This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
But even as these models grow more powerful, they can only work with the information available to them. Its like having the worlds best analyst locked in a room with incomplete filesbrilliant, but isolated from your organizations most current and relevant information. What is the MCP?
Why generative AI is best suited for assistants that support customer journeys Traditional AI assistants that use rules-based navigation or naturallanguageprocessing (NLP) based guidance fall short when handling the nuances of complex human conversations. Always ask for relevant information and avoid making assumptions.
However, as the reach of live streams expands globally, language barriers and accessibility challenges have emerged, limiting the ability of viewers to fully comprehend and participate in these immersive experiences. The extension delivers a web application implemented using the AWS SDK for JavaScript and the AWS Amplify JavaScript library.
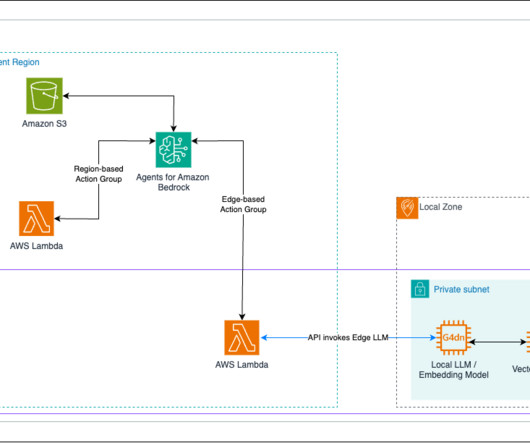
In this post, we show how to extend Amazon Bedrock Agents to hybrid and edge services such as AWS Outposts and AWS Local Zones to build distributed Retrieval Augmented Generation (RAG) applications with on-premises data for improved model outcomes.
This wealth of content provides an opportunity to streamline access to information in a compliant and responsible way. Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles.
Because Amazon Bedrock is serverless, you don’t have to manage any infrastructure, and you can securely integrate and deploy generative AI capabilities into your applications using the AWS services you are already familiar with. client( service_name="bedrock-runtime", region_name="us-east-1" ) Define the model to invoke using its model ID.
Syngenta and AWS collaborated to develop Cropwise AI , an innovative solution powered by Amazon Bedrock Agents , to accelerate their sales reps’ ability to place Syngenta seed products with growers across North America. Cropwise AI Cropwise AI transforms the seed selection process in several powerful ways.
Large language models (LLMs) have transformed naturallanguageprocessing (NLP), yet converting conversational queries into structured data analysis remains complex. Amazon Bedrock Knowledge Bases enables direct naturallanguage interactions with structured data sources.
8B and 70B inference support on AWS Trainium and AWS Inferentia instances in Amazon SageMaker JumpStart. multilingual large language models (LLMs) are a collection of pre-trained and instruction tuned generative models. An AWS Identity and Access Management (IAM) role to access SageMaker. Meta Llama 3.1 by up to 50%.
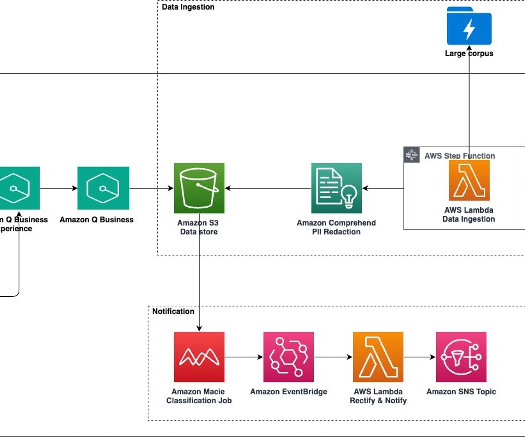
Amazon Q Business , a new generative AI-powered assistant, can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in an enterprises systems. These tasks often involve processing vast amounts of documents, which can be time-consuming and labor-intensive.
Previously, setting up a custom labeling job required specifying two AWS Lambda functions: a pre-annotation function, which is run on each dataset object before it’s sent to workers, and a post-annotation function, which is run on the annotations of each dataset object and consolidates multiple worker annotations if needed.
Step 1: Cover the Fundamentals You can skip this step if you already know the basics of programming, machine learning, and naturallanguageprocessing. Step 2: Understand Core Architectures Behind Large Language Models Large language models rely on various architectures, with transformers being the most prominent foundation.
Investment professionals face the mounting challenge of processing vast amounts of data to make timely, informed decisions. This challenge is particularly acute in credit markets, where the complexity of information and the need for quick, accurate insights directly impacts investment outcomes.
