This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
By analyzing a wide range of data points, were able to quickly and accurately assess the risk associated with a loan, enabling us to make more informed lending decisions and get our clients the financing they need. Communication between the two systems was established through Kerberized Apache Livy (HTTPS) connections over AWS PrivateLink.
Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. Complete the following steps: Choose an AWS Region Amazon Q supports (for this post, we use the us-east-1 Region). aligned identity provider (IdP).
“Data is at the center of every application, process, and business decision,” wrote Swami Sivasubramanian, VP of Database, Analytics, and Machine Learning at AWS, and I couldn’t agree more. A common pattern customers use today is to build data pipelines to move data from Amazon Aurora to Amazon Redshift.
While these models are trained on vast amounts of generic data, they often lack the organization-specific context and up-to-date information needed for accurate responses in business settings. Lets assume that the question What date will AWS re:invent 2024 occur? If the question was Whats the schedule for AWS events in December?,
In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience. Run the AWS Glue ML transform job.
For instance, Berkeley’s Division of Data Science and Information points out that entry level data science jobs remote in healthcare involves skills in NLP (Natural Language Processing) for patient and genomic data analysis, whereas remote data science jobs in finance leans more on skills in risk modeling and quantitative analysis.
Summary: This guide explores the top list of ETL tools, highlighting their features and use cases. Introduction In todays data-driven world, organizations are overwhelmed with vast amounts of information. For example, companies like Amazon use ETL tools to optimize logistics, personalize customer experiences, and drive sales.
Here are a few of the things that you might do as an AI Engineer at TigerEye: - Design, develop, and validate statistical models to explain past behavior and to predict future behavior of our customers’ sales teams - Own training, integration, deployment, versioning, and monitoring of ML components - Improve TigerEye’s existing metrics collection and (..)
In this post, we share how Kakao Games and the Amazon Machine Learning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWS data and ML services such as AWS Glue and Amazon SageMaker. For example, each log is written in the format of timestamp, user ID, and event information.
Enhanced Security and Compliance Data Warehouses often store sensitive information, making security a paramount concern. This brings reliability to data ETL (Extract, Transform, Load) processes, query performances, and other critical data operations. So why using IaC for Cloud Data Infrastructures?
AI Powered Speech Analytics for Amazon Connect This video walks thru the AWS products necessary for converting video to text, translating and performing basic NLP. Very Informative! Azure Machine Learning Datasets Learn all about Azure Datasets, why to use them, and how they help. Thanks for reading.
For more information, see Zeta Global’s home page. In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. Every Airflow task calls Amazon ECS tasks with some overrides.
Summary: Selecting the right ETL platform is vital for efficient data integration. Introduction In today’s data-driven world, businesses rely heavily on ETL platforms to streamline data integration processes. What is ETL in Data Integration? Let’s explore some real-world applications of ETL in different sectors.
Kafka And ETL Processing: You might be using Apache Kafka for high-performance data pipelines, stream various analytics data, or run company critical assets using Kafka, but did you know that you can also use Kafka clusters to move data between multiple systems. A three-step ETL framework job should do the trick.
The large volume of contacts creates a challenge for CSBA to extract key information from the transcripts that helps sellers promptly address customer needs and improve customer experience. We use multiple AWS AI/ML services, such as Contact Lens for Amazon Connect and Amazon SageMaker , and utilize a combined architecture.
Embeddings capture the information content in bodies of text, allowing natural language processing (NLP) models to work with language in a numeric form. This allows the LLM to reference more relevant information when generating a response. We can store that information and see how it changes over time.
In this post, we show you how SnapLogic , an AWS customer, used Amazon Bedrock to power their SnapGPT product through automated creation of these complex DSL artifacts from human language. SnapLogic background SnapLogic is an AWS customer on a mission to bring enterprise automation to the world.
