This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
However, as the reach of live streams expands globally, language barriers and accessibility challenges have emerged, limiting the ability of viewers to fully comprehend and participate in these immersive experiences. The extension delivers a web application implemented using the AWS SDK for JavaScript and the AWS Amplify JavaScript library.
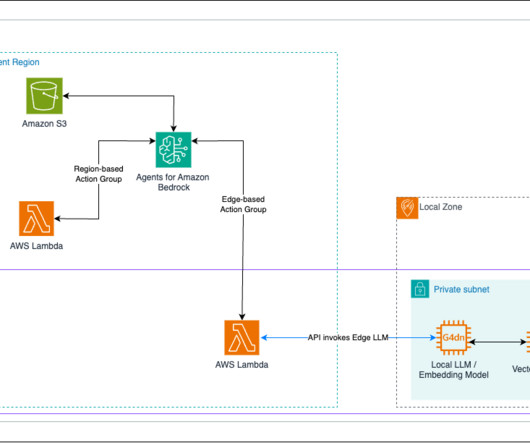
In this post, we show how to extend Amazon Bedrock Agents to hybrid and edge services such as AWS Outposts and AWS Local Zones to build distributed Retrieval Augmented Generation (RAG) applications with on-premises data for improved model outcomes.
This post demonstrates how you can gain a competitive advantage using Amazon Bedrock Agents based automation of a complex business process. The loan handler AWS Lambda function uses the information in the KYC documents to check the credit score and internal risk score. AWS CDK : 2.143.0 Solutions Architect with AWS India.
As organizations look to incorporate AI capabilities into their applications, large language models (LLMs) have emerged as powerful tools for naturallanguageprocessing tasks. AWS has always provided customers with choice. That includes model choice, hardware choice, and tooling choice.
Precise), an Amazon Web Services (AWS) Partner , participated in the AWS Think Big for Small Business Program (TBSB) to expand their AWS capabilities and to grow their business in the public sector. The platform helped the agency digitize and process forms, pictures, and other documents. Precise Software Solutions, Inc.
8B and 70B inference support on AWS Trainium and AWS Inferentia instances in Amazon SageMaker JumpStart. multilingual large language models (LLMs) are a collection of pre-trained and instruction tuned generative models. This approach allows for greater flexibility and integration with existing AI and ML workflows and pipelines.
With the QnABot on AWS (QnABot), integrated with Microsoft Azure Entra ID access controls, Principal launched an intelligent self-service solution rooted in generative AI. Principal sought to develop naturallanguageprocessing (NLP) and question-answering capabilities to accurately query and summarize this unstructured data at scale.
Enhancing AWS Support Engineering efficiency The AWS Support Engineering team faced the daunting task of manually sifting through numerous tools, internal sources, and AWS public documentation to find solutions for customer inquiries. Then we introduce the solution deployment using three AWS CloudFormation templates.
The new SDK is designed with a tiered user experience in mind, where the new lower-level SDK ( SageMaker Core ) provides access to full breadth of SageMaker features and configurations, allowing for greater flexibility and control for ML engineers. Admins and users can also overwrite the defaults using the SDK defaults configuration file.
Machine learning (ML) has emerged as a powerful tool to help nonprofits expedite manual processes, quickly unlock insights from data, and accelerate mission outcomesfrom personalizing marketing materials for donors to predicting member churn and donation patterns.
Previously, setting up a custom labeling job required specifying two AWS Lambda functions: a pre-annotation function, which is run on each dataset object before it’s sent to workers, and a post-annotation function, which is run on the annotations of each dataset object and consolidates multiple worker annotations if needed.
Syngenta and AWS collaborated to develop Cropwise AI , an innovative solution powered by Amazon Bedrock Agents , to accelerate their sales reps’ ability to place Syngenta seed products with growers across North America. The collaboration between Syngenta and AWS showcases the transformative power of LLMs and AI agents.
However, with the help of AI and machine learning (ML), new software tools are now available to unearth the value of unstructured data. In this post, we discuss how AWS can help you successfully address the challenges of extracting insights from unstructured data. Let’s understand how these AWS services are integrated in detail.
You can try out the models with SageMaker JumpStart, a machine learning (ML) hub that provides access to algorithms, models, and ML solutions so you can quickly get started with ML. The model is deployed in an AWS secure environment and under your virtual private cloud (VPC) controls, helping provide data security.
The integration of modern naturallanguageprocessing (NLP) and LLM technologies enhances metadata accuracy, enabling more precise search functionality and streamlined document management. In this post, we discuss how you can build an AI-powered document processing platform with open source NER and LLMs on SageMaker.
We walk through the journey Octus took from managing multiple cloud providers and costly GPU instances to implementing a streamlined, cost-effective solution using AWS services including Amazon Bedrock, AWS Fargate , and Amazon OpenSearch Service. Along the way, it also simplified operations as Octus is an AWS shop more generally.