Large language models (LLMs) have revolutionized the field of naturallanguageprocessing, enabling machines to understand and generate human-like text with remarkable accuracy. However, despite their impressive language capabilities, LLMs are inherently limited by the data they were trained on.
As organizations look to incorporate AI capabilities into their applications, large language models (LLMs) have emerged as powerful tools for naturallanguageprocessing tasks. AWS has always provided customers with choice. That includes model choice, hardware choice, and tooling choice.
By narrowing down the search space to the most relevant documents or chunks, metadata filtering reduces noise and irrelevant information, enabling the LLM to focus on the most relevant content. This approach can also enhance the quality of retrieved information and responses generated by the RAG applications.
Virtual Agent: Thats great, please say your 5 character booking reference, you will find it at the top of the information pack we sent. Virtual Agent: Thats great, please say your 5 character booking reference, you will find it at the top of the information pack we sent. Customer: Id like to check my booking. Please say yes or no.
Extracting information from unstructured documents at scale is a recurring business task. A classic approach to extracting information from text is named entity recognition (NER). This post presents an end-to-end IDP application powered by Amazon Bedrock Data Automation and other AWS services.
Today, we’re excited to share the journey of the VW —an innovator in the automotive industry and Europe’s largest car maker—to enhance knowledge management by using generative AI , Amazon Bedrock , and Amazon Kendra to devise a solution based on Retrieval Augmented Generation (RAG) that makes internal information more easily accessible by its users.
Home Table of Contents Build a Search Engine: Setting Up AWS OpenSearch Introduction What Is AWS OpenSearch? What AWS OpenSearch Is Commonly Used For Key Features of AWS OpenSearch How Does AWS OpenSearch Work? Why Use AWS OpenSearch for Semantic Search? Looking for the source code to this post?
The banking industry has long struggled with the inefficiencies associated with repetitive processes such as information extraction, document review, and auditing. To address these inefficiencies, the implementation of advanced information extraction systems is crucial.
John Snow Labs’ Medical Language Models is by far the most widely used naturallanguageprocessing (NLP) library by practitioners in the healthcare space (Gradient Flow, The NLP Industry Survey 2022 and the Generative AI in Healthcare Survey 2024 ). For more information, refer to Shut down and Update Studio Classic Apps.
While these models are trained on vast amounts of generic data, they often lack the organization-specific context and up-to-date information needed for accurate responses in business settings. Lets assume that the question What date will AWS re:invent 2024 occur? If the question was Whats the schedule for AWS events in December?,
From predicting traffic flow to sales forecasting, accurate predictions enable organizations to make informed decisions, mitigate risks, and allocate resources efficiently. By the end of this journey, you will be equipped to streamline your development process and apply Chronos to any time series data, transforming your forecasting approach.
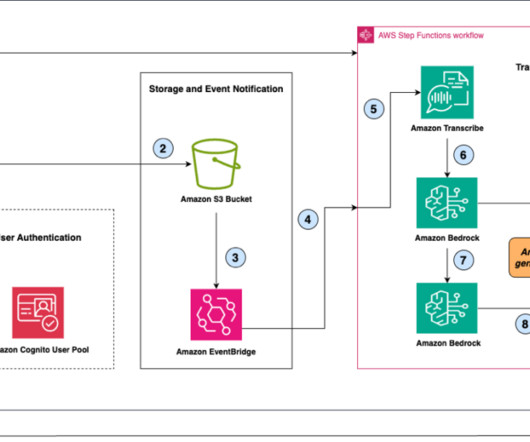
In the following sections, we walk you through constructing a scalable, serverless, end-to-end Public Speaking Mentor AI Assistant with Amazon Bedrock, Amazon Transcribe , and AWS Step Functions using provided sample code. The generative AI capabilities of Amazon Bedrock efficiently process user speech inputs.
This post details our technical implementation using AWS services to create a scalable, multilingual AI assistant system that provides automated assistance while maintaining data security and GDPR compliance. In the process of implementation, we discovered that Anthropics Claude 3.5 Amazon Titan Embeddings G1 Text v1.2
Precise), an Amazon Web Services (AWS) Partner , participated in the AWS Think Big for Small Business Program (TBSB) to expand their AWS capabilities and to grow their business in the public sector. The platform helped the agency digitize and process forms, pictures, and other documents. Precise Software Solutions, Inc.
While the cascaded models approach outlined in Part 1 is flexible and modular, it requires orchestration of automatic speech recognition (ASR), naturallanguageprocessing (NLU), and text-to-speech (TTS) models. The local application will uses AWS services and Daily through IAM and API credentials.
