This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
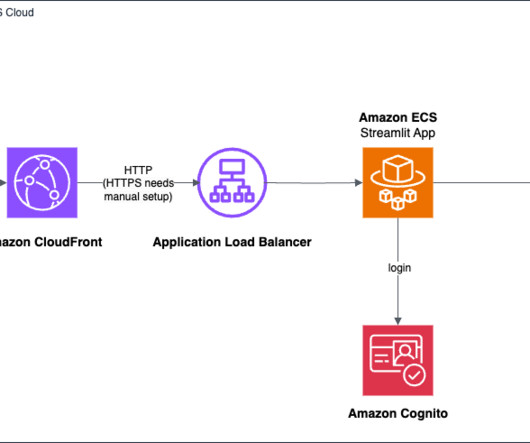
AWS provides a powerful set of tools and services that simplify the process of building and deploying generative AI applications, even for those with limited experience in frontend and backend development. The Python application uses the Streamlit library to provide a user-friendly interface for interacting with a generative AI model.
To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023. In this blog post, we showcase how you can perform efficient supervised fine tuning for a Meta Llama 3 model using PEFT on AWS Trainium with SageMaker HyperPod. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
It simplifies the often complex and time-consuming tasks involved in setting up and managing an MLflow environment, allowing ML administrators to quickly establish secure and scalable MLflow environments on AWS. For example, you can give users access permission to download popular packages and customize the development environment.
Streamlit is an open source framework for data scientists to efficiently create interactive web-based data applications in pure Python. Prerequisites To perform this solution, complete the following: Create and activate an AWS account. Make sure your AWS credentials are configured correctly. Install Python 3.7
Using vLLM on AWS Trainium and Inferentia makes it possible to host LLMs for high performance inference and scalability. Deploy vLLM on AWS Trainium and Inferentia EC2 instances In these sections, you will be guided through using vLLM on an AWS Inferentia EC2 instance to deploy Meta’s newest Llama 3.2 You will use inf2.xlarge
Hybrid architecture with AWS Local Zones To minimize the impact of network latency on TTFT for users regardless of their locations, a hybrid architecture can be implemented by extending AWS services from commercial Regions to edge locations closer to end users. Next, create a subnet inside each Local Zone. Amazon Linux 2).
70B through SageMaker JumpStart offers two convenient approaches: using the intuitive SageMaker JumpStart UI or implementing programmatically through the SageMaker Python SDK. Prior to joining AWS, Dr. Li held data science roles in the financial and retail industries. Adriana Simmons is a Senior Product Marketing Manager at AWS.
Today, we’re excited to announce the availability of Meta Llama 3 inference on AWS Trainium and AWS Inferentia based instances in Amazon SageMaker JumpStart. In this post, we demonstrate how easy it is to deploy Llama 3 on AWS Trainium and AWS Inferentia based instances in SageMaker JumpStart.
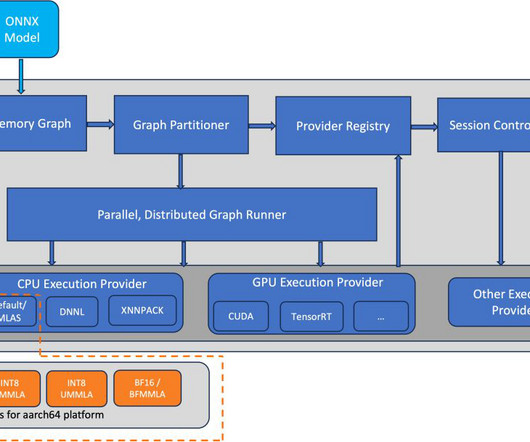
AWS Graviton3 processors are optimized for ML workloads, including support for bfloat16, Scalable Vector Extension (SVE), and Matrix Multiplication (MMLA) instructions. In this post, we show how to run ONNX Runtime inference on AWS Graviton3-based EC2 instances and how to configure them to use optimized GEMM kernels.
For AWS and Outerbounds customers, the goal is to build a differentiated machine learning and artificial intelligence (ML/AI) system and reliably improve it over time. First, the AWS Trainium accelerator provides a high-performance, cost-effective, and readily available solution for training and fine-tuning large models.
