This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
But even as these models grow more powerful, they can only work with the information available to them. Its like having the worlds best analyst locked in a room with incomplete filesbrilliant, but isolated from your organizations most current and relevant information. What is the MCP?
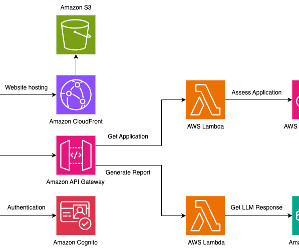
Amazon Textract is used to extract text information from the uploaded documents. The loan handler AWS Lambda function uses the information in the KYC documents to check the credit score and internal risk score. The notification Lambda function emails information about the loan application to the customer.
Powered by generative AI services on AWS and large language models (LLMs) multi-modal capabilities, HCLTechs AutoWise Companion provides a seamless and impactful experience. The solution is designed to provide customers with a detailed, personalized explanation of their preferred features, empowering them to make informed decisions.
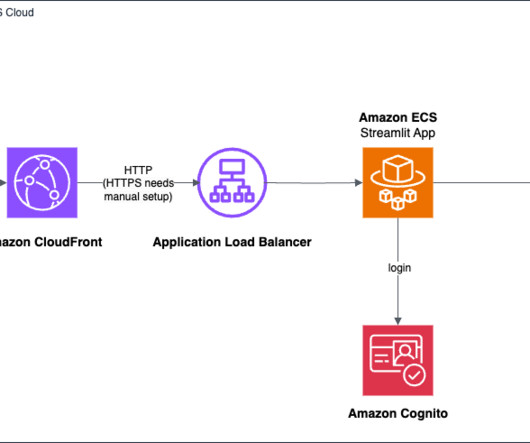
AWS provides a powerful set of tools and services that simplify the process of building and deploying generative AI applications, even for those with limited experience in frontend and backend development. The AWS deployment architecture makes sure the Python application is hosted and accessible from the internet to authenticated users.
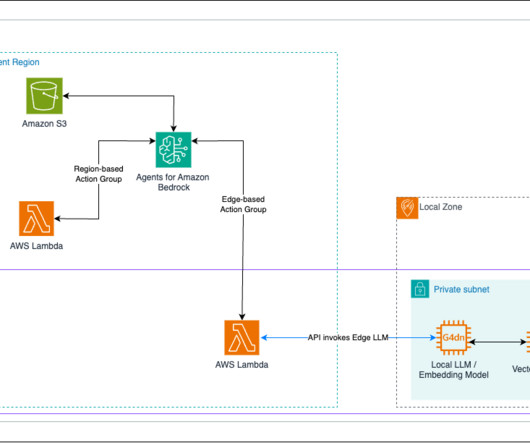
In this post, we show how to extend Amazon Bedrock Agents to hybrid and edge services such as AWS Outposts and AWS Local Zones to build distributed Retrieval Augmented Generation (RAG) applications with on-premises data for improved model outcomes.
To achieve these goals, the AWS Well-Architected Framework provides comprehensive guidance for building and improving cloud architectures. This allows teams to focus more on implementing improvements and optimizing AWS infrastructure. This systematic approach leads to more reliable and standardized evaluations.
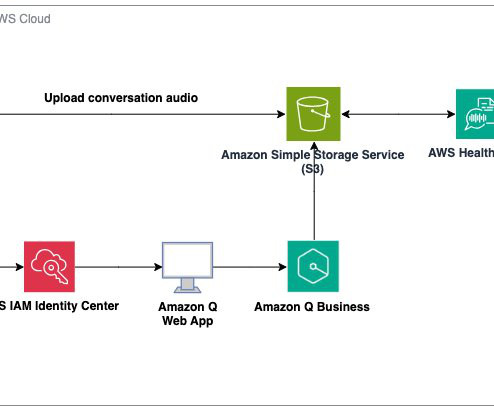
During re:Invent 2023, we launched AWS HealthScribe , a HIPAA eligible service that empowers healthcare software vendors to build their clinical applications to use speech recognition and generative AI to automatically create preliminary clinician documentation. AWS HealthScribe will then output two files which are also stored on Amazon S3.
