This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For instance, Berkeley’s Division of Data Science and Information points out that entry level data science jobs remote in healthcare involves skills in NLP (NaturalLanguageProcessing) for patient and genomic data analysis, whereas remote data science jobs in finance leans more on skills in risk modeling and quantitative analysis.
We walk through the journey Octus took from managing multiple cloud providers and costly GPU instances to implementing a streamlined, cost-effective solution using AWS services including Amazon Bedrock, AWS Fargate , and Amazon OpenSearch Service. Along the way, it also simplified operations as Octus is an AWS shop more generally.
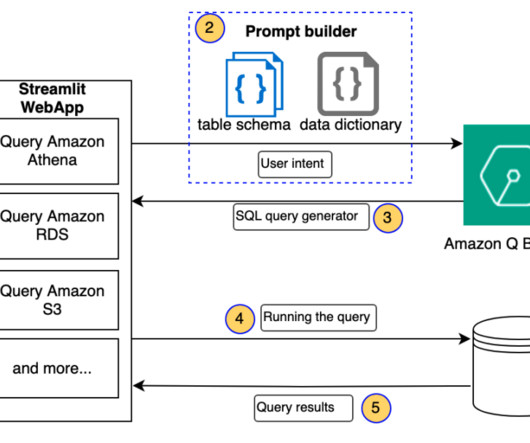
In the process of working on their ML tasks, data scientists typically start their workflow by discovering relevant data sources and connecting to them. They then use SQL to explore, analyze, visualize, and integrate data from various sources before using it in their ML training and inference.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. Today, generative AI can enable people without SQL knowledge. The solution in this post aims to bring enterprise analytics operations to the next level by shortening the path to your data using naturallanguage.
Large language models (LLMs) have revolutionized the field of naturallanguageprocessing with their ability to understand and generate humanlike text. For details, refer to Creating an AWS account. Be sure to set up your AWS Command Line Interface (AWS CLI) credentials correctly.
Overview of RAG RAG solutions are inspired by representation learning and semantic search ideas that have been gradually adopted in ranking problems (for example, recommendation and search) and naturallanguageprocessing (NLP) tasks since 2010.
One such area that is evolving is using naturallanguageprocessing (NLP) to unlock new opportunities for accessing data through intuitive SQL queries. Instead of dealing with complex technical code, business users and data analysts can ask questions related to data and insights in plain language.
Naturallanguage is ambiguous and imprecise, whereas data adheres to rigid schemas. For example, SQL queries can be complex and unintuitive for non-technical users. Handling complex queries involving multiple tables, joins, and aggregations makes it difficult to interpret user intent and translate it into correct SQL operations.
With the rapid growth of generative artificial intelligence (AI), many AWS customers are looking to take advantage of publicly available foundation models (FMs) and technologies. This includes Meta Llama 3, Meta’s publicly available large language model (LLM).
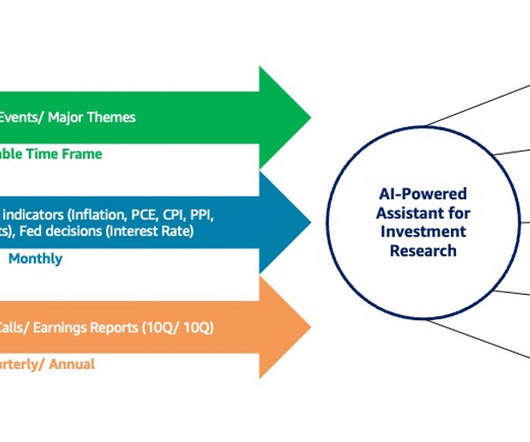
Implementing a multi-modal agent with AWS consolidates key insights from diverse structured and unstructured data on a large scale. All this is achieved using AWS services, thereby increasing the financial analyst’s efficiency to analyze multi-modal financial data (text, speech, and tabular data) holistically.
Snowflake Arctic is a family of enterprise-grade large language models (LLMs) built by Snowflake to cater to the needs of enterprise users, exhibiting exceptional capabilities (as shown in the following benchmarks ) in SQL querying, coding, and accurately following instructions.