Summary: This article explores the significance of ETL Data in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
Data is frequently kept in data lakes that can be managed by AWS Lake Formation , giving you the ability to implement fine-grained access control using a straightforward grant or revoke procedure. This data represents transaction data for products and includes information such as customer demographics, inventory, web sales, and promotions.
Writing data to an AWS data lake and retrieving it to populate an AWS RDS MS SQL database involves several AWS services and a sequence of steps for data transfer and transformation. This process leverages AWS S3 for the data lake storage, AWS Glue for ETL operations, and AWS Lambda for orchestration.
For more information, see Customize models in Amazon Bedrock with your own data using fine-tuning and continued pre-training. In the first step, an AWS Lambda function reads and validates the file, and extracts the raw data. The project is available on GitHub and provides AWS Cloud Development Kit (AWS CDK) code to deploy.
Through evaluations of sensors and informed decision-making support, Afri-SET empowers governments and civil society for effective air quality management. Additionally, they aim to report corrected data from low-cost sensors, which requires information beyond specific pollutants.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
We then discuss the various use cases and explore how you can use AWS services to clean the data, how machine learning (ML) can aid in this effort, and how you can make ethical use of the data in generating visuals and insights. For more information, refer to Common techniques to detect PHI and PII data using AWS Services.
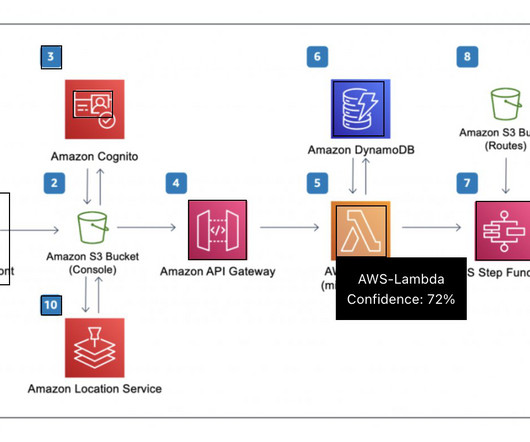
Between leading discussions, listening closely, and typing notes, it’s easy for key information to slip away unrecorded. The solution presented in this post is orchestrated using an AWS Step Functions state machine that is triggered when you upload a recording to the designated Amazon Simple Storage Service (Amazon S3) bucket.
The following figure shows an example diagram that illustrates an orchestrated extract, transform, and load (ETL) architecture solution. Identifying keywords such as use cases and industry verticals in these sources also allows the information to be captured and for more relevant search results to be displayed to the user.
By tapping into the power of cloud technology, organizations can efficiently analyze large datasets, uncover hidden patterns, predict future trends, and make informed decisions to drive their businesses forward. Descriptive analytics often involves data visualization techniques to present information in a more accessible format.
or lower) or in a custom environment, refer to appendix for more information. IAM role – SageMaker requires an AWS Identity and Access Management (IAM) role to be assigned to a SageMaker Studio domain or user profile to manage permissions effectively. You need to create AWS Glue connections with specific connection types.
Welcome to our AWS Redshift to the Snowflake Data Cloud migration blog! In this blog, we’ll walk you through the process of migrating your data from AWS Redshift to the Snowflake Data Cloud. One popular route is leveraging third-party ETL tools like Fivetran to ensure a smooth and successful migration.
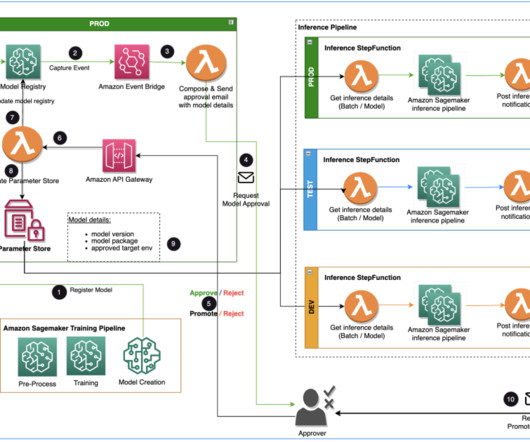
In this post, we discuss how the AWS AI/ML team collaborated with the Merck Human Health IT MLOps team to build a solution that uses an automated workflow for ML model approval and promotion with human intervention in the middle. A model developer typically starts to work in an individual ML development environment within Amazon SageMaker.