Today at AWS re:Invent 2024, we are excited to announce the new Container Caching capability in Amazon SageMaker, which significantly reduces the time required to scale generative AI models for inference. Container Caching addresses this scaling challenge by pre-caching the container image, eliminating the need to download it when scaling up.
In this post, we explore how to deploy distilled versions of DeepSeek-R1 with Amazon Bedrock Custom Model Import, making them accessible to organizations looking to use state-of-the-art AI capabilities within the secure and scalable AWS infrastructure at an effective cost. You can monitor costs with AWS Cost Explorer.
AWS optimized the PyTorch torch.compile feature for AWS Graviton3 processors. the optimizations are available in torch Python wheels and AWS Graviton PyTorch deep learning container (DLC). The goal for the AWS Graviton team was to optimize torch.compile backend for Graviton3 processors.
Introduction This article shows how to monitor a model deployed on AWS Sagemaker for quality, bias and explainability, using IBM Watson OpenScale on the IBM Cloud Pak for Data platform. This article shows how to use the endpoint generated from that tutorial to demonstrate how to monitor the AWS deployment with Watson OpenScale.
Virginia) AWS Region. Prerequisites To try the Llama 4 models in SageMaker JumpStart, you need the following prerequisites: An AWS account that will contain all your AWS resources. An AWS Identity and Access Management (IAM) role to access SageMaker AI. Access to accelerated instances (GPUs) for hosting the LLMs.
You can then export the model and deploy it on Amazon Sagemaker on Amazon Web Server (AWS). If you are set up with the required systems, you can download the sample project and complete the steps for hands-on learning. This sample uses the following platforms: Watson Studio and Watson Machine Learning with a Python 3.9
In this post, we walk through how to fine-tune Llama 2 on AWS Trainium , a purpose-built accelerator for LLM training, to reduce training times and costs. We review the fine-tuning scripts provided by the AWS Neuron SDK (using NeMo Megatron-LM), the various configurations we used, and the throughput results we saw.
AWS, Arm, Meta and others helped optimize the performance of PyTorch 2.0 As a result, we are delighted to announce that AWS Graviton-based instance inference performance for PyTorch 2.0 times the speed for BERT, making Graviton-based instances the fastest compute optimized instances on AWS for these models. is up to 3.5
Llama2 by Meta is an example of an LLM offered by AWS. To learn more about Llama 2 on AWS, refer to Llama 2 foundation models from Meta are now available in Amazon SageMaker JumpStart. Virginia) and US West (Oregon) AWS Regions, and most recently announced general availability in the US East (Ohio) Region.
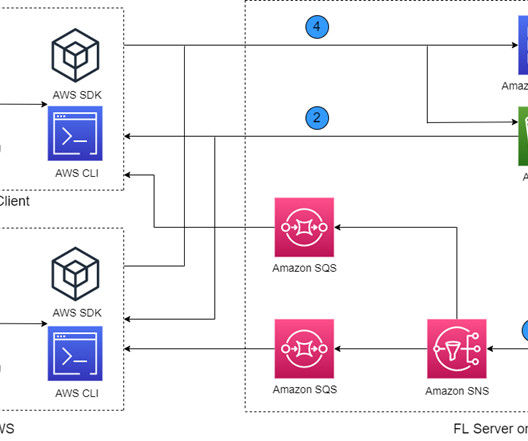
Customers often need to train a model with data from different regions, organizations, or AWS accounts. Existing partner open-source FL solutions on AWS include FedML and NVIDIA FLARE. These open-source packages are deployed in the cloud by running in virtual machines, without using the cloud-native services available on AWS.
Today, we’re excited to announce the availability of Llama 2 inference and fine-tuning support on AWS Trainium and AWS Inferentia instances in Amazon SageMaker JumpStart. In this post, we demonstrate how to deploy and fine-tune Llama 2 on Trainium and AWS Inferentia instances in SageMaker JumpStart.