Large language models (LLMs) have revolutionized the field of naturallanguageprocessing, enabling machines to understand and generate human-like text with remarkable accuracy. However, despite their impressive language capabilities, LLMs are inherently limited by the data they were trained on.
Yes, the AWS re:Invent season is upon us and as always, the place to be is Las Vegas! Now all you need is some guidance on generative AI and machine learning (ML) sessions to attend at this twelfth edition of re:Invent. are the sessions dedicated to AWS DeepRacer ! are the sessions dedicated to AWS DeepRacer !
Home Table of Contents Build a Search Engine: Setting Up AWS OpenSearch Introduction What Is AWS OpenSearch? What AWS OpenSearch Is Commonly Used For Key Features of AWS OpenSearch How Does AWS OpenSearch Work? Why Use AWS OpenSearch for Semantic Search? Looking for the source code to this post?
This post details our technical implementation using AWS services to create a scalable, multilingual AI assistant system that provides automated assistance while maintaining data security and GDPR compliance. In the process of implementation, we discovered that Anthropics Claude 3.5
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post. AI at Qualtrics Qualtrics has a deep history of using advanced ML to power its industry-leading experience management platform. Qualtrics refers to it internally as the Socrates platform.
Prerequisites You need to have an AWS account and an AWS Identity and Access Management (IAM) role and user with permissions to create and manage the necessary resources and components for this application. If you dont have an AWS account, see How do I create and activate a new Amazon Web Services account? Choose Next.
By the end of this journey, you will be equipped to streamline your development process and apply Chronos to any time series data, transforming your forecasting approach. Click here to open the AWS console and follow along. Maria Masood specializes in building data pipelines and data visualizations at AWS Commerce Platform.
We demonstrate this solution by walking you through a comprehensive step-by-step guide on how to fine-tune YOLOv8 , a real-time object detection model, on Amazon Web Services (AWS) using a custom dataset. The process uses a single ml.g5.2xlarge instance (providing one NVIDIA A10G Tensor Core GPU) with SageMaker for fine-tuning.
This solution uses decorators in your application code to capture and log metadata such as input prompts, output results, run time, and custom metadata, offering enhanced security, ease of use, flexibility, and integration with native AWS services.
The integrated approach and ease of use of Amazon Bedrock in deploying large language models (LLMs), along with built-in features that facilitate seamless integration with other AWS services like Amazon Kendra, made it the preferred choice. By using Claude 3’s vision capabilities, we could upload image-rich PDF documents.
They use real-time data and machine learning (ML) to offer customized loans that fuel sustainable growth and solve the challenges of accessing capital. To achieve this, Lumi developed a classification model based on BERT (Bidirectional Encoder Representations from Transformers) , a state-of-the-art naturallanguageprocessing (NLP) technique.
In this post, we explore how to deploy distilled versions of DeepSeek-R1 with Amazon Bedrock Custom Model Import, making them accessible to organizations looking to use state-of-the-art AI capabilities within the secure and scalable AWS infrastructure at an effective cost. You can monitor costs with AWS Cost Explorer.
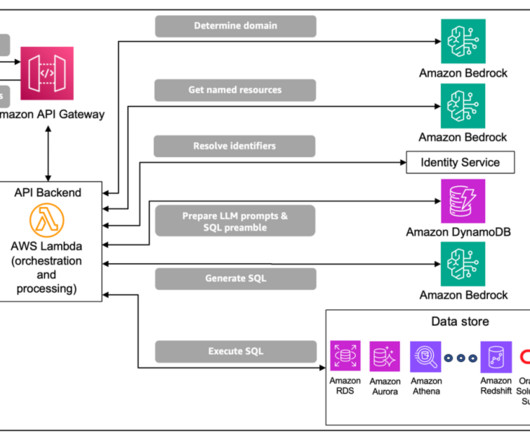
For enterprise data, a major difficulty stems from the common case of database tables having embedded structures that require specific knowledge or highly nuanced processing (for example, an embedded XML formatted string). This optional step has the most value when there are many named resources and the lookup process is complex.
Instead, organizations are increasingly looking to take advantage of transformative technologies like machine learning (ML) and artificial intelligence (AI) to deliver innovative products, improve outcomes, and gain operational efficiencies at scale.
AWS optimized the PyTorch torch.compile feature for AWS Graviton3 processors. the optimizations are available in torch Python wheels and AWS Graviton PyTorch deep learning container (DLC). It’s easier to use, more suitable for machine learning (ML) researchers, and hence is the default mode. Starting with PyTorch 2.3.1,
Lets assume that the question What date will AWS re:invent 2024 occur? The corresponding answer is also input as AWS re:Invent 2024 takes place on December 26, 2024. If the question was Whats the schedule for AWS events in December?, This setup uses the AWS SDK for Python (Boto3) to interact with AWS services.