In doing so, organizations face the challenges of accessing and analyzing information scattered across multiple data sources. Consolidating and querying these disparate datasets can be a complex and time-consuming task, requiring developers to navigate different data formats, query languages, and access mechanisms.
At AWS, we believe the long-term success of AI depends on the ability to inspire trust among users, customers, and society. Achieving ISO/IEC 42001 certification means that an independent third party has validated that AWS is taking proactive steps to manage risks and opportunities associated with AI development, deployment, and operation.
The integration of modern naturallanguageprocessing (NLP) and LLM technologies enhances metadata accuracy, enabling more precise search functionality and streamlined document management. In this post, we discuss how you can build an AI-powered document processing platform with open source NER and LLMs on SageMaker.
This solution uses decorators in your application code to capture and log metadata such as input prompts, output results, run time, and custom metadata, offering enhanced security, ease of use, flexibility, and integration with native AWS services.
By taking advantage of advanced naturallanguageprocessing (NLP) capabilities and data analysis techniques, you can streamline common tasks like these in the financial industry: Automating data extraction – The manual data extraction process to analyze financial statements can be time-consuming and prone to human errors.
Amazon Web Services (AWS) addresses this gap with Amazon SageMaker Canvas , a low-code ML service that simplifies model development and deployment. You can use time-series forecasting to generate donation predictions and make informed decisions on budget plannings. It supports multiple predictive problem types.
In this post, we explore how to deploy distilled versions of DeepSeek-R1 with Amazon Bedrock Custom Model Import, making them accessible to organizations looking to use state-of-the-art AI capabilities within the secure and scalable AWS infrastructure at an effective cost. For more information, see Create a service role for model import.
Amazon Q Business is a fully managed generative AI-powered assistant that can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in your enterprise systems. Amazon Q Business only provides metric information that you can use to monitor your data source sync jobs.
Research papers and engineering documents often contain a wealth of information in the form of mathematical formulas, charts, and graphs. Navigating these unstructured documents to find relevant information can be a tedious and time-consuming task, especially when dealing with large volumes of data.
Amazon Bedrock Knowledge Bases offers a fully managed Retrieval Augmented Generation (RAG) feature that connects large language models (LLMs) to internal data sources. This feature enhances foundation model (FM) outputs with contextual information from private data, making responses more relevant and accurate.
Developing robust text-to-SQL capabilities is a critical challenge in the field of naturallanguageprocessing (NLP) and database management. You can provide it a naturallanguage query, such as “How many employees are there in each department in each region?”
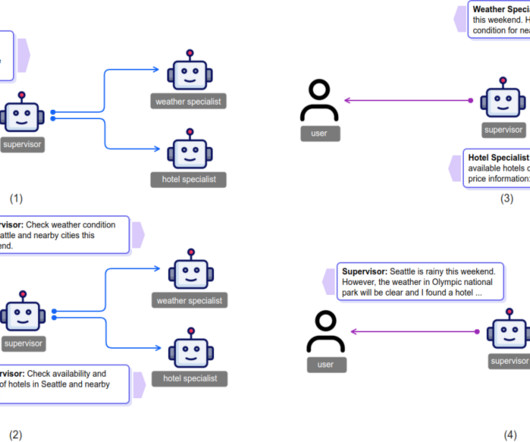
The research team at AWS has worked extensively on building and evaluating the multi-agent collaboration (MAC) framework so customers can orchestrate multiple AI agents on Amazon Bedrock Agents. Assertions : User is informed about the weather forecast for Las Vegas tomorrow, January 5, 2025.
These agents work with AWS managed infrastructure capabilities and Amazon Bedrock , reducing infrastructure management overhead. Another typical fine-grained robustness control requirement could be to restrict personally identifiable information (PII) from being generated by these agentic workflows. List and create guardrail versions.
Generative AIpowered assistants such as Amazon Q Business can be configured to answer questions, provide summaries, generate content, and securely complete tasks based on data and information in your enterprise systems. AWS Have an AWS account with administrative access.
In this post, we demonstrate how to use Amazon Bedrock Data Automation in the AWS Management Console and the AWS SDK for Python (Boto3) for media analysis and intelligent document processing (IDP) workflows. From the Projects console, create a new project and provide a project name, as shown in the following screenshot.
The learning program is typically designed for working professionals who want to learn about the advancing technological landscape of language models and learn to apply it to their work. It covers a range of topics including generative AI, LLM basics, naturallanguageprocessing, vector databases, prompt engineering, and much more.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content