This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the field of information technology, a container is like a typical container you could encounter in daily life. The post AWS ECS- Amazon’s Container Tool appeared first on Analytics Vidhya. Introduction We may have heard much about using Containers in IT, especially in Cloud environments. It only holds […].
Medical Interoperability is the ability to integrate and share secure healthcare information promptly across multiple systems. The post Population Health Analytics with AWS HealthLake and QuickSight appeared first on Analytics Vidhya. Medical Interoperability along with AI & Machine Learning […].
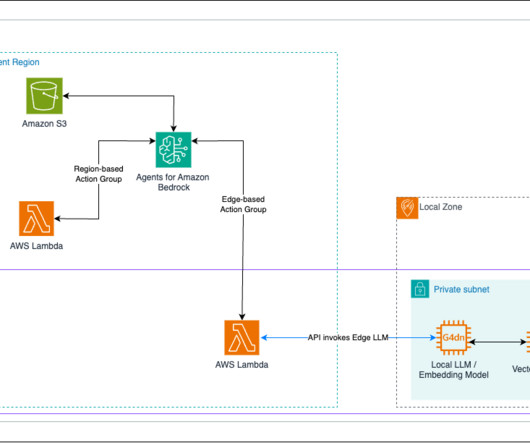
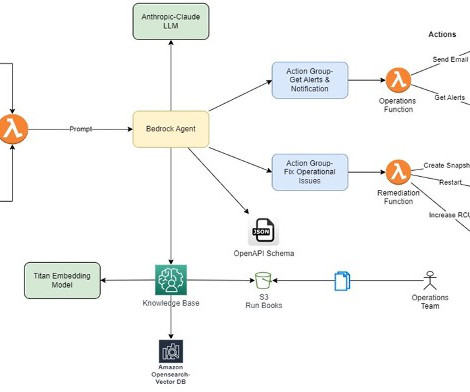
In this post, we show how to extend Amazon Bedrock Agents to hybrid and edge services such as AWS Outposts and AWS Local Zones to build distributed Retrieval Augmented Generation (RAG) applications with on-premises data for improved model outcomes.
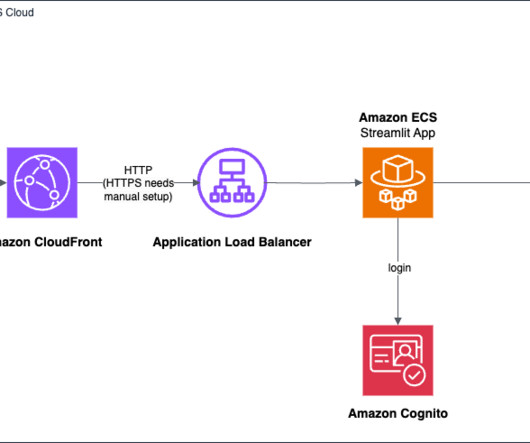
AWS provides a powerful set of tools and services that simplify the process of building and deploying generative AI applications, even for those with limited experience in frontend and backend development. The AWS deployment architecture makes sure the Python application is hosted and accessible from the internet to authenticated users.
This wealth of content provides an opportunity to streamline access to information in a compliant and responsible way. Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles.
Recognizing this need, we have developed a Chrome extension that harnesses the power of AWS AI and generative AI services, including Amazon Bedrock , an AWS managed service to build and scale generative AI applications with foundation models (FMs). The user signs in by entering a user name and a password.
