This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database. Create dbt models in dbt Cloud.
Communication between the two systems was established through Kerberized Apache Livy (HTTPS) connections over AWS PrivateLink. To promote the success of this migration, we collaborated with the AWS team to create automated and intelligent digital experiences that demonstrated Rockets understanding of its clients and kept them connected.
This post was written in collaboration with Bhajandeep Singh and Ajay Vishwakarma from Wipro’s AWS AI/ML Practice. AWS also helps data science and DevOps teams to collaborate and streamlines the overall model lifecycle process. Wipro is an AWS Premier Tier Services Partner and Managed Service Provider (MSP).
Lets assume that the question What date will AWS re:invent 2024 occur? The corresponding answer is also input as AWS re:Invent 2024 takes place on December 26, 2024. If the question was Whats the schedule for AWSevents in December?, This setup uses the AWS SDK for Python (Boto3) to interact with AWS services.
The result of these events can be evaluated afterwards so that they make better decisions in the future. With this proactive approach, Kakao Games can launch the right events at the right time. Kakao Games can then create a promotional event not to leave the game. However, this approach is reactive.
Strong analytical skills and the ability to work with large datasets are critical, as is familiarity with data modeling and ETL processes. Additionally, knowledge of cloud platforms (AWS, Google Cloud) and experience with deployment tools (Docker, Kubernetes) are highly valuable.
Kafka And ETL Processing: You might be using Apache Kafka for high-performance data pipelines, stream various analytics data, or run company critical assets using Kafka, but did you know that you can also use Kafka clusters to move data between multiple systems. A three-step ETL framework job should do the trick. Conclusion.
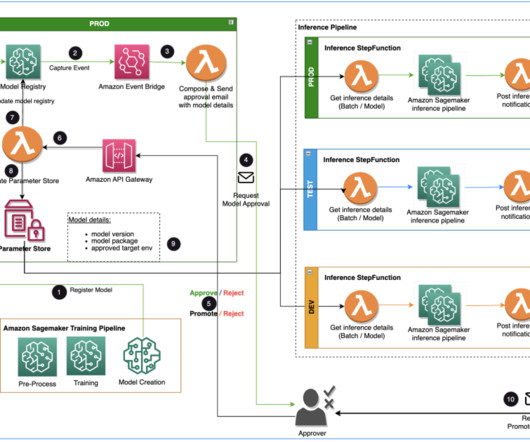
In this post, we discuss how the AWS AI/ML team collaborated with the Merck Human Health IT MLOps team to build a solution that uses an automated workflow for ML model approval and promotion with human intervention in the middle. EventBridge monitors status change events to automatically take actions with simple rules.
It can represent a geographical area as a whole or it can represent an event associated with a geographical area. We then discuss the various use cases and explore how you can use AWS services to clean the data, how machine learning (ML) can aid in this effort, and how you can make ethical use of the data in generating visuals and insights.
The following figure shows an example diagram that illustrates an orchestrated extract, transform, and load (ETL) architecture solution. For example, searching for the terms “How to orchestrate ETL pipeline” returns results of architecture diagrams built with AWS Glue and AWS Step Functions.
Diagnostic analytics: Diagnostic analytics goes a step further by analyzing historical data to determine why certain events occurred. By understanding the “why” behind past events, organizations can make informed decisions to prevent or replicate them. It seeks to identify the root causes of specific outcomes or issues.
TR wanted to take advantage of AWS managed services where possible to simplify operations and reduce undifferentiated heavy lifting. TR used AWS Glue DataBrew and AWS Batch jobs to perform the extract, transform, and load (ETL) jobs in the ML pipelines, and SageMaker along with Amazon Personalize to tailor the recommendations.
Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. Data Engineering : Building and maintaining data pipelines, ETL (Extract, Transform, Load) processes, and data warehousing.
Extraction, Transform, Load (ETL). AWS Glue helps users to build data catalogues, and Quicksight provides data visualisation and dashboard construction. The services from AWS can be catered to meet the needs of each business user. Profisee notices changes in data and assigns events within the systems. Data transformation.
The following diagram illustrates the architecture of a news recommender application powered by Amazon Personalize and supporting AWS services. AWS Glue performs extract, transform, and load (ETL) operations to align the data with the Amazon Personalize datasets schema.
Cloud platforms, such as Amazon Web Services (AWS), Microsoft Azure, or Google Cloud Platform (GCP), provide scalable and flexible infrastructure options. What makes the difference is a smart ETL design capturing the nature of process mining data. But costs won’t decrease only migrating from on-premises to cloud and vice versa.
In this post, we discuss how CCC Intelligent Solutions (CCC) combined Amazon SageMaker with other AWS services to create a custom solution capable of hosting the types of complex artificial intelligence (AI) models envisioned. The figure below illustrates a high-level overview of our asynchronous event-driven architecture.
AWS provides several tools to create and manage ML model deployments. 2 If you are somewhat familiar with AWS ML base tools, the first thing that comes to mind is “Sagemaker”. AWS Sagemeaker is in fact a great tool for machine learning operations (MLOps) to automate and standardize processes across the ML lifecycle. S3 buckets.
