This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Earlier this year, we published the first in a series of posts about how AWS is transforming our seller and customer journeys using generative AI. Field Advisor serves four primary use cases: AWS-specific knowledge search With Amazon Q Business, weve made internal data sources as well as public AWS content available in Field Advisors index.
They then use SQL to explore, analyze, visualize, and integrate data from various sources before using it in their ML training and inference. Previously, data scientists often found themselves juggling multiple tools to support SQL in their workflow, which hindered productivity.
In this post, we save the data in JSON format, but you can also choose to store it in your preferred SQL or NoSQL database. Prerequisites To perform this solution, complete the following: Create and activate an AWS account. Make sure your AWS credentials are configured correctly. Install Python 3.7
In this post, we explore how you can use Amazon Q Business , the AWS generative AI-powered assistant, to build a centralized knowledge base for your organization, unifying structured and unstructured datasets from different sources to accelerate decision-making and drive productivity. In this post, we use IAM Identity Center as the SAML 2.0-aligned
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. Today, generative AI can enable people without SQL knowledge. This generative AI task is called text-to-SQL, which generates SQL queries from natural language processing (NLP) and converts text into semantically correct SQL.
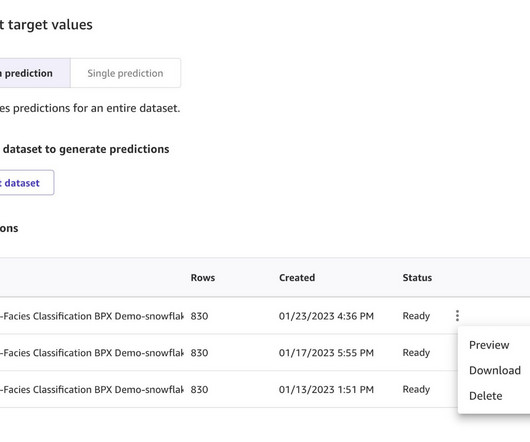
Prerequisites Before you begin, make sure you have the following prerequisites in place: An AWS account and role with the AWS Identity and Access Management (IAM) privileges to deploy the following resources: IAM roles. Basic knowledge of a SQL query editor. You can now view the predictions and download them as CSV.
To address this challenge, AWS recently announced the preview of Amazon Bedrock Custom Model Import , a feature that you can use to import customized models created in other environments—such as Amazon SageMaker , Amazon Elastic Compute Cloud (Amazon EC2) instances, and on premises—into Amazon Bedrock.
In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience. Run the AWS Glue ML transform job.
Discover your data and put it to work using familiar AWS tools to complete end-to-end development workflows, including data analysis, data processing, model training, generative AI app building, and more, in a single governed environment. With the SQL editor, you can query data lakes, databases, data warehouses, and federated data sources.
Photo by Caspar Camille Rubin on Unsplash AWS Athena is a serverless interactive query system. So if you are familiar with the Standard SQL queries, you are good to go!! The sample data used in this article can be downloaded from the link below, Fruit and Vegetable Prices How much do fruits and vegetables cost? That is it!!
This post shows a way to do this using Snowflake as the data source and by downloading the data directly from Snowflake into a SageMaker Training job instance. We create a custom training container that downloads data directly from the Snowflake table into the training instance rather than first downloading the data into an S3 bucket.
Prerequisites To build the solution yourself, there are the following prerequisites: You need an AWS account with an AWS Identity and Access Management (IAM) role that has permissions to manage resources created as part of the solution (for example AmazonSageMakerFullAccess and AmazonS3FullAccess ).
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. Prerequisites To continue with the examples in this post, you need to create the required AWS resources.
With the Amazon Bedrock serverless experience, you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using the Amazon Web Services (AWS) tools without having to manage infrastructure. The following screenshot shows what the upload looks like when it’s complete.
The service, which was launched in March 2021, predates several popular AWS offerings that have anomaly detection, such as Amazon OpenSearch , Amazon CloudWatch , AWS Glue Data Quality , Amazon Redshift ML , and Amazon QuickSight. To use this feature, you can write rules or analyzers and then turn on anomaly detection in AWS Glue ETL.