An approach to product stewardship with generative AI Large language models (LLMs) are trained with vast amounts of information crawled from the internet, capturing considerable knowledge from multiple domains. However, their knowledge is static and tied to the data used during the pre-training phase.
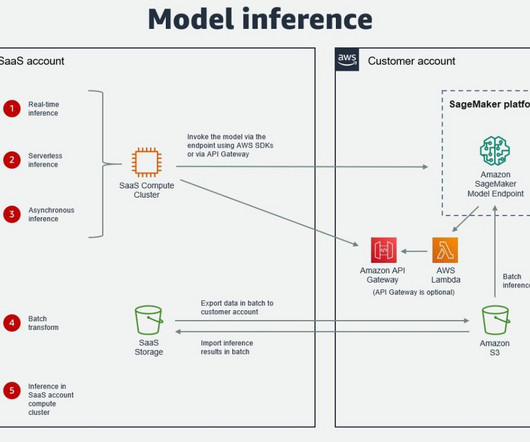
A number of AWS independent software vendor (ISV) partners have already built integrations for users of their software as a service (SaaS) platforms to utilize SageMaker and its various features, including training, deployment, and the model registry. In some cases, an ISV may deploy their software in the customer AWS account.
Tackling these challenges is key to effectively connecting readers with content they find informative and engaging. The following diagram illustrates the architecture of a news recommender application powered by Amazon Personalize and supporting AWS services.
Extraction, Transform, Load (ETL). AWS Glue helps users to build data catalogues, and Quicksight provides data visualisation and dashboard construction. The services from AWS can be catered to meet the needs of each business user. It allows users to organise, monitor and schedule ETL processes through the use of Python.
With the explosive growth of big data over the past decade and the daily surge in data volumes, it’s essential to have a resilient system to manage the vast influx of information without failures. Big data pipelines operate similarly to traditional ETL (Extract, Transform, Load) pipelines but are designed to handle much larger data volumes.
Thomson Reuters (TR) is one of the world’s most trusted information organizations for businesses and professionals. TR wanted to take advantage of AWS managed services where possible to simplify operations and reduce undifferentiated heavy lifting. The entire workflow is orchestrated using AWS Step Functions.
Optimized for analytical processing, it uses specialized data models to enhance query performance and is often integrated with business intelligence tools, allowing users to create reports and visualizations that inform organizational strategies. Pay close attention to the cost structure, including any potential hidden fees.
AWS provides several tools to create and manage ML model deployments. 2 If you are somewhat familiar with AWS ML base tools, the first thing that comes to mind is “Sagemaker”. AWS Sagemeaker is in fact a great tool for machine learning operations (MLOps) to automate and standardize processes across the ML lifecycle. S3 buckets.
In this post, we explore how AWS customer Pro360 used the Amazon Comprehend custom classification API , which enables you to easily build custom text classification models using your business-specific labels without requiring you to learn machine learning (ML), to improve customer experience and reduce operational costs.
Cloud platforms, such as Amazon Web Services (AWS), Microsoft Azure, or Google Cloud Platform (GCP), provide scalable and flexible infrastructure options. What makes the difference is a smart ETL design capturing the nature of process mining data. This article provides general information for process mining cost reduction.
We will explore the different options for data warehousing and how you can leverage this information to make the right decisions for your organization. Examples include: Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP). Understanding the Basics What is a Data Warehouse?
In this post, we discuss how CCC Intelligent Solutions (CCC) combined Amazon SageMaker with other AWS services to create a custom solution capable of hosting the types of complex artificial intelligence (AI) models envisioned. Step-by-step solution Step 1 A client makes a request to the AWS API Gateway endpoint.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content