

Harmonize data using AWS Glue and AWS Lake Formation FindMatches ML to build a customer 360 view
JUNE 26, 2023
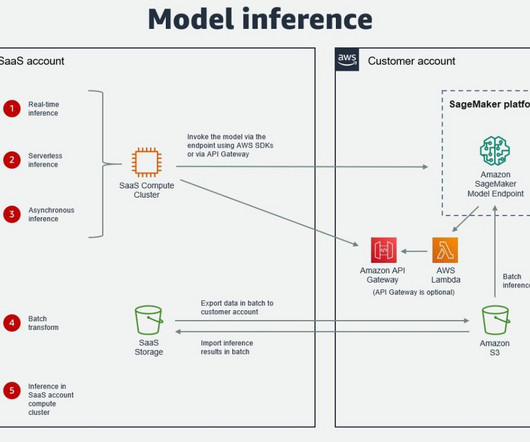
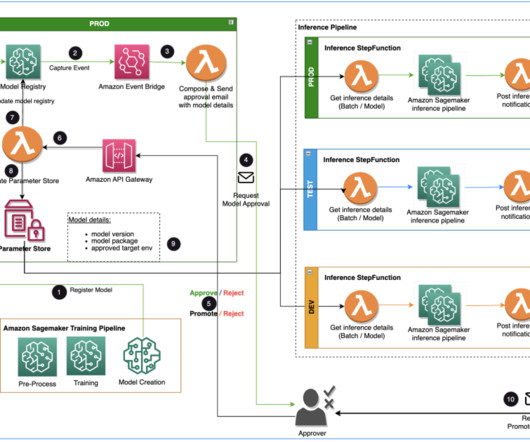
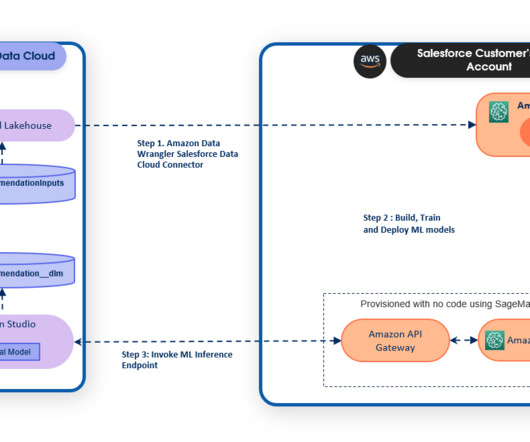
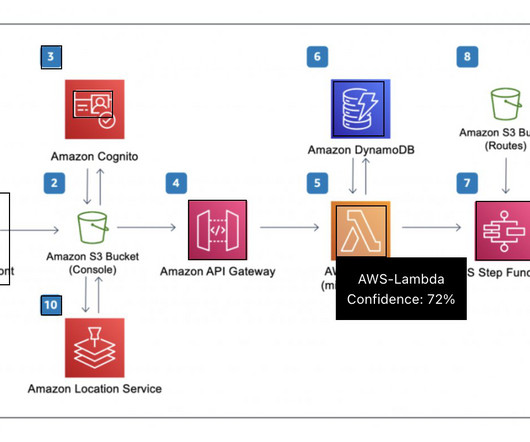
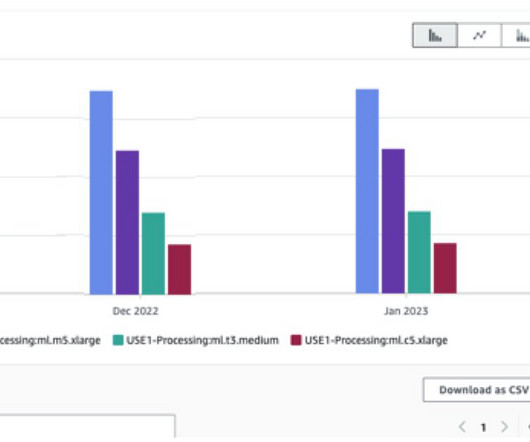
These techniques utilize various machine learning (ML) based approaches. In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience.












































Let's personalize your content