This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
However, as the reach of live streams expands globally, language barriers and accessibility challenges have emerged, limiting the ability of viewers to fully comprehend and participate in these immersive experiences. The extension delivers a web application implemented using the AWS SDK for JavaScript and the AWS Amplify JavaScript library.
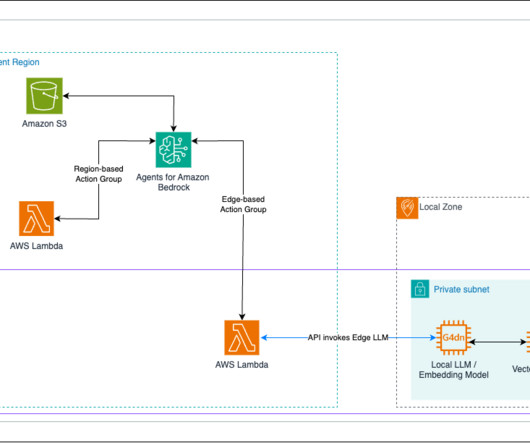
In this post, we show how to extend Amazon Bedrock Agents to hybrid and edge services such as AWS Outposts and AWS Local Zones to build distributed Retrieval Augmented Generation (RAG) applications with on-premises data for improved model outcomes.
Precise), an Amazon Web Services (AWS) Partner , participated in the AWS Think Big for Small Business Program (TBSB) to expand their AWS capabilities and to grow their business in the public sector. The platform helped the agency digitize and process forms, pictures, and other documents. Precise Software Solutions, Inc.
8B and 70B inference support on AWS Trainium and AWS Inferentia instances in Amazon SageMaker JumpStart. multilingual large language models (LLMs) are a collection of pre-trained and instruction tuned generative models. This approach allows for greater flexibility and integration with existing AI and ML workflows and pipelines.
With the QnABot on AWS (QnABot), integrated with Microsoft Azure Entra ID access controls, Principal launched an intelligent self-service solution rooted in generative AI. Principal sought to develop naturallanguageprocessing (NLP) and question-answering capabilities to accurately query and summarize this unstructured data at scale.
Enhancing AWS Support Engineering efficiency The AWS Support Engineering team faced the daunting task of manually sifting through numerous tools, internal sources, and AWS public documentation to find solutions for customer inquiries. Then we introduce the solution deployment using three AWS CloudFormation templates.
The new SDK is designed with a tiered user experience in mind, where the new lower-level SDK ( SageMaker Core ) provides access to full breadth of SageMaker features and configurations, allowing for greater flexibility and control for ML engineers. Admins and users can also overwrite the defaults using the SDK defaults configuration file.
The integration of modern naturallanguageprocessing (NLP) and LLM technologies enhances metadata accuracy, enabling more precise search functionality and streamlined document management. In this post, we discuss how you can build an AI-powered document processing platform with open source NER and LLMs on SageMaker.
Syngenta and AWS collaborated to develop Cropwise AI , an innovative solution powered by Amazon Bedrock Agents , to accelerate their sales reps’ ability to place Syngenta seed products with growers across North America. The collaboration between Syngenta and AWS showcases the transformative power of LLMs and AI agents.
However, with the help of AI and machine learning (ML), new software tools are now available to unearth the value of unstructured data. In this post, we discuss how AWS can help you successfully address the challenges of extracting insights from unstructured data. Let’s understand how these AWS services are integrated in detail.
You can try out the models with SageMaker JumpStart, a machine learning (ML) hub that provides access to algorithms, models, and ML solutions so you can quickly get started with ML. The model is deployed in an AWS secure environment and under your virtual private cloud (VPC) controls, helping provide data security.
We walk through the journey Octus took from managing multiple cloud providers and costly GPU instances to implementing a streamlined, cost-effective solution using AWS services including Amazon Bedrock, AWS Fargate , and Amazon OpenSearch Service. Along the way, it also simplified operations as Octus is an AWS shop more generally.
Large language models (LLMs) have revolutionized the field of naturallanguageprocessing, enabling machines to understand and generate human-like text with remarkable accuracy. However, despite their impressive language capabilities, LLMs are inherently limited by the data they were trained on.
Yes, the AWS re:Invent season is upon us and as always, the place to be is Las Vegas! Now all you need is some guidance on generative AI and machine learning (ML) sessions to attend at this twelfth edition of re:Invent. are the sessions dedicated to AWS DeepRacer ! are the sessions dedicated to AWS DeepRacer !