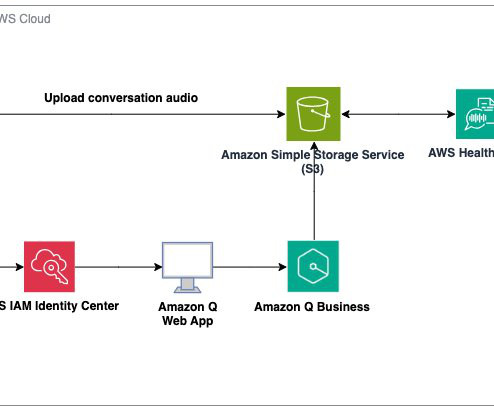
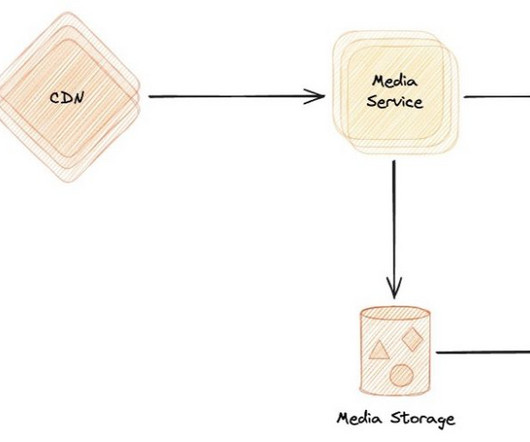
During re:Invent 2023, we launched AWS HealthScribe , a HIPAA eligible service that empowers healthcare software vendors to build their clinical applications to use speech recognition and generative AI to automatically create preliminary clinician documentation. AWS HealthScribe will then output two files which are also stored on Amazon S3.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. You can use AWS services such as Application Load Balancer to implement this approach. Some applications may need to access data with personal identifiable information (PII) while others may rely on noncritical data.
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. Third, we’ll explore the robust infrastructure services from AWS powering AI innovation, featuring Amazon SageMaker , AWS Trainium , and AWS Inferentia under AI/ML, as well as Compute topics.
AWS Trainium and AWS Inferentia based instances, combined with Amazon Elastic Kubernetes Service (Amazon EKS), provide a performant and low cost framework to run LLMs efficiently in a containerized environment. For more information on how to view and increase your quotas, refer to Amazon EC2 service quotas.
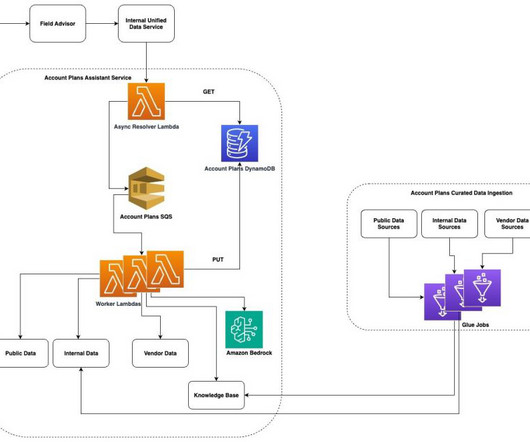
Earlier this year, we published the first in a series of posts about how AWS is transforming our seller and customer journeys using generative AI. Field Advisor serves four primary use cases: AWS-specific knowledge search With Amazon Q Business, weve made internal data sources as well as public AWS content available in Field Advisors index.
Amazon Q Business , a new generative AI-powered assistant, can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in an enterprises systems. Then we introduce the solution deployment using three AWS CloudFormation templates.
Every year, AWS Sales personnel draft in-depth, forward looking strategy documents for established AWS customers. These documents help the AWS Sales team to align with our customer growth strategy and to collaborate with the entire sales team on long-term growth ideas for AWS customers.
A reverse image search engine enables users to upload an image to find related information instead of using text-based queries. The AWS Command Line Interface (AWS CLI) installed on your machine to upload the dataset to Amazon S3. For more information on managing credentials securely, see the AWS Boto3 documentation.
Syngenta and AWS collaborated to develop Cropwise AI , an innovative solution powered by Amazon Bedrock Agents , to accelerate their sales reps’ ability to place Syngenta seed products with growers across North America. For sales representatives, it empowers them with deeper insights, enabling more informed recommendations.
To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023. In this blog post, we showcase how you can perform efficient supervised fine tuning for a Meta Llama 3 model using PEFT on AWS Trainium with SageMaker HyperPod. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
Amazon Bedrock offers a serverless experience so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using AWS tools without having to manage infrastructure. This can lead to inefficiencies, delays, and errors, diminishing customer satisfaction.