Additionally, using Amazon Comprehend with AWS PrivateLink means that customer data never leaves the AWS network and is continuously secured with the same data access and privacy controls as the rest of your applications. Download the SageMaker Data Wrangler flow. Review the SageMaker Data Wrangler flow. Add a destination node.
This post describes how to deploy recurring Forecast workloads (time series forecasting workloads) with no code using AWS CloudFormation , AWS Step Functions , and AWS Systems Manager. The console and AWS CLI methods are best suited for quick experimentation to check the feasibility of time series forecasting using your data.
Source: Generative AI on AWS (O’Reilly, 2023) LoRA has gained popularity recently for several reasons. Each works through a different way to handle LoRA fine-tuned models as illustrated in the following diagram: First, we download the pre-trained Llama2 model with 7 billion parameters using SageMaker Studio Notebooks.
Configure AWS Identity and Access Management (IAM) roles for Snowflake and create a Snowflake integration. Prerequisites Prerequisites for this post include the following: An AWS account. Download the training_data.csv and validation_data_nofacies.csv files to your local machine. Import Snowflake directly into Canvas.
Cost optimization is one of the pillars of the AWS Well-Architected Framework , and it’s a continual process of refinement and improvement over the span of a workload’s lifecycle. AWS is dedicated to helping you achieve the highest savings by offering extensive service and pricing options.
This allows you to create unique views and filters, and grants management teams access to a streamlined, one-click dashboard without needing to log in to the AWS Management Console and search for the appropriate dashboard. On the AWS CloudFormation console, create a new stack. Clone the GitHub repo to create the container image: app.py
This is where the AWS suite of low-code and no-code ML services becomes an essential tool. As a strategic systems integrator with deep ML experience, Deloitte utilizes the no-code and low-code ML tools from AWS to efficiently build and deploy ML models for Deloitte’s clients and for internal assets. On the Create menu, choose Document.
It provides tools that offer data connectors to ingest your existing data with various sources and formats (PDFs, docs, APIs, SQL, and more). Download press releases to use as our external knowledge base. For account setup instructions, see Create an AWS Account. Deploy an embedding model from the Amazon SageMaker JumpStart hub.
This includes provisioning Amazon Simple Storage Service (Amazon S3) buckets, AWS Identity and Access Management (IAM) access permissions, Snowflake storage integration for individual users, and an ongoing mechanism to manage or clean up data copies in Amazon S3. An AWS account with admin access.
In 2021, we launched AWS Support Proactive Services as part of the AWS Enterprise Support plan. In Part 1 , we showed how to get started using AWS Cost Explorer to identify cost optimization opportunities in SageMaker. For general guidance on using Cost Explorer, refer to AWS Cost Explorer’s New Look and Common Use Cases.
As described in the AWS Well-Architected Framework , separating workloads across accounts enables your organization to set common guardrails while isolating environments. Organizations with a multi-account architecture typically have Amazon Redshift and SageMaker Studio in two separate AWS accounts.
Now, teams that collect sensor data signals from machines in the factory can unlock the power of services like Amazon Timestream , Amazon Lookout for Equipment , and AWS IoT Core to easily spin up and test a fully production-ready system at the local edge to help avoid catastrophic downtime events. Prerequisites. Save the files locally.
The following steps give an overview of how to use the new capabilities launched in SageMaker for Salesforce to enable the overall integration: Set up the Amazon SageMaker Studio domain and OAuth between Salesforce and the AWS account s. Select Other type of secret. Save the secret and note the ARN of the secret.
It has over 300 preconfigured data transformations as well as the ability to bring in custom code to create custom transformations in PySpark, SQL, and a variety of data processing libraries, such as pandas. Finally, we need to download and unzip the MovieLens dataset and place it in an Amazon Simple Storage Service (Amazon S3) bucket.