Additionally, you can use AWS Lambda directly to expose your models and deploy your ML applications using your preferred open-source framework, which can prove to be more flexible and cost-effective. FastAPI is a modern, high-performance web framework for building APIs with Python. This will be used to deploy our solution.
In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience. Run the AWS Glue ML transform job.
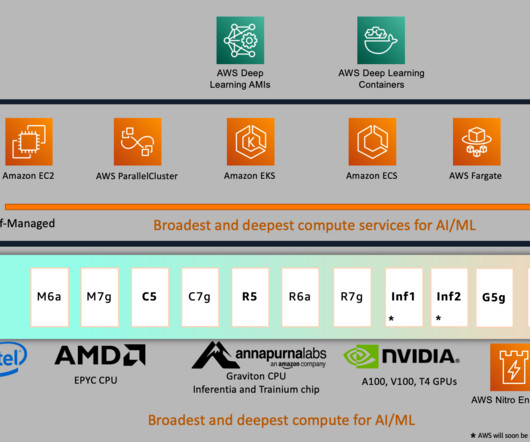
AWS has been innovating with purpose-built chips to address the growing need for powerful, efficient, and cost-effective compute hardware. You can use ml.trn1 and ml.inf2 compatible AWS Deep Learning Containers (DLCs) for PyTorch, TensorFlow, Hugging Face, and large model inference (LMI) to easily get started. petaflops for BF16/FP16.
This post shows a way to do this using Snowflake as the data source and by downloading the data directly from Snowflake into a SageMaker Training job instance. We create a custom training container that downloads data directly from the Snowflake table into the training instance rather than first downloading the data into an S3 bucket.
With this launch, you can now deploy NVIDIAs optimized reranking and embedding models to build, experiment, and responsibly scale your generative AI ideas on AWS. As part of NVIDIA AI Enterprise available in AWS Marketplace , NIM is a set of user-friendly microservices designed to streamline and accelerate the deployment of generative AI.
VIIRS' Day/Night Band (DNB) sensor captures nightlight imagery that is useful for mapping populations. ECOSTRESS has been used in the midwestern United States to detects droughts early enough to recover and protect crops.
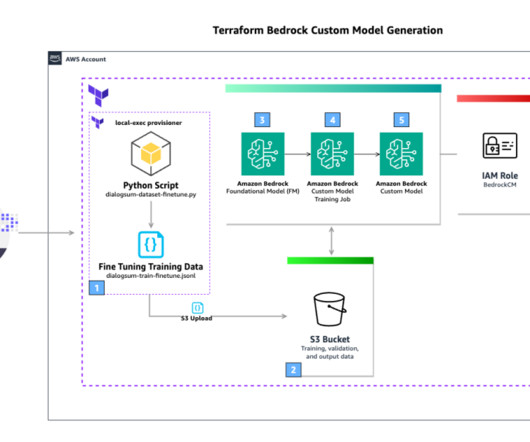
Terraform is an IaC tool that allows you to manage AWS resources, software as a service (SaaS) resources, datasets, and more, using declarative configuration. Configure your local Python virtual environment. Download the DialogSum public dataset and convert it to JSONL. python v3.8 Terraform v1.0.0 or newer installed.
These recipes include a training stack validated by Amazon Web Services (AWS) , which removes the tedious work of experimenting with different model configurations, minimizing the time it takes for iterative evaluation and testing. Alternatively, you can also use AWS Systems Manager and run a command like the following to start the session.
PyTorch is a machine learning (ML) framework that is widely used by AWS customers for a variety of applications, such as computer vision, natural language processing, content creation, and more. release, AWS customers can now do same things as they could with PyTorch 1.x 24xlarge with AWS PyTorch 2.0 on AWS PyTorch2.0
Home Table of Contents Introduction to GitHub Actions for Python Projects Introduction What Is CICD? For Python projects, CI/CD pipelines ensure that your code is consistently integrated and delivered with high quality and reliability. Git is the most commonly used VCS for Python projects, enabling collaboration and version tracking.
