in response to triggers such as changes in data, changes in application state, or user actions. Prerequisites If youre new to AWS, you first need to create and set up an AWS account. We download the documents and store them under a samples folder locally.
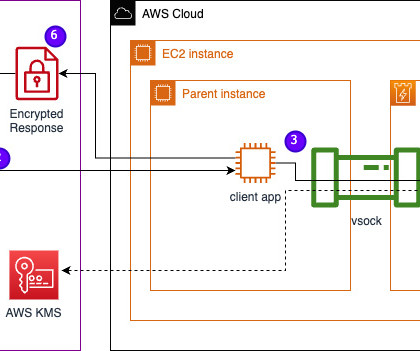
In this post, we discuss how Leidos worked with AWS to develop an approach to privacy-preserving large language model (LLM) inference using AWS Nitro Enclaves. LLMs are designed to understand and generate human-like language, and are used in many industries, including government, healthcare, financial, and intellectual property.
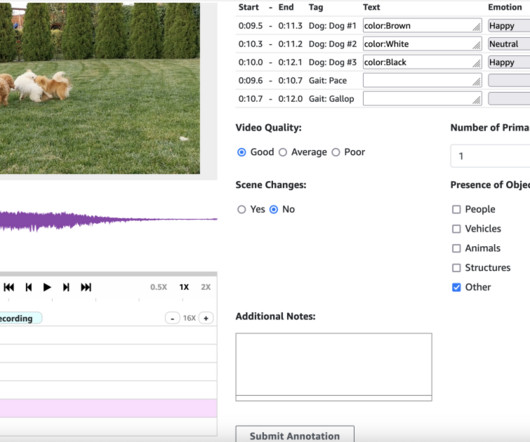
We guide you through deploying the necessary infrastructure using AWS CloudFormation , creating an internal labeling workforce, and setting up your first labeling job. This precision helps models learn the fine details that separate natural from artificial-sounding speech. We demonstrate how to use Wavesurfer.js
Sprinklr’s specialized AI models streamline data processing, gather valuable insights, and enable workflows and analytics at scale to drive better decision-making and productivity. During this journey, we collaborated with our AWS technical account manager and the Graviton software engineering teams.
We demonstrate how to build an end-to-end RAG application using Cohere’s language models through Amazon Bedrock and a Weaviate vector database on AWS Marketplace. Additionally, you can securely integrate and easily deploy your generative AI applications using the AWS tools you are already familiar with.
Llama2 by Meta is an example of an LLM offered by AWS. Llama 2 is an auto-regressive language model that uses an optimized transformer architecture and is intended for commercial and research use in English. Virginia) and US West (Oregon) AWS Regions, and most recently announced general availability in the US East (Ohio) Region.
Additionally, you can use AWS Lambda directly to expose your models and deploy your ML applications using your preferred open-source framework, which can prove to be more flexible and cost-effective. We also show you how to automate the deployment using the AWS Cloud Development Kit (AWS CDK). Now, let’s set up the environment.
Today, we’re excited to announce the availability of Llama 2 inference and fine-tuning support on AWS Trainium and AWS Inferentia instances in Amazon SageMaker JumpStart. In this post, we demonstrate how to deploy and fine-tune Llama 2 on Trainium and AWS Inferentia instances in SageMaker JumpStart.
AWS has been innovating with purpose-built chips to address the growing need for powerful, efficient, and cost-effective compute hardware. You can use ml.trn1 and ml.inf2 compatible AWS Deep Learning Containers (DLCs) for PyTorch, TensorFlow, Hugging Face, and large model inference (LMI) to easily get started. petaflops for BF16/FP16.
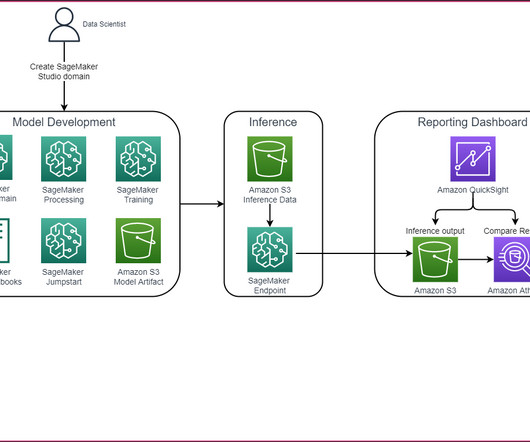
Implementation details We spin up the cluster by calling the SageMaker control plane through APIs or the AWS Command Line Interface (AWS CLI) or using the SageMaker AWS SDK. To request a service quota increase, on the AWS Service Quotas console , navigate to AWS services , Amazon SageMaker , and choose ml.p4d.24xlarge
Genomic language models are a new and exciting field in the application of large language models to challenges in genomics. In this blog post and open source project , we show you how you can pre-train a genomics language model, HyenaDNA , using your genomic data in the AWS Cloud.