8B and 70B inference support on AWS Trainium and AWS Inferentia instances in Amazon SageMaker JumpStart. Trainium and Inferentia, enabled by the AWS Neuron software development kit (SDK), offer high performance and lower the cost of deploying Meta Llama 3.1 An AWS Identity and Access Management (IAM) role to access SageMaker.
It simplifies the often complex and time-consuming tasks involved in setting up and managing an MLflow environment, allowing ML administrators to quickly establish secure and scalable MLflow environments on AWS. AWS CodeArtifact , which provides a private PyPI repository so that SageMaker can use it to download necessary packages.
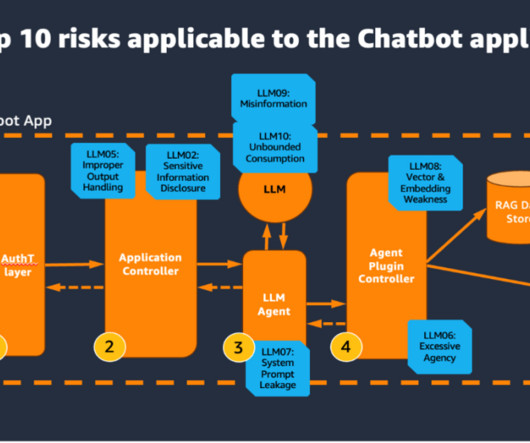
Use the AWS generative AI scoping framework to understand the specific mix of the shared responsibility for the security controls applicable to your application. The following figure of the AWS Generative AI Security Scoping Matrix summarizes the types of models for each scope.
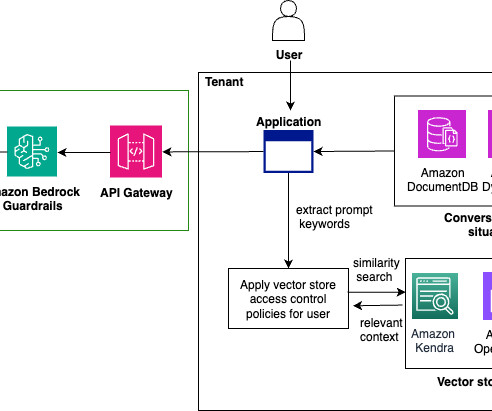
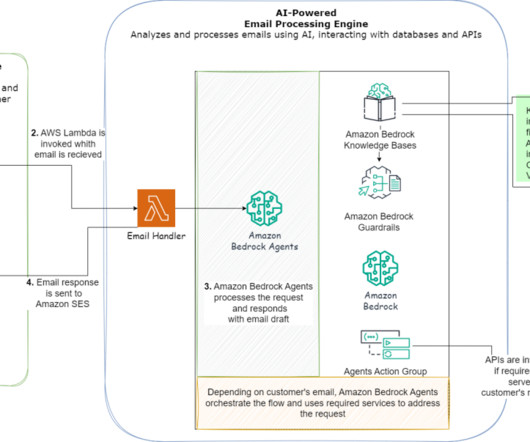
Seamless integration of latest foundation models (FMs), Prompts, Agents, Knowledge Bases, Guardrails, and other AWS services. Complete execution path information showing input, output, execution time, and errors for each node. Set up your knowledge base with relevant customer service documentation, FAQs, and product information.
This post presents a comprehensive AIOps solution that combines various AWS services such as Amazon Bedrock , AWS Lambda , and Amazon CloudWatch to create an AI assistant for effective incident management. The solution provides sample AWS Cloud Development Kit (AWS CDK) code to deploy this solution.
Theyre constantly seeking ways to use their vast amounts of information to gain competitive advantages. This post explores how OMRON Europe is using Amazon Web Services (AWS) to build its advanced ODAP and its progress toward harnessing the power of generative AI. Data is one of the most critical assets of many organizations.
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. The following figure illustrates the high-level design of the solution.
These indexes enable efficient searching and retrieval of part data and vehicle information, providing quick and accurate results. The agents also automatically call APIs to perform actions and access knowledge bases to provide additional information.
