This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Overview ETL (Extract, Transform, and Load) is a very common technique in data engineering. Traditionally, ETL processes are […]. The post Crafting Serverless ETL Pipeline Using AWS Glue and PySpark appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon.
Introduction AWS Glue helps Data Engineers to prepare data for other data consumers through the Extract, Transform & Load (ETL) Process. The post AWS Glue for Handling Metadata appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon. It provides organizations with […].
Introduction Apache Airflow is a powerful platform that revolutionizes the management and execution of Extracting, Transforming, and Loading (ETL) data processes. This article explores the intricacies of automating ETL pipelines using Apache Airflow on AWS EC2.
Source: [link] Introduction If you are familiar with databases, or data warehouses, you have probably heard the term “ETL.” The post AWS Glue: Simplifying ETL Data Processing appeared first on Analytics Vidhya. For the […].
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
ArticleVideos I will admit, AWS Data Wrangler has become my go-to package for developing extract, transform, and load (ETL) data pipelines and other day-to-day. The post Using AWS Data Wrangler with AWS Glue Job 2.0 appeared first on Analytics Vidhya.
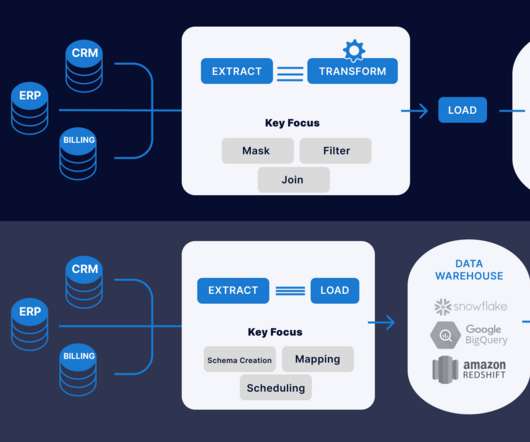
Introduction This article will explain the difference between ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) when data transformation occurs. In ETL, data is extracted from multiple locations to meet the requirements of the target data file and then placed into the file.
Introduction In the era of Data storehouse, the need for assimilating the data from contrasting sources into a single consolidated database requires you to Extract the data from its parent source, Transform and amalgamate it, and thus, Load it into the consolidated database (ETL).
The translation playground could be adapted into a scalable serverless solution as represented by the following diagram using AWS Lambda , Amazon Simple Storage Service (Amazon S3), and Amazon API Gateway. To run the project code, make sure that you have fulfilled the AWS CDK prerequisites for Python.
This year’s AWS re:Invent conference, held in Las Vegas from November 27 through December 1, showcased the advancements of Amazon Redshift to help you further accelerate your journey towards modernizing your cloud analytics environments.
The ETL process is defined as the movement of data from its source to destination storage (typically a Data Warehouse) for future use in reports and analyzes. Understanding the ETL Process. Before you understand what is ETL tool , you need to understand the ETL Process first. Types of ETL Tools.
Communication between the two systems was established through Kerberized Apache Livy (HTTPS) connections over AWS PrivateLink. To promote the success of this migration, we collaborated with the AWS team to create automated and intelligent digital experiences that demonstrated Rockets understanding of its clients and kept them connected.
“Data is at the center of every application, process, and business decision,” wrote Swami Sivasubramanian, VP of Database, Analytics, and Machine Learning at AWS, and I couldn’t agree more. A common pattern customers use today is to build data pipelines to move data from Amazon Aurora to Amazon Redshift.
In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience. Run the AWS Glue ML transform job.
In line with this mission, Talent.com collaborated with AWS to develop a cutting-edge job recommendation engine driven by deep learning, aimed at assisting users in advancing their careers. The solution does not require porting the feature extraction code to use PySpark, as required when using AWS Glue as the ETL solution.
In this post, we explore how you can use Amazon Q Business , the AWS generative AI-powered assistant, to build a centralized knowledge base for your organization, unifying structured and unstructured datasets from different sources to accelerate decision-making and drive productivity. In this post, we use IAM Identity Center as the SAML 2.0-aligned
Lets assume that the question What date will AWS re:invent 2024 occur? The corresponding answer is also input as AWS re:Invent 2024 takes place on December 26, 2024. If the question was Whats the schedule for AWS events in December?, This setup uses the AWS SDK for Python (Boto3) to interact with AWS services.
This post was written in collaboration with Bhajandeep Singh and Ajay Vishwakarma from Wipro’s AWS AI/ML Practice. AWS also helps data science and DevOps teams to collaborate and streamlines the overall model lifecycle process. Wipro is an AWS Premier Tier Services Partner and Managed Service Provider (MSP).
Summary: This guide explores the top list of ETL tools, highlighting their features and use cases. To harness this data effectively, businesses rely on ETL (Extract, Transform, Load) tools to extract, transform, and load data into centralized systems like data warehouses. What is ETL? What are ETL Tools?
In this post, we share how Kakao Games and the Amazon Machine Learning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWS data and ML services such as AWS Glue and Amazon SageMaker. The ETL pipeline, MLOps pipeline, and ML inference should be rebuilt in a different AWS account.
Two of the more popular methods, extract, transform, load (ETL ) and extract, load, transform (ELT) , are both highly performant and scalable. ETL/ELT tools typically have two components: a design time (to design data integration jobs) and a runtime (to execute data integration jobs).