In addition to Amazon Bedrock, you can use other AWS services like Amazon SageMaker JumpStart and Amazon Lex to create fully automated and easily adaptable generative AI order processing agents. In this post, we show you how to build a speech-capable order processing agent using Amazon Lex, Amazon Bedrock, and AWS Lambda.
This post demonstrates a strategy for fine-tuning publicly available LLMs for the task of radiology report summarization using AWS services. In the following sections, we demonstrate fine-tuning an LLM available on SageMaker JumpStart for summarization of a domain-specific task via the SageMaker Python SDK. We use an ml.t3.medium
The number of companies launching generative AI applications on AWS is substantial and building quickly, including adidas, Booking.com, Bridgewater Associates, Clariant, Cox Automotive, GoDaddy, and LexisNexis Legal & Professional, to name just a few. Innovative startups like Perplexity AI are going all in on AWS for generative AI.
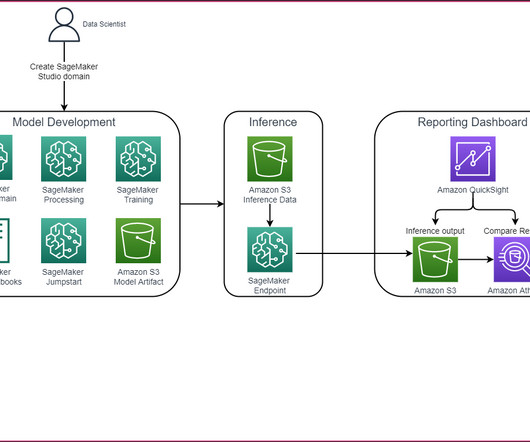
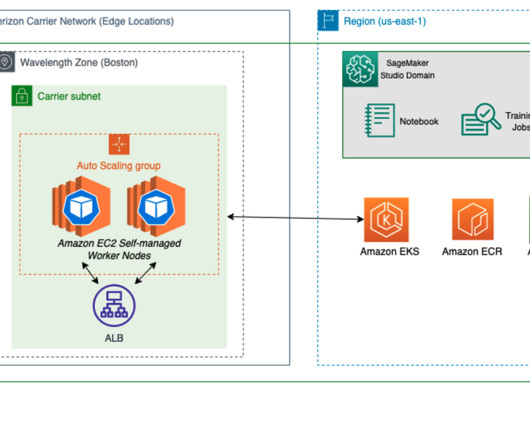
To reduce the barrier to entry of ML at the edge, we wanted to demonstrate an example of deploying a pre-trained model from Amazon SageMaker to AWS Wavelength , all in less than 100 lines of code. In this post, we demonstrate how to deploy a SageMaker model to AWS Wavelength to reduce model inference latency for 5G network-based applications.
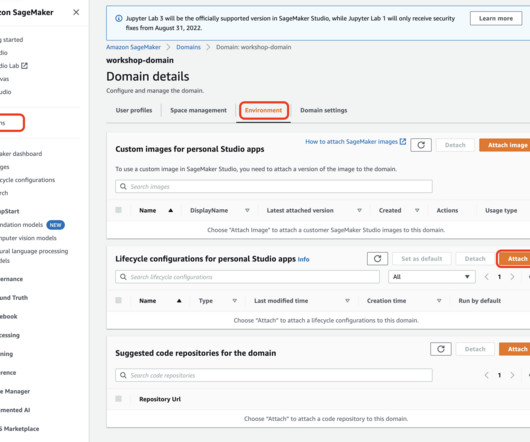
This post presents and compares options and recommended practices on how to manage Python packages and virtual environments in Amazon SageMaker Studio notebooks. You can manage app images via the SageMaker console, the AWS SDK for Python (Boto3), and the AWS Command Line Interface (AWS CLI). Define a Dockerfile.
For example, you might have acquired a company that was already running on a different cloud provider, or you may have a workload that generates value from unique capabilities provided by AWS. We show how you can build and train an ML model in AWS and deploy the model in another platform.
In addition to the built-in transforms, Data Wrangler contains a custom code editor that allows you to implement custom code written in Python, PySpark, or SparkSQL. This post shows how you can use code stored in AWS CodeCommit in the Data Wrangler custom transform step. Choose Python (PySpark) on the drop-down menu.