If you don’t have a Spark environment set up in your Cloudera environment, you can easily set up a Dataproc cluster on Google Cloud Platform (GCP) or an EMR cluster on AWS to do hands-on on your own. Spark-Snowflake Connector Dependencies Setup As we are using Python + Spark, so we don’t need Snowflake Connector jar download/setup.
Each migration SQL script is assigned a unique sequence number to facilitate the correct order of application. Step-B The objective of this step is to copy the inventory data file from the AWS S3 location to the staging inventory table using the Snowflake pipe object. Each branch serves a specific purpose, as defined below.
Download a free PDF by filling out the form. Download the complete How To Get Started With Snowflake Guide Here Loading Data Now there is a game plan in place for handling cost attribution, configuration optimization, and access management. And once again, for loading data, do not use SQL Inserts.
This is powerful, as customers can discover insights in their data lake using our intelligent SQL editor, Compose. We’re definitely going to do much more with our other technology partners, like Google, SAP, and AWS. Read the blog, Alation Acquires Lyngo Analytics (to make SQL easy for everyone!). With 21.4,
Snowpark, offered by the Snowflake AI Data Cloud , consists of libraries and runtimes that enable secure deployment and processing of non-SQL code, such as Python, Java, and Scala. SnowCLI simplifies the process and automatically converts the Python code to SQL script (more on this in the next section).
SmartSuggestions — In Compose, Alation’s SQL editor, AI-powered suggestions actively show query writers relevant data to use as they query. for the popular database SQL Server. This builds on existing column-level lineage support for AWS Redshift, Google BigQuery, and Snowflake. Download the solution brief.
In addition, you can write custom transformation in PySpark, SQL, and pandas. Complete the following steps: Download the MNIST dataset training dataset. About the authors Adeleke Coker is a Global Solutions Architect with AWS. Vishaal Kapoor is a Senior Applied Scientist with AWS AI.
Reviewed the Data Engineer Associate certification requirements and downloaded the study guide. Completed all SQL projects available on DataCamp, learned from my mistakes, and improved. Began studying for my AWS Solution Architect Professional certification concurrently to enhance my skill set. Repeated this process as needed.
Just click this button and fill out the form to download it. The June 2021 release of Power BI Desktop introduced Custom SQL queries to Snowflake in DirectQuery mode. In 2021, Microsoft enabled Custom SQL queries to be run to Snowflake in DirectQuery mode further enhancing the connection capabilities between the platforms.
Note that these costs per credit are based on an account in AWS US-East-1 and may differ depending on the cloud provider/region the Snowflake account is created in. Can you point to bad (long-running) SQL ? Download our Getting Started with Snowflake Guide for actionable steps on how to get the most out of Snowflake.
It supports most major cloud providers, such as AWS, GCP, and Azure. When we download a Git repository, we also get the.dvc files which we use to download the data associated with them. LakeFS is fully compatible with many ecosystems of data engineering tools such as AWS, Azure, Spark, Databrick, MlFlow, Hadoop and others.
Step 3: Query the External Table Once the external table is created, you can query and analyze the data using standard SQL queries in Snowflake. However, due to compliance issues, parallel Snowflake users are not authorized to log in directly to the cloud provider (AWS/GCP/AZURE) hosted by Snowflake.
To save the model using ONNX, you need to have onnx and onnxruntime packages downloaded in your system. Once a model is packaged as a Bento, it can be deployed to various serving platforms like AWS Lambda , Kubernetes , or Docker. You can download this library with the help of the Python package installer. $
Some of the popular cloud-based vendors are: Hevo Data Equalum AWS DMS On the other hand, there are vendors offering on-premise data pipeline solutions and are mostly preferred by organizations dealing with highly sensitive data. Enables users to trigger their custom transformations via SQL and dbt. Cons Limited connectors.
For example, if you use AWS, you may prefer Amazon SageMaker as an MLOps platform that integrates with other AWS services. SageMaker Studio offers built-in algorithms, automated model tuning, and seamless integration with AWS services, making it a powerful platform for developing and deploying machine learning solutions at scale.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content