The solution: IBM databases on AWS To solve for these challenges, IBM’s portfolio of SaaS database solutions on Amazon Web Services (AWS), enables enterprises to scale applications, analytics and AI across the hybrid cloud landscape. Let’s delve into the database portfolio from IBM available on AWS.
Supports powerful features like JOIN, CDC, UPSERT, and LOOKUP, enabling real-time analytics and ETL at scale. Process millions of rows per second from Kafka, Pulsar, or ClickHouse, and seamlessly write results back. proton/src/IO/Kafka/AwsMskIamSigner.cpp at develop timeplus-io/proton
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. Though it’s worth mentioning that Airflow isn’t used at runtime as is usual for extract, transform, and load (ETL) tasks.
This brings reliability to data ETL (Extract, Transform, Load) processes, query performances, and other critical data operations. AWS CloudFormation is a service offered by Amazon Web Services (AWS) that allows you to define cloud infrastructure in JSON or YAML templates. So why using IaC for Cloud Data Infrastructures?
Strong analytical skills and the ability to work with large datasets are critical, as is familiarity with data modeling and ETL processes. Additionally, knowledge of cloud platforms (AWS, Google Cloud) and experience with deployment tools (Docker, Kubernetes) are highly valuable.
Photo by Caspar Camille Rubin on Unsplash AWS Athena is a serverless interactive query system. Go to the AWS Glue Console. Create a Glue Job to perform ETL operations on your data. Athena Setup Go to the AWS management console and open Athena. It means we dont need to manage any infrastructure behind them. That is it!!
Here are a few of the things that you might do as an AI Engineer at TigerEye: - Design, develop, and validate statistical models to explain past behavior and to predict future behavior of our customers’ sales teams - Own training, integration, deployment, versioning, and monitoring of ML components - Improve TigerEye’s existing metrics collection and (..)
Summary: Selecting the right ETL platform is vital for efficient data integration. Introduction In today’s data-driven world, businesses rely heavily on ETL platforms to streamline data integration processes. What is ETL in Data Integration? Let’s explore some real-world applications of ETL in different sectors.
These tools provide data engineers with the necessary capabilities to efficiently extract, transform, and load (ETL) data, build data pipelines, and prepare data for analysis and consumption by other applications. Amazon Redshift: Amazon Redshift is a cloud-based data warehousing service provided by Amazon Web Services (AWS).
Kafka And ETL Processing: You might be using Apache Kafka for high-performance data pipelines, stream various analytics data, or run company critical assets using Kafka, but did you know that you can also use Kafka clusters to move data between multiple systems. A three-step ETL framework job should do the trick. Conclusion.
Spark is well suited to applications that involve large volumes of data, real-time computing, model optimization, and deployment. Read about Apache Zeppelin: Magnum Opus of MLOps in detail AWS SageMaker AWS SageMaker is an AI service that allows developers to build, train and manage AI models.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
AI Powered Speech Analytics for Amazon Connect This video walks thru the AWS products necessary for converting video to text, translating and performing basic NLP. Amazon Builders’ Library is now available in 16 Languages The Builder’s Library is a huge collection of resources about how Amazon builds and manages software.
In this post, we show you how SnapLogic , an AWS customer, used Amazon Bedrock to power their SnapGPT product through automated creation of these complex DSL artifacts from human language. SnapLogic background SnapLogic is an AWS customer on a mission to bring enterprise automation to the world.
Writing data to an AWS data lake and retrieving it to populate an AWS RDS MS SQL database involves several AWS services and a sequence of steps for data transfer and transformation. This process leverages AWS S3 for the data lake storage, AWS Glue for ETL operations, and AWS Lambda for orchestration.
This post presents a solution that uses a workflow and AWS AI and machine learning (ML) services to provide actionable insights based on those transcripts. We use multiple AWS AI/ML services, such as Contact Lens for Amazon Connect and Amazon SageMaker , and utilize a combined architecture.
Summary: This article explores the significance of ETL Data in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
The embeddings are captured in Amazon Simple Storage Service (Amazon S3) via Amazon Kinesis Data Firehose , and we run a combination of AWS Glue extract, transform, and load (ETL) jobs and Jupyter notebooks to perform the embedding analysis. For more information about AWS CDK installation, refer to Getting started with the AWS CDK.
Data is frequently kept in data lakes that can be managed by AWS Lake Formation , giving you the ability to implement fine-grained access control using a straightforward grant or revoke procedure. Account A is the data lake account that houses all the ML-ready data obtained through extract, transform, and load (ETL) processes.
In this article, we will discover how to build an ETL pipeline by consuming data from S3 to AWS Redshift via the Glue service and… Continue reading on MLearning.ai »
Discover your data and put it to work using familiar AWS tools to complete end-to-end development workflows, including data analysis, data processing, model training, generative AI app building, and more, in a single governed environment. Youre redirected to the AWS CloudFormation console to deploy a stack to configure VPC resources.
In this article we’re going to check what is an Azure function and how we can employ it to create a basic extract, transform and load (ETL) pipeline with minimal code. Extract, transform and Load Before we begin, let’s shed some light on what an ETL pipeline essentially is. ELT stands for extract, load and transform.
The customer review analysis workflow consists of the following steps: A user uploads a file to dedicated data repository within your Amazon Simple Storage Service (Amazon S3) data lake, invoking the processing using AWS Step Functions. In the first step, an AWS Lambda function reads and validates the file, and extracts the raw data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content