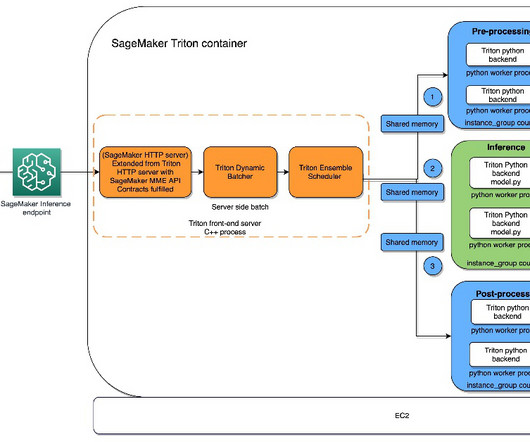
In this post, we help you understand the Python backend that is supported by Triton on SageMaker so that you can make an informed decision for your workloads and achieve great results. Triton supports instance types that support GPUs, CPUs, and AWS Inferentia chips, which allow you to maximize the performance for your workloads.
AWS makes it possible for organizations of all sizes and developers of all skill levels to build and scale generative AI applications with security, privacy, and responsible AI. In this post, we dive into the architecture and implementation details of GenASL, which uses AWS generative AI capabilities to create human-like ASL avatar videos.
In this post, we show how you can run Stable Diffusion models and achieve high performance at the lowest cost in Amazon Elastic Compute Cloud (Amazon EC2) using Amazon EC2 Inf2 instances powered by AWS Inferentia2. versions on AWS Inferentia2 cost-effectively. You can run both Stable Diffusion 2.1 The Stable Diffusion 2.1
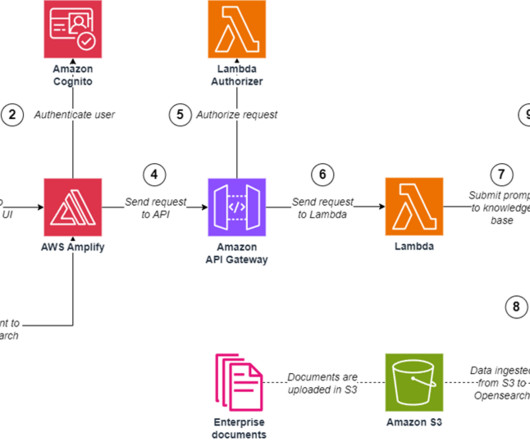
AWS Amplify to create and deploy the web application. Amazon API Gateway and AWS Lambda to create an API with an authentication layer and integrate with Amazon Bedrock. The AWS Well-Architected Framework documentation. The Implementing Microservices on AWS whitepaper. Refer to the Amazon Bedrock FAQs for further details.
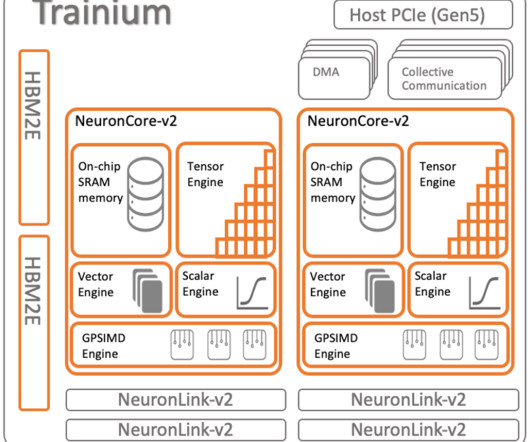
AWS Trainium and AWS Inferentia2 , which are purpose built for DL training and inference, extend their functionality and performance by supporting custom operators (or CustomOps, for short). AWS Neuron , the SDK that supports these accelerators, uses the standard PyTorch interface for CustomOps.
Prerequisties The proposed solution can be implemented in a personal AWS environment using the code that we provide. Before running the labs in this post, ensure you have the following: An AWS account. The appropriate AWS Identity and Access Management (IAM) permissions to access services used in the lab.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content