This post demonstrates how to seamlessly automate the deployment of an end-to-end RAG solution using Knowledge Bases for Amazon Bedrock and AWS CloudFormation , enabling organizations to quickly and effortlessly set up a powerful RAG system. On the AWS CloudFormation console, create a new stack. Choose Next.
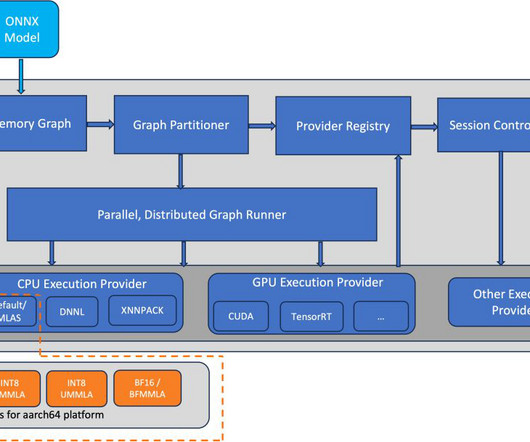
ONNX is an open source machine learning (ML) framework that provides interoperability across a wide range of frameworks, operating systems, and hardware platforms. AWS Graviton3 processors are optimized for ML workloads, including support for bfloat16, Scalable Vector Extension (SVE), and Matrix Multiplication (MMLA) instructions.
The Market to Molecule (M2M) value stream process, which biopharma companies must apply to bring new drugs to patients, is resource-intensive, lengthy, and highly risky. This post explores deploying a text-to-SQL pipeline using generative AI models and Amazon Bedrock to ask naturallanguage questions to a genomics database.
Sharing in-house resources with other internal teams, the Ranking team machine learning (ML) scientists often encountered long wait times to access resources for model training and experimentation – challenging their ability to rapidly experiment and innovate. If it shows online improvement, it can be deployed to all the users.
At AWS, we believe the long-term success of AI depends on the ability to inspire trust among users, customers, and society. Achieving ISO/IEC 42001 certification means that an independent third party has validated that AWS is taking proactive steps to manage risks and opportunities associated with AI development, deployment, and operation.
With this launch, developers and data scientists can now deploy Gemma 3, a 27-billion-parameter language model, along with its specialized instruction-following versions, to help accelerate building, experimentation, and scalable deployment of generative AI solutions on AWS.
Global Resiliency is a new Amazon Lex capability that enables near real-time replication of your Amazon Lex V2 bots in a second AWS Region. We showcase the replication process of bot versions and aliases across multiple Regions. Solution overview For this exercise, we create a BookHotel bot as our sample bot.
For instance, Berkeley’s Division of Data Science and Information points out that entry level data science jobs remote in healthcare involves skills in NLP (NaturalLanguageProcessing) for patient and genomic data analysis, whereas remote data science jobs in finance leans more on skills in risk modeling and quantitative analysis.
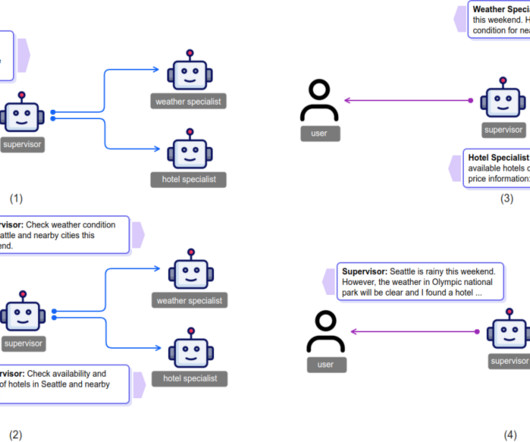
The research team at AWS has worked extensively on building and evaluating the multi-agent collaboration (MAC) framework so customers can orchestrate multiple AI agents on Amazon Bedrock Agents. At AWS, he led the Dialog2API project, which enables large language models to interact with the external environment through dialogue.
Our previous blog post, Anduril unleashes the power of RAG with enterprise search chatbot Alfred on AWS , highlighted how Anduril Industries revolutionized enterprise search with Alfred, their innovative chat-based assistant powered by Retrieval-Augmented Generation (RAG) architecture. Sonnet v2 as the primary model with Llama 3.3
It provides a common framework for assessing the performance of naturallanguageprocessing (NLP)-based retrieval models, making it straightforward to compare different approaches. Amazon SageMaker is a comprehensive, fully managed machine learning (ML) platform that revolutionizes the entire ML workflow.
These agents work with AWS managed infrastructure capabilities and Amazon Bedrock , reducing infrastructure management overhead. Prerequisites To run this demo in your AWS account, complete the following prerequisites: Create an AWS account if you don’t already have one. For more details, see Amazon S3 pricing.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content