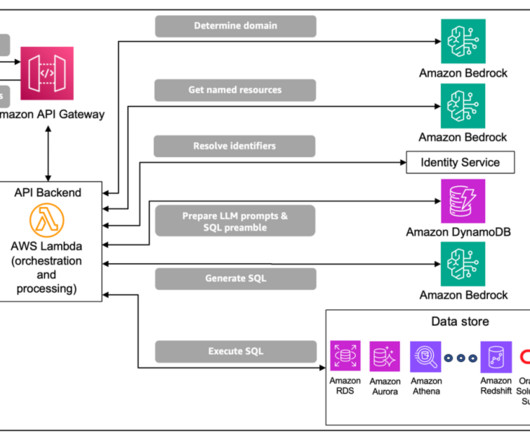
For enterprise data, a major difficulty stems from the common case of database tables having embedded structures that require specific knowledge or highly nuanced processing (for example, an embedded XML formatted string). This optional step has the most value when there are many named resources and the lookup process is complex.
They use real-time data and machine learning (ML) to offer customized loans that fuel sustainable growth and solve the challenges of accessing capital. To achieve this, Lumi developed a classification model based on BERT (Bidirectional Encoder Representations from Transformers) , a state-of-the-art naturallanguageprocessing (NLP) technique.
Prerequisites You need to have an AWS account and an AWS Identity and Access Management (IAM) role and user with permissions to create and manage the necessary resources and components for this application. If you dont have an AWS account, see How do I create and activate a new Amazon Web Services account? Choose Next.
This solution uses decorators in your application code to capture and log metadata such as input prompts, output results, run time, and custom metadata, offering enhanced security, ease of use, flexibility, and integration with native AWS services.
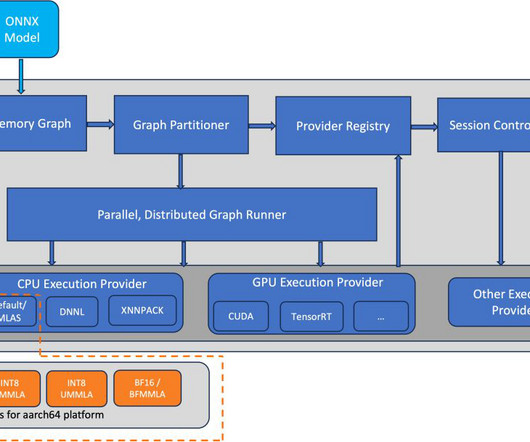
ONNX is an open source machine learning (ML) framework that provides interoperability across a wide range of frameworks, operating systems, and hardware platforms. AWS Graviton3 processors are optimized for ML workloads, including support for bfloat16, Scalable Vector Extension (SVE), and Matrix Multiplication (MMLA) instructions.
In this post, we explore how to deploy distilled versions of DeepSeek-R1 with Amazon Bedrock Custom Model Import, making them accessible to organizations looking to use state-of-the-art AI capabilities within the secure and scalable AWS infrastructure at an effective cost. You can monitor costs with AWS Cost Explorer.
For data scientists, moving machine learning (ML) models from proof of concept to production often presents a significant challenge. It can be cumbersome to manage the process, but with the right tool, you can significantly reduce the required effort. FastAPI is a modern, high-performance web framework for building APIs with Python.
Instead, organizations are increasingly looking to take advantage of transformative technologies like machine learning (ML) and artificial intelligence (AI) to deliver innovative products, improve outcomes, and gain operational efficiencies at scale.
AWS optimized the PyTorch torch.compile feature for AWS Graviton3 processors. the optimizations are available in torch Python wheels and AWS Graviton PyTorch deep learning container (DLC). It’s easier to use, more suitable for machine learning (ML) researchers, and hence is the default mode. Starting with PyTorch 2.3.1,
Lets assume that the question What date will AWS re:invent 2024 occur? The corresponding answer is also input as AWS re:Invent 2024 takes place on December 26, 2024. If the question was Whats the schedule for AWS events in December?, This setup uses the AWS SDK for Python (Boto3) to interact with AWS services.
This post demonstrates how to seamlessly automate the deployment of an end-to-end RAG solution using Knowledge Bases for Amazon Bedrock and AWS CloudFormation , enabling organizations to quickly and effortlessly set up a powerful RAG system. On the AWS CloudFormation console, create a new stack. Choose Next.
Historically, naturallanguageprocessing (NLP) would be a primary research and development expense. In 2024, however, organizations are using large language models (LLMs), which require relatively little focus on NLP, shifting research and development from modeling to the infrastructure needed to support LLM workflows.
Sprinklr’s specialized AI models streamline data processing, gather valuable insights, and enable workflows and analytics at scale to drive better decision-making and productivity. As early adopters of Graviton for ML workloads, it was initially challenging to identify the right software versions and the runtime tunings.
Sharing in-house resources with other internal teams, the Ranking team machine learning (ML) scientists often encountered long wait times to access resources for model training and experimentation – challenging their ability to rapidly experiment and innovate. If it shows online improvement, it can be deployed to all the users.