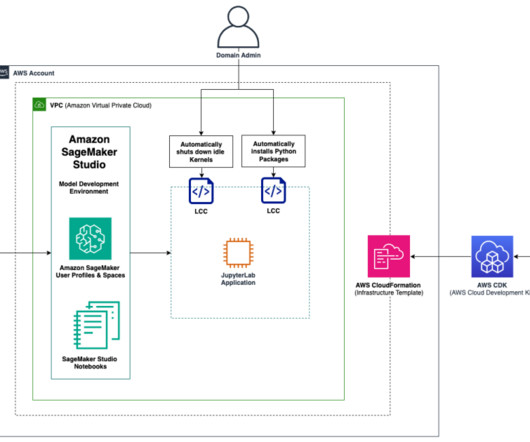
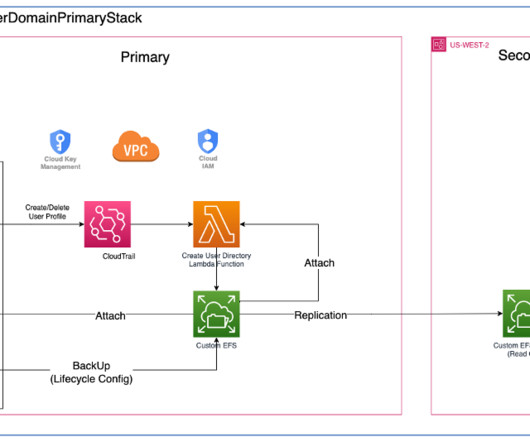
Solution overview The solution constitutes a best-practice Amazon SageMaker domain setup with a configurable list of domain user profiles and a shared SageMaker Studio space using the AWS Cloud Development Kit (AWS CDK). The AWS CDK is a framework for defining cloud infrastructure as code. The AWS CDK installed.
This post discusses how to use AWS Step Functions to efficiently coordinate multi-step generative AI workflows, such as parallelizing API calls to Amazon Bedrock to quickly gather answers to lists of submitted questions.
Using vLLM on AWS Trainium and Inferentia makes it possible to host LLMs for high performance inference and scalability. Deploy vLLM on AWS Trainium and Inferentia EC2 instances In these sections, you will be guided through using vLLM on an AWS Inferentia EC2 instance to deploy Meta’s newest Llama 3.2 You will use inf2.xlarge
We provide additional information later in this post. Solution overview The following diagram illustrates the ML platform reference architecture using various AWS services. For more information about the architecture in detail, refer to Part 1 of this series. We discuss this in more detail later in this post.
The company developed an automated solution called Call Quality (CQ) using AI services from Amazon Web Services (AWS). In this post, we demonstrate how the CQ solution used Amazon Transcribe and other AWS services to improve critical KPIs with AI-powered contact center call auditing and analytics.
Investment professionals face the mounting challenge of processing vast amounts of data to make timely, informed decisions. This challenge is particularly acute in credit markets, where the complexity of information and the need for quick, accurate insights directly impacts investment outcomes.
Additionally, sensitive information filters can be applied to protect personally identifiable information (PII) from being incorporated into generated images. Word filters can be set up to detect and block specific phrases or terms that may lead to undesirable image outputs.
ByteDance is a technology company that operates a range of content platforms to inform, educate, entertain, and inspire people across languages, cultures, and geographies. Cross-modal attention mechanisms facilitate information exchange between modalities, and fusion layers combine representations from different modalities.
Dynamic content, including user-specific information, should be placed at the end of the prompt. n - Select quotes that provide key information, context, or support for the answer." n - Provide a clear, concise, and accurate answer to the question based on the information in the document." "n 2][3]'" "nn5.
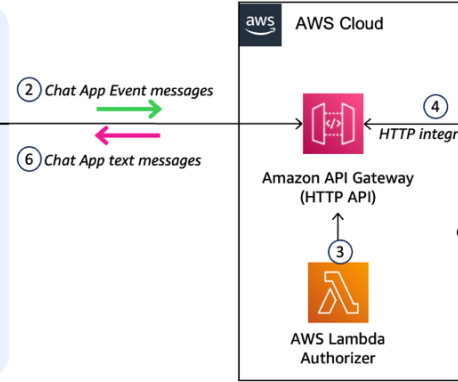
The solution workflow consists of the following steps: The user accesses a smart search portal and lands on a web interface deployed on AWS Amplify. The API is integrated with AWS Lambda , which processes the user query and generates the answers based on available documents and user access using retrieval augmented generation (RAG).