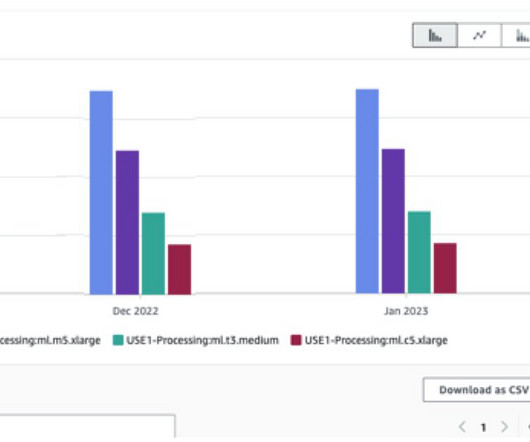
In 2021, we launched AWS Support Proactive Services as part of the AWS Enterprise Support plan. In Part 1, we showed how to get started using AWS Cost Explorer to identify cost optimization opportunities in SageMaker. In this series of posts, we share lessons learned about optimizing costs in Amazon SageMaker.
But it’s interoperable on any cloud like Azure, AWS or GCP. You can use OpenScale to monitor these events. It focus on the monitoring and retraining policies that are keen for continious training. The provided code to this article refers to IBM’S CP4D and demonstrates how a continuous training could be implemented.
Understanding Fivetran Fivetran is a popular Software-as-a-Service platform that enables users to automate the movement of data and ETL processes across diverse sources to a target destination. For a longer overview, along with insights and best practices, please feel free to jump back to the previous blog.
EVENT — ODSC East 2024 In-Person and Virtual Conference April 23rd to 25th, 2024 Join us for a deep dive into the latest data science and AI trends, tools, and techniques, from LLMs to data analytics and from machine learning to responsible AI. Interested in attending an ODSC event? Learn more about our upcoming events here.
And that’s when what usually happens, happened: We came for the ML models, we stayed for the ETLs. But even when the ETLs were well thought out, they were a bit “outdated” in their approach. 2 To teach them how to use the stack considered best for them (mostly focusing on fundamentals of MLOps and AWS Sagemaker / Sagemaker Studio).
Fivetran Fivetran is a tool dedicated to replicating applications, databases, events, and files into a high-performance data warehouse, such as Snowflake. What sets Matillion apart is that it can be deployed in the cloud (GCP, AWS, or Azure) or on-premises which can be helpful for users working in highly regulated industries.
Data Ingestion : Involves raw data collection from origin and storage using architectures such as batch, streaming or event-driven. Fivetran Overview It is aimed at automating the data movement across the cloud platform of different enterprises, alleviating the pain points of the complexity around the ETL process.
Key components of data warehousing include: ETL Processes: ETL stands for Extract, Transform, Load. ETL is vital for ensuring data quality and integrity. Apache Kafka Kafka is a distributed event streaming platform for building real-time data pipelines and streaming applications.
Machine learning workflow of the Visual Search team Here’s a high-level overview of the typical ML workflow on the team: First, they would pull raw data from the producers (events, user actions in the app, etc.) They built on what the Automation Ops team had already developed to integrate with the AWS tech stack.
Flexibility: Its use cases are wider than just machine learning; for example, we can use it to set up ETL pipelines. Flexibility: Airflow was designed with batch workflows in mind; it was not meant for permanently running event-based workflows. via Skypilot or another orchestrator defined in your MLOps stack).
Traditionally, answering this question would involve multiple data exports, complex extract, transform, and load (ETL) processes, and careful data synchronization across systems. You can use familiar AWS services for model development, generative AI, data processing, and analyticsall within a single, governed environment.
Apache Kafka Apache Kafka is a distributed event streaming platform for real-time data pipelines and stream processing. is similar to the traditional Extract, Transform, Load (ETL) process. Tooling : Apache Tika , ElasticSearch , Databricks , and AWS Glue for metadata extraction and management. Unstructured.io
Modern low-code/no-code ETL tools allow data engineers and analysts to build pipelines seamlessly using a drag-and-drop and configure approach with minimal coding. One such option is the availability of Python Components in Matillion ETL, which allows us to run Python code inside the Matillion instance.
Operational health events – including operational issues, software lifecycle notifications, and more – serve as critical inputs to cloud operations management. Inefficiencies in handling these events can lead to unplanned downtime, unnecessary costs, and revenue loss for organizations.
In the context of enterprise data asset search powered by a metadata catalog hosted on services such Amazon DataZone, AWS Glue, and other third-party catalogs, knowledge graphs can help integrate this linked data and also enable a scalable search paradigm that integrates metadata that evolves over time.
During these live events, F1 IT engineers must triage critical issues across its services, such as network degradation to one of its APIs. Recognizing this challenge as an opportunity for innovation, F1 partnered with Amazon Web Services (AWS) to develop an AI-driven solution using Amazon Bedrock to streamline issue resolution.
By segment, North America revenue increased 12% Y oY from $316B to $353B, International revenue grew 11% Y oY from$118B to $131B, and AWS revenue increased 13% Y oY from $80B to $91B. The template is compatible with and can be modified for other LLMs, such as LLMs hosted on Amazon Sagemaker Jumpstart and self-hosted on AWS infrastructure.
Apache Kafka Apache Kafka is a distributed event streaming platform used for real-time data processing. Talend Talend is a data integration tool that enables users to extract, transform, and load (ETL) data across different sources. Apache Spark Apache Spark is a powerful data processing framework that efficiently handles Big Data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content