Amazon Comprehend is a fully, managed service that uses naturallanguageprocessing (NLP) to extract insights about the content of documents. In this post, we use Amazon Comprehend and other AWS services to analyze and extract new insights from a repository of documents. In this example, we use text formatted files.
By integrating this model with Amazon SageMaker AI , you can benefit from the AWS scalable infrastructure while maintaining high-quality language model capabilities. Solution overview You can use DeepSeeks distilled models within the AWS managed machine learning (ML) infrastructure. For details, refer to Create an AWS account.
Retailers can deliver more frictionless experiences on the go with naturallanguageprocessing (NLP), real-time recommendation systems, and fraud detection. In this post, we demonstrate how to deploy a SageMaker model to AWS Wavelength to reduce model inference latency for 5G network-based applications.
PyTorch is a machine learning (ML) framework that is widely used by AWS customers for a variety of applications, such as computer vision, naturallanguageprocessing, content creation, and more. release, AWS customers can now do same things as they could with PyTorch 1.x 24xlarge with AWS PyTorch 2.0
The proposed solution in this post uses fine-tuning of pre-trained large language models (LLMs) to help generate summarizations based on findings in radiology reports. This post demonstrates a strategy for fine-tuning publicly available LLMs for the task of radiology report summarization using AWS services.
Large language models (LLMs) have revolutionized the field of naturallanguageprocessing with their ability to understand and generate humanlike text. For details, refer to Creating an AWS account. Be sure to set up your AWS Command Line Interface (AWS CLI) credentials correctly.
Prerequisites The example solution in this post uses datasets from the following websites: Amazon Press Center archive Amazon Investor relations quarterly reports Also, you need to: Create an S3 bucket to store the files on AWS. Download and upload the PDF and XLS files from the websites into the S3 bucket. Choose Create notebook.
HF_TOKEN : This parameter variable provides the access token required to download gated models from the Hugging Face Hub, such as Llama or Mistral. Model Base Model Download DeepSeek-R1-Distill-Qwen-1.5B Model Base Model Download DeepSeek-R1-Distill-Qwen-1.5B GenAI Data Scientist at AWS. meta-llama/Llama-3.2-11B-Vision-Instruct
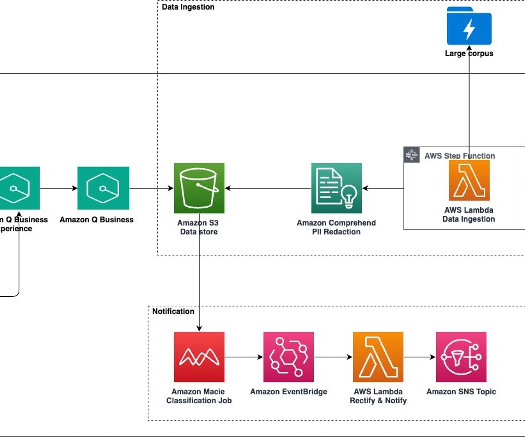
With the Amazon Bedrock serverless experience, you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using the AWS tools without having to manage any infrastructure. To implement this architecture, we take advantage of AWS Step Functions to build the overall workflow.
Prerequisites To implement the solution, complete the following prerequisite steps: Have an active AWS account. Create an AWS Identity and Access Management (IAM) role for the Lambda function to access Amazon Bedrock and documents from Amazon S3. For instructions, refer to Create a role to delegate permissions to an AWS service.