Recognizing this need, we have developed a Chrome extension that harnesses the power of AWS AI and generative AI services, including Amazon Bedrock , an AWS managed service to build and scale generative AI applications with foundation models (FMs). The user signs in by entering a user name and a password.
Between monitoring, analyzing, and documenting architectural findings, a lack of crucial information can leave your organization vulnerable to potential risks and inefficiencies. Prerequisites For this walkthrough, the following are required: An AWS account. AWS Management Console access. A Python 3.12 environment.
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. Third, we’ll explore the robust infrastructure services from AWS powering AI innovation, featuring Amazon SageMaker , AWS Trainium , and AWS Inferentia under AI/ML, as well as Compute topics.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. You can use AWS services such as Application Load Balancer to implement this approach. Some applications may need to access data with personal identifiable information (PII) while others may rely on noncritical data.
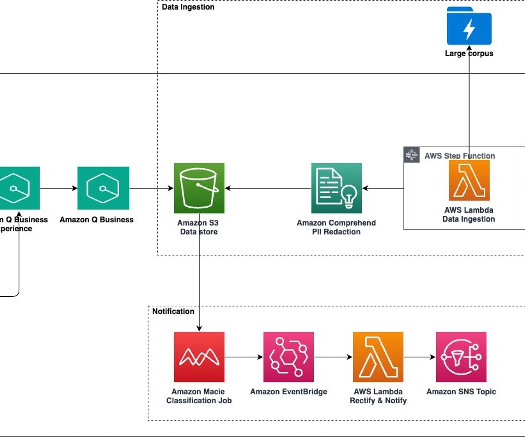
This wealth of content provides an opportunity to streamline access to information in a compliant and responsible way. Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles.
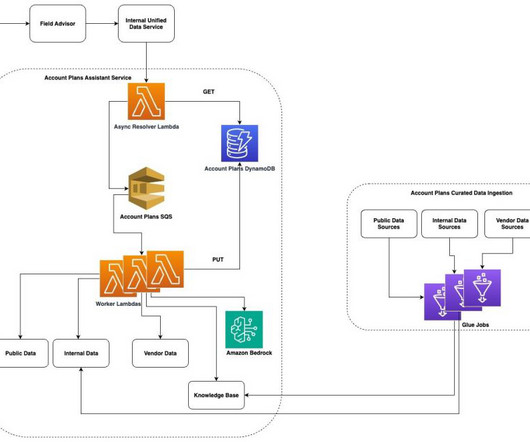
Earlier this year, we published the first in a series of posts about how AWS is transforming our seller and customer journeys using generative AI. Field Advisor serves four primary use cases: AWS-specific knowledge search With Amazon Q Business, weve made internal data sources as well as public AWS content available in Field Advisors index.
AWS Trainium and AWS Inferentia based instances, combined with Amazon Elastic Kubernetes Service (Amazon EKS), provide a performant and low cost framework to run LLMs efficiently in a containerized environment. For more information on how to view and increase your quotas, refer to Amazon EC2 service quotas.
It simplifies the often complex and time-consuming tasks involved in setting up and managing an MLflow environment, allowing ML administrators to quickly establish secure and scalable MLflow environments on AWS. AWS CodeArtifact , which provides a private PyPI repository so that SageMaker can use it to download necessary packages.
A reverse image search engine enables users to upload an image to find related information instead of using text-based queries. The AWS Command Line Interface (AWS CLI) installed on your machine to upload the dataset to Amazon S3. For more information on managing credentials securely, see the AWS Boto3 documentation.
To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023. In this blog post, we showcase how you can perform efficient supervised fine tuning for a Meta Llama 3 model using PEFT on AWS Trainium with SageMaker HyperPod. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
Every year, AWS Sales personnel draft in-depth, forward looking strategy documents for established AWS customers. These documents help the AWS Sales team to align with our customer growth strategy and to collaborate with the entire sales team on long-term growth ideas for AWS customers.
