This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The post Basic Concept and Backend of AWS Elasticsearch appeared first on Analytics Vidhya. It is a Lucene-based search engine developed in Java but supports clients in various languages such as Python, C#, Ruby, and PHP. It takes unstructured data from multiple sources as input and stores it […].
Rockets legacy data science environment challenges Rockets previous data science solution was built around Apache Spark and combined the use of a legacy version of the Hadoop environment and vendor-provided Data Science Experience development tools. With the volume of business we do, even small improvements can have a significant impact.
Introduction Amazon Elastic MapReduce (EMR) is a fully managed service that makes it easy to process large amounts of data using the popular open-source framework Apache Hadoop. EMR enables you to run petabyte-scale data warehouses and analytics workloads using the Apache Spark, Presto, and Hadoop ecosystems.
Amazon Redshift: Amazon Redshift is a cloud-based data warehousing service provided by Amazon Web Services (AWS). It integrates seamlessly with other AWS services and supports various data integration and transformation workflows. Apache Hadoop An open-source framework for distributed storage and processing of large datasets.
Additionally, knowledge of cloud platforms (AWS, Google Cloud) and experience with deployment tools (Docker, Kubernetes) are highly valuable. Programming Questions Data science roles typically require knowledge of Python, SQL, R, or Hadoop. Prepare to discuss your experience and problem-solving abilities with these languages.
Extract : In this step, data is extracted from a vast array of sources present in different formats such as Flat Files, Hadoop Files, XML, JSON, etc. Here are few best Open-Source ETL tools on the market: Hadoop : Hadoop distinguishes itself as a general-purpose Distributed Computing platform.
Azure HDInsight now supports Apache analytics projects This announcement includes Spark, Hadoop, and Kafka. AWS DeepRacer 2020 Season is underway This looks to be a fun project. The service is awesome but used to be a bit spendy to try out. The frameworks in Azure will now have better security, performance, and monitoring.
Specify the AWS Lambda function that will interact with MongoDB Atlas and the LLM to provide responses. As always, AWS welcomes feedback. About the authors Igor Alekseev is a Senior Partner Solution Architect at AWS in Data and Analytics domain. Choose Build and after the build is successful, choose Test.
One common scenario that we’ve helped many clients with involves migrating data from Hive tables in a Hadoop environment to the Snowflake Data Cloud. You can easily set an EMR cluster on an AWS account using the following simple steps: Sign in to AWS Management Console and navigate to the EMR service. ap-southeast-2.compute.amazonaws.com
The main AWS services used are SageMaker, Amazon EMR , AWS CodeBuild , Amazon Simple Storage Service (Amazon S3), Amazon EventBridge , AWS Lambda , and Amazon API Gateway. With Amazon EMR, which provides fully managed environments like Apache Hadoop and Spark, we were able to process data faster.
Model training was accelerated by 50% through the use of the SMDDP library, which includes optimized communication algorithms designed specifically for AWS infrastructure. For SageMaker distributed training, the instances need to be in the same AWS Region and Availability Zone. days in AWS vs. 9 days on their legacy platform).
Familiarize yourself with essential data technologies: Data engineers often work with large, complex data sets, and it’s important to be familiar with technologies like Hadoop, Spark, and Hive that can help you process and analyze this data.
We used AWS services including Amazon Bedrock , Amazon SageMaker , and Amazon OpenSearch Serverless in this solution. In this series, we use the slide deck Train and deploy Stable Diffusion using AWS Trainium & AWS Inferentia from the AWS Summit in Toronto, June 2023 to demonstrate the solution. I need numbers."
The responsibilities of this phase can be handled with traditional databases (MySQL, PostgreSQL), cloud storage (AWS S3, Google Cloud Storage), and big data frameworks (Hadoop, Apache Spark). Data Storage and Management Once data have been collected from the sources, they must be secured and made accessible.
Hadoop Distributed File System (HDFS) : HDFS is a distributed file system designed to store vast amounts of data across multiple nodes in a Hadoop cluster. Amazon S3: Amazon Simple Storage Service (S3) is a scalable object storage service provided by Amazon Web Services (AWS).
Try out MongoDB Atlas Try out MongoDB Atlas Time Series Try out Amazon SageMaker Canvas Try out MongoDB Charts About the authors Igor Alekseev is a Senior Partner Solution Architect at AWS in Data and Analytics domain. In his role Igor is working with strategic partners helping them build complex, AWS-optimized architectures.