At AWS, we believe the long-term success of AI depends on the ability to inspire trust among users, customers, and society. Achieving ISO/IEC 42001 certification means that an independent third party has validated that AWS is taking proactive steps to manage risks and opportunities associated with AI development, deployment, and operation.
Global Resiliency is a new Amazon Lex capability that enables near real-time replication of your Amazon Lex V2 bots in a second AWS Region. We showcase the replication process of bot versions and aliases across multiple Regions. Solution overview For this exercise, we create a BookHotel bot as our sample bot.
Machine learning (ML) engineers have traditionally focused on striking a balance between model training and deployment cost vs. performance. This is important because training ML models and then using the trained models to make predictions (inference) can be highly energy-intensive tasks.
For instance, Berkeley’s Division of Data Science and Information points out that entry level data science jobs remote in healthcare involves skills in NLP (NaturalLanguageProcessing) for patient and genomic data analysis, whereas remote data science jobs in finance leans more on skills in risk modeling and quantitative analysis.
Llama2 by Meta is an example of an LLM offered by AWS. Llama 2 is an auto-regressive language model that uses an optimized transformer architecture and is intended for commercial and research use in English. Virginia) and US West (Oregon) AWS Regions, and most recently announced general availability in the US East (Ohio) Region.
It provides a common framework for assessing the performance of naturallanguageprocessing (NLP)-based retrieval models, making it straightforward to compare different approaches. Amazon SageMaker is a comprehensive, fully managed machine learning (ML) platform that revolutionizes the entire ML workflow.
Using an Amazon Q Business custom data source connector , you can gain insights into your organizations third party applications with the integration of generative AI and naturallanguageprocessing. Basic knowledge of AWS services and working knowledge of Alation or other data sources of choice.
22.03% The consistent improvements across different tasks highlight the robustness and effectiveness of Prompt Optimization in enhancing prompt performance for various naturallanguageprocessing (NLP) tasks. Shipra Kanoria is a Principal Product Manager at AWS. Outside work, he enjoys sports and cooking.
JupyterLab applications flexible and extensive interface can be used to configure and arrange machine learning (ML) workflows. We use JupyterLab to run the code for processing formulae and charts. Prerequisites If youre new to AWS, you first need to create and set up an AWS account.
Advancements in AI and naturallanguageprocessing (NLP) show promise to help lawyers with their work, but the legal industry also has valid questions around the accuracy and costs of these new techniques, as well as how customer data will be kept private and secure. These capabilities are built using the AWS Cloud.
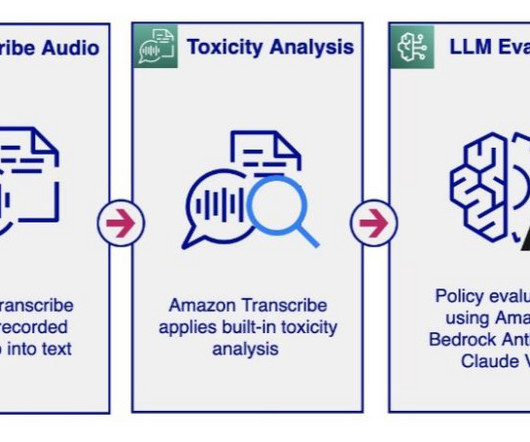
In this post, we introduce solutions that enable audio and text chat moderation using various AWS services, including Amazon Transcribe , Amazon Comprehend , Amazon Bedrock , and Amazon OpenSearch Service. Business users can modify prompts in human language, leading to enhanced efficiency and reduced iteration cycles in ML model training.
Discover and its transactional and batch applications are deployed and scaled on a Kubernetes on AWS cluster to optimize performance, user experience, and portability. AEP uses real-world data and a custom query language to compute over 1,000 science-validated features for the user-selected population.
In this post, we investigate of potential for the AWS Graviton3 processor to accelerate neural network training for ThirdAI’s unique CPU-based deep learning engine. As shown in our results, we observed a significant training speedup with AWS Graviton3 over the comparable Intel and NVIDIA instances on several representative modeling workloads.
Large Language Models (LLMs) have revolutionized the field of naturallanguageprocessing (NLP), improving tasks such as language translation, text summarization, and sentiment analysis. Through AWS Step Functions orchestration, the function calls Amazon Comprehend to detect the sentiment and toxicity.
We demonstrate how to build an end-to-end RAG application using Cohere’s language models through Amazon Bedrock and a Weaviate vector database on AWS Marketplace. Additionally, you can securely integrate and easily deploy your generative AI applications using the AWS tools you are already familiar with.
Measures Assistant is a microservice deployed in a Kubernetes on AWS environment and accessed through a REST API. Users now can turn questions expressed in naturallanguage into measures in a matter minutes as opposed to days, without the need of support staff and specialized training.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content