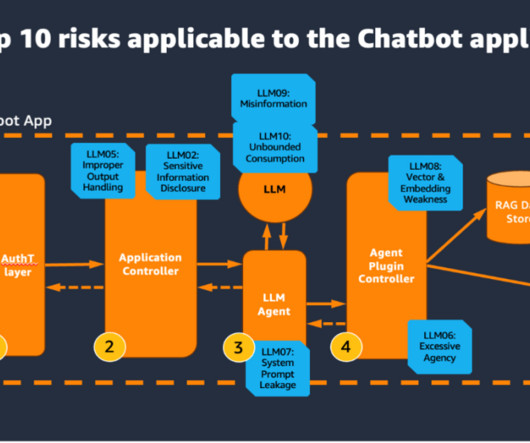
To address this need, AWS generative AI best practices framework was launched within AWS Audit Manager , enabling auditing and monitoring of generative AI applications. The agent then interprets the users request and determines if actions need to be invoked or information needs to be retrieved from a knowledge base.
Were excited to announce the open source release of AWS MCP Servers for code assistants a suite of specialized Model Context Protocol (MCP) servers that bring Amazon Web Services (AWS) best practices directly to your development workflow. This post is the first in a series covering AWS MCP Servers.
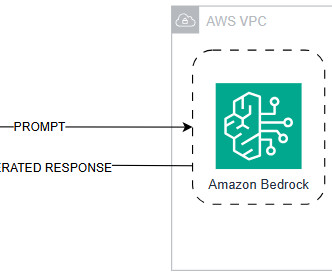
Because Amazon Bedrock is serverless, you don’t have to manage any infrastructure, and you can securely integrate and deploy generative AI capabilities into your applications using the AWS services you are already familiar with. client( service_name="bedrock-runtime", region_name="us-east-1" ) Define the model to invoke using its model ID.
The potential for such large business value is galvanizing tens of thousands of enterprises to build their generative AI applications in AWS. This post addresses these cost considerations so you can optimize your generative AI costs in AWS. The costs, limits, and models can change over time.
This post discusses how to use AWS Step Functions to efficiently coordinate multi-step generative AI workflows, such as parallelizing API calls to Amazon Bedrock to quickly gather answers to lists of submitted questions.
For example, a marketing content creation application might need to perform task types such as text generation, text summarization, sentiment analysis, and information extraction as part of producing high-quality, personalized content. Each distinct task type will likely require a separate LLM, which might also be fine-tuned with custom data.
Previously, setting up a custom labeling job required specifying two AWS Lambda functions: a pre-annotation function, which is run on each dataset object before it’s sent to workers, and a post-annotation function, which is run on the annotations of each dataset object and consolidates multiple worker annotations if needed.
Rufus is an AI-powered shopping assistant designed to help customers make informed purchasing decisions. This post focuses on how the QP model used draft centric speculative decoding (SD)also called parallel decodingwith AWS AI chips to meet the demands of Prime Day. Rufus extended the base LLM with multiple decoding heads.
Syngenta and AWS collaborated to develop Cropwise AI , an innovative solution powered by Amazon Bedrock Agents , to accelerate their sales reps’ ability to place Syngenta seed products with growers across North America. For sales representatives, it empowers them with deeper insights, enabling more informed recommendations.
Investment professionals face the mounting challenge of processing vast amounts of data to make timely, informed decisions. This challenge is particularly acute in credit markets, where the complexity of information and the need for quick, accurate insights directly impacts investment outcomes.
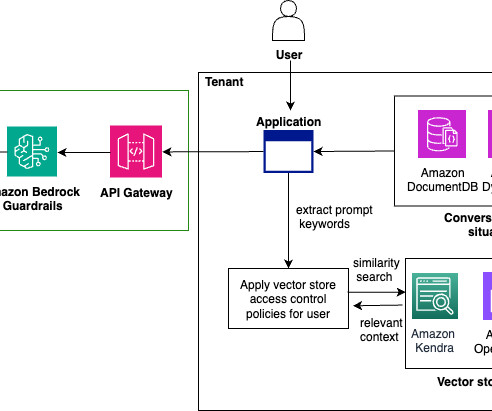
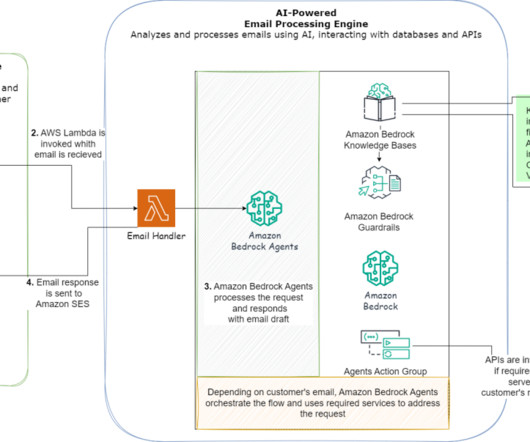
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. The following figure illustrates the high-level design of the solution.