Refer to Supported Regions and models for batch inference for current supporting AWS Regions and models. To address this consideration and enhance your use of batch inference, we’ve developed a scalable solution using AWS Lambda and Amazon DynamoDB. Amazon S3 invokes the {stack_name}-create-batch-queue-{AWS-Region} Lambda function.
We show how to then prepare the fine-tuned model to run on AWS Inferentia2 powered Amazon EC2 Inf2 instances , unlocking superior price performance for your inference workloads. After the model is fine-tuned, you can compile and host the fine-tuned SDXL on Inf2 instances using the AWS Neuron SDK. An Amazon Web Services (AWS) account.
Research papers and engineering documents often contain a wealth of information in the form of mathematical formulas, charts, and graphs. Navigating these unstructured documents to find relevant information can be a tedious and time-consuming task, especially when dealing with large volumes of data.
Amazon SageMaker is a cloud-based machine learning (ML) platform within the AWS ecosystem that offers developers a seamless and convenient way to build, train, and deploy ML models. For more information about this architecture, see New – Code Editor, based on Code-OSS VS Code Open Source now available in Amazon SageMaker Studio.
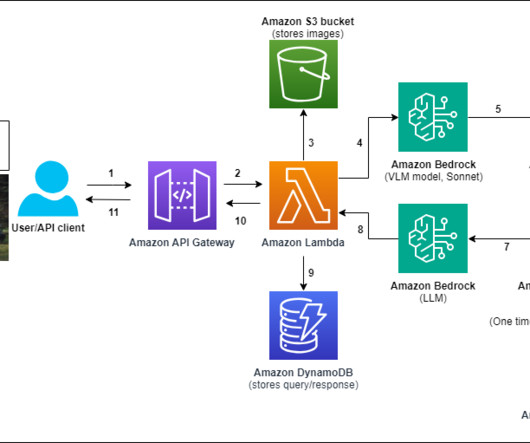
These models are designed to understand and generate text about images, bridging the gap between visual information and natural language. After the documents are ingested in OpenSearch Service (this is a one-time setup step), we deploy the full end-to-end multimodal chat assistant using an AWS CloudFormation template.
Analysts can use this information to provide incentives to buyers and sellers who frequently use the site, to attract new users, and to drive advertising and promotions. To implement this solution, complete the following steps: Set up Zero-ETL integration from the AWS Management Console for Amazon Relational Database Service (Amazon RDS).
Hybrid architecture with AWS Local Zones To minimize the impact of network latency on TTFT for users regardless of their locations, a hybrid architecture can be implemented by extending AWS services from commercial Regions to edge locations closer to end users. Next, create a subnet inside each Local Zone. Amazon Linux 2).
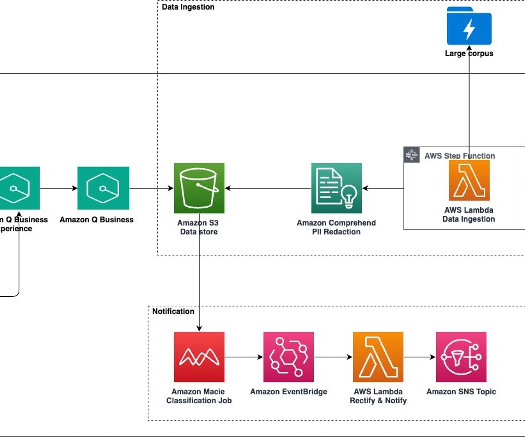
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset data model. Unstructured information may have a little or a lot of structure but in ways that are unexpected or inconsistent. Additionally, we show how to use AWS AI/ML services for analyzing unstructured data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content