In this post, we show how you can run Stable Diffusion models and achieve high performance at the lowest cost in Amazon Elastic Compute Cloud (Amazon EC2) using Amazon EC2 Inf2 instances powered by AWS Inferentia2. versions on AWS Inferentia2 cost-effectively. You can run both Stable Diffusion 2.1 The Stable Diffusion 2.1
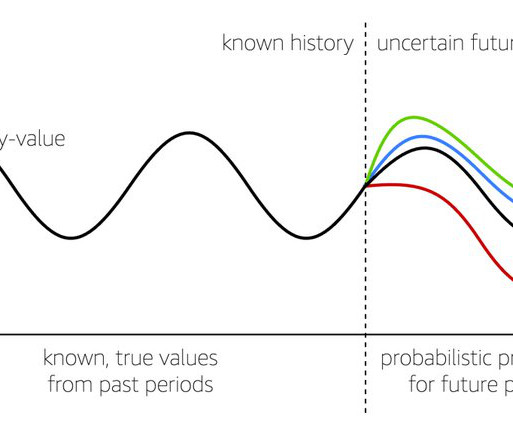
In this post, we show you how Amazon Web Services (AWS) helps in solving forecasting challenges by customizing machine learning (ML) models for forecasting. To download a copy of this dataset, visit. In this post, we access Amazon SageMaker Canvas through the AWS console. This will open the prediction results in a preview page.
Intelligent insights and recommendations Using its large knowledge base and advanced naturallanguageprocessing (NLP) capabilities, the LLM provides intelligent insights and recommendations based on the analyzed patient-physician interaction. An AWS account. If you dont have one, you can register for a new AWS account.
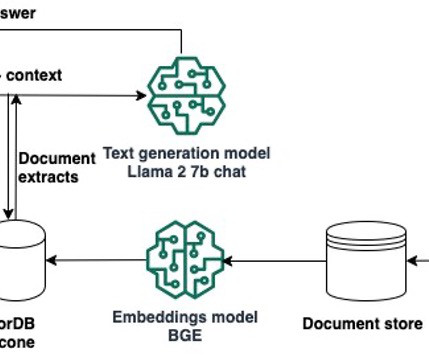
We use two AWS Media & Entertainment Blog posts as the sample external data, which we convert into embeddings with the BAAI/bge-small-en-v1.5 Prerequisites To follow the steps in this post, you need to have an AWS account and an AWS Identity and Access Management (IAM) role with permissions to create and access the solution resources.
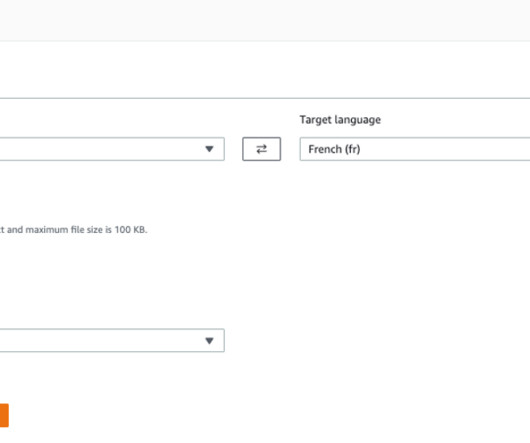
You can submit a document from the AWS Management Console , AWS Command Line Interface (AWS CLI), or AWS SDK and receive the translated document in real time while maintaining the format of the original document. The translated file is automatically saved to your browser’s downloaded folder, usually to Downloads.
In this post, we discuss how to use AWS generative artificial intelligence (AI) solutions like Amazon Bedrock to improve the underwriting process, including rule validation, underwriting guidelines adherence, and decision justification. However, implementing these technologies has been challenging for carriers.
By using the AWS Experience-Based Acceleration (EBA) program, they can enhance efficiency, scalability, and maintainability through close collaboration. To address these challenges and streamline modernization efforts, AWS offers the EBA program.
Solution overview The AI-powered asset inventory labeling solution aims to streamline the process of updating inventory databases by automatically extracting relevant information from asset labels through computer vision and generative AI capabilities. LLMs are large deep learning models that are pre-trained on vast amounts of data.
With the power of state-of-the-art techniques, the creative agency can support their customer by using generative AI models within their secure AWS environment. AWS has also developed hardware and chips using AWS Inferentia2 for high performance at the lowest cost for generative AI inference. to the local directory as tar.gz
Amazon Transcribe is an AWS service that allows customers to convert speech to text in either batch or streaming mode. It uses machine learning–powered automatic speech recognition (ASR), automatic language identification, and post-processing technologies. For more information about data privacy, see the Data Privacy FAQ.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content