In this post, we share how Amazon Web Services (AWS) is helping Scuderia Ferrari HP develop more accurate pit stop analysis techniques using machine learning (ML). Since implementing the solution with AWS, track operations engineers can synchronize the data up to 80% faster than manual methods.
Amazon Bedrock offers a serverless experience so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using AWS tools without having to manage infrastructure. This can lead to inefficiencies, delays, and errors, diminishing customer satisfaction.
Using vLLM on AWS Trainium and Inferentia makes it possible to host LLMs for high performance inference and scalability. Deploy vLLM on AWS Trainium and Inferentia EC2 instances In these sections, you will be guided through using vLLM on an AWS Inferentia EC2 instance to deploy Meta’s newest Llama 3.2 You will use inf2.xlarge
Theyre constantly seeking ways to use their vast amounts of information to gain competitive advantages. This post explores how OMRON Europe is using Amazon Web Services (AWS) to build its advanced ODAP and its progress toward harnessing the power of generative AI. Data is one of the most critical assets of many organizations.
These indexes enable efficient searching and retrieval of part data and vehicle information, providing quick and accurate results. The agents also automatically call APIs to perform actions and access knowledge bases to provide additional information.
Use the AWS generative AI scoping framework to understand the specific mix of the shared responsibility for the security controls applicable to your application. The following figure of the AWS Generative AI Security Scoping Matrix summarizes the types of models for each scope.
Amazon Q Business , a new generative AI-powered assistant, can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in an enterprises systems. Then we introduce the solution deployment using three AWS CloudFormation templates.
Seamless integration of latest foundation models (FMs), Prompts, Agents, Knowledge Bases, Guardrails, and other AWS services. Complete execution path information showing input, output, execution time, and errors for each node. Set up your knowledge base with relevant customer service documentation, FAQs, and product information.
ByteDance is a technology company that operates a range of content platforms to inform, educate, entertain, and inspire people across languages, cultures, and geographies. Cross-modal attention mechanisms facilitate information exchange between modalities, and fusion layers combine representations from different modalities.
Additionally, sensitive information filters can be applied to protect personally identifiable information (PII) from being incorporated into generated images. Word filters can be set up to detect and block specific phrases or terms that may lead to undesirable image outputs.
For a multi-account environment, you can track costs at an AWS account level to associate expenses. A combination of an AWS account and tags provides the best results. Implement a tagging strategy A tag is a label you assign to an AWS resource. The AWS reserved prefix aws: tags provide additional metadata tracked by AWS.
Scaling and load balancing The gateway can handle load balancing across different servers, model instances, or AWS Regions so that applications remain responsive. The AWS Solutions Library offers solution guidance to set up a multi-provider generative AI gateway. Leave us a comment and we will be glad to collaborate.
AWS has always provided customers with choice. In terms of hardware choice, in addition to NVIDIA GPUs and AWS custom AI chips, CPU-based instances represent (thanks to the latest innovations in CPU hardware) an additional choice for customers who want to run generative AI inference, like hosting small language models and asynchronous agents.
In this post, we demonstrate a solution using Amazon Elastic Kubernetes Service (EKS) with Amazon Bedrock to build scalable and containerized RAG solutions for your generative AI applications on AWS while bringing your unstructured user file data to Amazon Bedrock in a straightforward, fast, and secure way. Sonnet on Amazon Bedrock.
The AWS DeepRacer League is the worlds first autonomous racing league, open to anyone. In December 2024, AWS launched the AWS Large Language Model League (AWS LLM League) during re:Invent 2024. Response quality : Depth, accuracy, and contextual understanding.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content