#The S3 Event Handler #TODO: Edit the AWS region #gg.eventhandler.s3.region= region= #TODO: Edit the AWS S3 bucket #gg.eventhandler.s3.bucketMappingTemplate= bucketMappingTemplate= #TODO:Set the classpath to include AWS Java SDK and Snowflake JDBC driver. jar #TODO:Set the AWS access key and secret key. gg.classpath=./snowflake-jdbc-3.13.7.jar:hadoop-3.2.1/share/hadoop/common/*:hadoop-3.2.1/share/hadoop/common/lib/*:hadoop-3.2.1/share/hadoop/hdfs/*:hadoop-3.2.1/share/
Cloud certifications, specifically in AWS and Microsoft Azure, were most strongly associated with salary increases. As we’ll see later, cloud certifications (specifically in AWS and Microsoft Azure) were the most popular and appeared to have the largest effect on salaries. The top certification was for AWS (3.9%
The Biggest Data Science Blogathon is now live! Knowledge is power. Sharing knowledge is the key to unlocking that power.”― Martin Uzochukwu Ugwu Analytics Vidhya is back with the largest data-sharing knowledge competition- The Data Science Blogathon.
Introduction You must have noticed the personalization happening in the digital world, from personalized Youtube videos to canny ad recommendations on Instagram. While not all of us are tech enthusiasts, we all have a fair knowledge of how Data Science works in our day-to-day lives. All of this is based on Data Science which is […].
Big Data technologies include Hadoop, Spark, and NoSQL databases. Big Data Technologies Enable Data Science at Scale Tools like Hadoop and Spark were developed specifically to handle the challenges of Big Data. Key Takeaways Big Data focuses on collecting, storing, and managing massive datasets.
Java is also widely used in big data technologies, supported by powerful Java-based tools like Apache Hadoop and Spark, which are essential for data processing in AI. Big Data Technologies With the growth of data-driven technologies, AI engineers must be proficient in big data platforms like Hadoop, Spark, and NoSQL databases.
Hey, are you the data science geek who spends hours coding, learning a new language, or just exploring new avenues of data science? If all of these describe you, then this Blogathon announcement is for you! Analytics Vidhya is back with its 28th Edition of blogathon, a place where you can share your knowledge about […].
Hello, fellow data science enthusiasts, did you miss imparting your knowledge in the previous blogathon due to a time crunch? Well, it’s okay because we are back with another blogathon where you can share your wisdom on numerous data science topics and connect with the community of fellow enthusiasts.
Hadoop, Snowflake, Databricks and other products have rapidly gained adoption. We will also address some of the key distinctions between platforms like Hadoop and Snowflake, which have emerged as valuable tools in the quest to process and analyze ever larger volumes of structured, semi-structured, and unstructured data.
Hadoop MapReduce, Amazon EMR, and Spark integration offer flexible deployment and scalability. In this section, well focus on three prominent solutions: Hadoop MapReduce, Amazon EMR, and the integration of Apache Spark. Hadoop MapReduce Hadoop MapReduce is the cornerstone of the Hadoop ecosystem.
Big data platforms such as Apache Hadoop and Spark help handle massive datasets efficiently. They must also stay updated on tools such as TensorFlow, Hadoop, and cloud-based platforms like AWS or Azure. Programming languages like Python and R are commonly used for data manipulation, visualization, and statistical modeling.
For example, if you want to sell on AWS marketplace , you will need to see what they expect from you. You need to use Hadoop tools to mine this data and find out more about your target customers and product requirements. Preparing your product will take lots of effort and planning, but it will also increase your chances of success.
Google’s Hadoop allowed for unlimited data storage on inexpensive servers, which we now call the Cloud. Searching for a topic on a search engine can provide us with a vast amount of information in seconds. Deighton studies how this evolution came to be. Innovations in the early 20th century changed how data could be used.
Most recently, JP Morgan built a ‘Mesh’ on AWS and locked its scalability fortune on a decentralized architecture. The Hadoop library enabled distributed processing across all points of data storage. More case studies are added every day and give a clear hint – data analytics are all set to change, again!
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























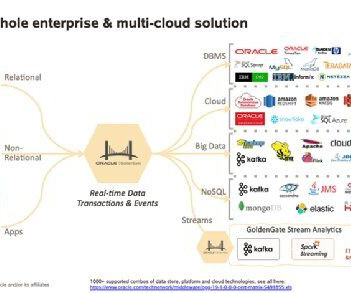



















Let's personalize your content