This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
The solution proposed in this post relies on LLMs context learning capabilities and prompt engineering. It enables you to use an off-the-shelf model as is without involving machinelearning operations (MLOps) activity. To run the project code, make sure that you have fulfilled the AWS CDK prerequisites for Python.
Key Skills: Mastery in machinelearning frameworks like PyTorch or TensorFlow is essential, along with a solid foundation in unsupervised learning methods. Applied MachineLearning Scientist Description : Applied ML Scientists focus on translating algorithms into scalable, real-world applications.
Customers use Amazon Redshift as a key component of their data architecture to drive use cases from typical dashboarding to self-service analytics, real-time analytics, machinelearning (ML), data sharing and monetization, and more.
“Data is at the center of every application, process, and business decision,” wrote Swami Sivasubramanian, VP of Database, Analytics, and MachineLearning at AWS, and I couldn’t agree more. A common pattern customers use today is to build data pipelines to move data from Amazon Aurora to Amazon Redshift.
The ETL process is defined as the movement of data from its source to destination storage (typically a Data Warehouse) for future use in reports and analyzes. Understanding the ETL Process. Before you understand what is ETL tool , you need to understand the ETL Process first. Types of ETL Tools.
Communication between the two systems was established through Kerberized Apache Livy (HTTPS) connections over AWS PrivateLink. Data exploration and model development were conducted using well-known machinelearning (ML) tools such as Jupyter or Apache Zeppelin notebooks. Analytic data is stored in Amazon Redshift.
This post is co-authored by Anatoly Khomenko, MachineLearning Engineer, and Abdenour Bezzouh, Chief Technology Officer at Talent.com. In line with this mission, Talent.com collaborated with AWS to develop a cutting-edge job recommendation engine driven by deep learning, aimed at assisting users in advancing their careers.
These tools will help you streamline your machinelearning workflow, reduce operational overheads, and improve team collaboration and communication. Machinelearning (ML) is the technology that automates tasks and provides insights. It provides a large cluster of clusters on a single machine.
Lets assume that the question What date will AWS re:invent 2024 occur? The corresponding answer is also input as AWS re:Invent 2024 takes place on December 26, 2024. If the question was Whats the schedule for AWS events in December?, This setup uses the AWS SDK for Python (Boto3) to interact with AWS services.
These techniques utilize various machinelearning (ML) based approaches. In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience.
In this post, we explore how you can use Amazon Q Business , the AWS generative AI-powered assistant, to build a centralized knowledge base for your organization, unifying structured and unstructured datasets from different sources to accelerate decision-making and drive productivity. In this post, we use IAM Identity Center as the SAML 2.0-aligned
This post was written in collaboration with Bhajandeep Singh and Ajay Vishwakarma from Wipro’s AWS AI/ML Practice. Many organizations have been using a combination of on-premises and open source data science solutions to create and manage machinelearning (ML) models.
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. Zeta’s AI innovation is powered by a proprietary machinelearning operations (MLOps) system, developed in-house.
Statistical methods and machinelearning (ML) methods are actively developed and adopted to maximize the LTV. In this post, we share how Kakao Games and the Amazon MachineLearning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWS data and ML services such as AWS Glue and Amazon SageMaker.
These tools provide data engineers with the necessary capabilities to efficiently extract, transform, and load (ETL) data, build data pipelines, and prepare data for analysis and consumption by other applications. Amazon Redshift: Amazon Redshift is a cloud-based data warehousing service provided by Amazon Web Services (AWS).
Azure MachineLearning Datasets Learn all about Azure Datasets, why to use them, and how they help. AI Powered Speech Analytics for Amazon Connect This video walks thru the AWS products necessary for converting video to text, translating and performing basic NLP. Very Informative!
The solution: IBM databases on AWS To solve for these challenges, IBM’s portfolio of SaaS database solutions on Amazon Web Services (AWS), enables enterprises to scale applications, analytics and AI across the hybrid cloud landscape. Let’s delve into the database portfolio from IBM available on AWS.
In this post, we show you how SnapLogic , an AWS customer, used Amazon Bedrock to power their SnapGPT product through automated creation of these complex DSL artifacts from human language. SnapLogic background SnapLogic is an AWS customer on a mission to bring enterprise automation to the world.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machinelearning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
Photo by Caspar Camille Rubin on Unsplash AWS Athena is a serverless interactive query system. Go to the AWS Glue Console. Create a Glue Job to perform ETL operations on your data. Athena Setup Go to the AWS management console and open Athena. It means we dont need to manage any infrastructure behind them. That is it!!
Amazon SageMaker Data Wrangler reduces the time it takes to collect and prepare data for machinelearning (ML) from weeks to minutes. Data is frequently kept in data lakes that can be managed by AWS Lake Formation , giving you the ability to implement fine-grained access control using a straightforward grant or revoke procedure.
Although these traditional machinelearning (ML) approaches might perform decently in terms of accuracy, there are several significant advantages to adopting generative AI approaches. In the first step, an AWS Lambda function reads and validates the file, and extracts the raw data. The Step Functions workflow starts.
Summary: Selecting the right ETL platform is vital for efficient data integration. Introduction In today’s data-driven world, businesses rely heavily on ETL platforms to streamline data integration processes. What is ETL in Data Integration? Let’s explore some real-world applications of ETL in different sectors.
This post presents a solution that uses a workflow and AWS AI and machinelearning (ML) services to provide actionable insights based on those transcripts. We use multiple AWS AI/ML services, such as Contact Lens for Amazon Connect and Amazon SageMaker , and utilize a combined architecture.
Summary: This article explores the significance of ETL Data in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
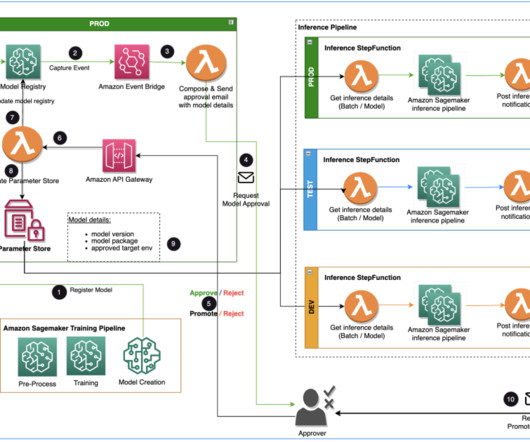
The large machinelearning (ML) model development lifecycle requires a scalable model release process similar to that of software development. The solution uses AWS Lambda , Amazon API Gateway , Amazon EventBridge , and SageMaker to automate the workflow with human approval intervention in the middle.
The embeddings are captured in Amazon Simple Storage Service (Amazon S3) via Amazon Kinesis Data Firehose , and we run a combination of AWS Glue extract, transform, and load (ETL) jobs and Jupyter notebooks to perform the embedding analysis. For more information about AWS CDK installation, refer to Getting started with the AWS CDK.
We then discuss the various use cases and explore how you can use AWS services to clean the data, how machinelearning (ML) can aid in this effort, and how you can make ethical use of the data in generating visuals and insights. For more information, refer to Common techniques to detect PHI and PII data using AWS Services.
First, it can be time consuming for users to learn multiple services development experiences. Second, because data, code, and other development artifacts like machinelearning (ML) models are stored within different services, it can be cumbersome for users to understand how they interact with each other and make changes.
On December 6 th -8 th 2023, the non-profit organization, Tech to the Rescue , in collaboration with AWS, organized the world’s largest Air Quality Hackathon – aimed at tackling one of the world’s most pressing health and environmental challenges, air pollution. As always, AWS welcomes your feedback.
Amazon Lookout for Metrics is a fully managed service that uses machinelearning (ML) to detect anomalies in virtually any time-series business or operational metrics—such as revenue performance, purchase transactions, and customer acquisition and retention rates—with no ML experience required. To learn more, see the documentation.
Generative AI empowers organizations to combine their data with the power of machinelearning (ML) algorithms to generate human-like content, streamline processes, and unlock innovation. He has more than 8 years of experience with big data and machinelearning projects in financial, retail, energy, and chemical industries.
Amazon SageMaker Studio provides a fully managed solution for data scientists to interactively build, train, and deploy machinelearning (ML) models. IAM role – SageMaker requires an AWS Identity and Access Management (IAM) role to be assigned to a SageMaker Studio domain or user profile to manage permissions effectively.
They cover a wide range of topics, ranging from Python, R, and statistics to machinelearning and data visualization. These bootcamps are focused training and learning platforms for people. Nowadays, individuals tend to opt for bootcamps for quick results and faster learning of any particular niche.
Machinelearning and AI analytics: Machinelearning and AI analytics leverage advanced algorithms to automate the analysis of data, discover hidden patterns, and make predictions. Downtime, like the AWS outage in 2017 that affected several high-profile websites, can disrupt business operations.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
This article will not explain how to deploy or train a machinelearning model. But it’s interoperable on any cloud like Azure, AWS or GCP. Machinelearning models are no exception and are subject to a natural evolutionary process. So it could happen that your machinelearning models become stale.
The solution presented in this post is orchestrated using an AWS Step Functions state machine that is triggered when you upload a recording to the designated Amazon Simple Storage Service (Amazon S3) bucket. Step Functions lets you create serverless workflows to orchestrate and connect components across AWS services.
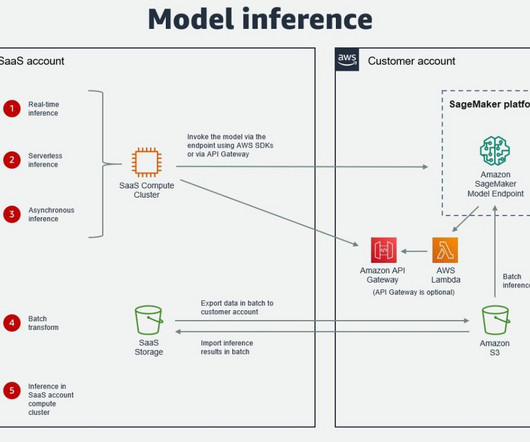
A number of AWS independent software vendor (ISV) partners have already built integrations for users of their software as a service (SaaS) platforms to utilize SageMaker and its various features, including training, deployment, and the model registry. In some cases, an ISV may deploy their software in the customer AWS account.
In this post, we discuss a machinelearning (ML) solution for complex image searches using Amazon Kendra and Amazon Rekognition. The following figure shows an example diagram that illustrates an orchestrated extract, transform, and load (ETL) architecture solution.
Image generated with Midjourney In today’s fast-paced world of data science, building impactful machinelearning models relies on much more than selecting the best algorithm for the job. Data scientists and machinelearning engineers need to collaborate to make sure that together with the model, they develop robust data pipelines.
The key requirement for TR’s new machinelearning (ML)-based personalization engine was centered around an accurate recommendation system that takes into account recent customer trends. TR wanted to take advantage of AWS managed services where possible to simplify operations and reduce undifferentiated heavy lifting.
It eliminates tedious, costly, and error-prone ETL (extract, transform, and load) jobs. SageMaker integration SageMaker is a fully managed service to prepare data and build, train, and deploy machinelearning (ML) models for any use case with fully managed infrastructure, tools, and workflows.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content