Amazon Athena and Aurora add support for ML in SQL Queries You can now invoke Machine Learning models right from your SQL Queries. Use Amazon Sagemaker to add ML predictions in Amazon QuickSight Amazon QuickSight, the AWS BI tool, now has the capability to call Machine Learning models.
With AWS generative AI services like Amazon Bedrock , developers can create systems that expertly manage and respond to user requests. It is hosted on Amazon Elastic Container Service (Amazon ECS) with AWS Fargate , and it is accessed using an Application Load Balancer. It serves as the data source to the knowledge base.
needed to address some of these challenges in one of their many AI use cases built on AWS. In this post, we discuss a Q&A bot use case that Q4 has implemented, the challenges that numerical and structured datasets presented, and how Q4 concluded that using SQL may be a viable solution.
We formulated a text-to-SQL approach where by a user’s naturallanguage query is converted to a SQL statement using an LLM. The SQL is run by Amazon Athena to return the relevant data. Amazon Kendra uses naturallanguageprocessing (NLP) to understand user queries and find the most relevant documents.
Businesses can use LLMs to gain valuable insights, streamline processes, and deliver enhanced customer experiences. In addition, the generative business intelligence (BI) capabilities of QuickSight allow you to ask questions about customer feedback using naturallanguage, without the need to write SQL queries or learn a BI tool.
Furthermore, the democratization of AI and ML through AWS and AWS Partner solutions is accelerating its adoption across all industries. Splunk , an AWS Partner, offers a unified security and observability platform built for speed and scale.
It makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. AWS offers tools such as RStudio on SageMaker and Amazon Redshift to help tackle these challenges. I acknowledge that AWS CloudFormation might create IAM resources with custom names.
In line with this mission, Talent.com collaborated with AWS to develop a cutting-edge job recommendation engine driven by deep learning, aimed at assisting users in advancing their careers. The solution does not require porting the feature extraction code to use PySpark, as required when using AWS Glue as the ETL solution.
The naturallanguage capabilities allow non-technical users to query data through conversational English rather than complex SQL. The AI and language models must identify the appropriate data sources, generate effective SQL queries, and produce coherent responses with embedded results at scale.
Fine-tuning is a powerful approach in naturallanguageprocessing (NLP) and generative AI , allowing businesses to tailor pre-trained large language models (LLMs) for specific tasks. This process involves updating the model’s weights to improve its performance on targeted applications. Sonnet across various tasks.
Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python.
This post is a follow-up to Generative AI and multi-modal agents in AWS: The key to unlocking new value in financial markets. Analysts need to learn new tools and even some programming languages such as SQL (with different variations). Delete the S3 buckets created by AWS CloudFormation and then delete the CloudFormation stack.
For scenarios where you need to add your own custom scripts for data transformations, you can write your transformation logic in Pandas, PySpark, PySpark SQL. With the Data Wrangler custom transform capability, you can write your transformation logic in Pandas, PySpark, PySpark SQL. After notebook files (.ipynb)
Working with the AWS Generative AI Innovation Center , DoorDash built a solution to provide Dashers with a low-latency self-service voice experience to answer frequently asked questions, reducing the need for live agent assistance, in just 2 months. “We You can deploy the solution in your own AWS account and try the example solution.
Source: Generative AI on AWS (O’Reilly, 2023) LoRA has gained popularity recently for several reasons. LLMs, like Llama2, have shown state-of-the-art performance on naturallanguageprocessing (NLP) tasks when fine-tuned on domain-specific data. This method of separating the base and adapter models has some drawbacks.
Naturallanguageprocessing (NLP) has been growing in awareness over the last few years, and with the popularity of ChatGPT and GPT-3 in 2022, NLP is now on the top of peoples’ minds when it comes to AI. Knowing some SQL is also essential.
With this launch, you can now access Mistrals frontier-class multimodal model to build, experiment, and responsibly scale your generative AI ideas on AWS. AWS is the first major cloud provider to deliver Pixtral Large as a fully managed, serverless model. Additionally, Pixtral Large supports the Converse API and tool usage.
Amazon Comprehend is a naturallanguageprocessing (NLP) service that uses ML to uncover insights and relationships in unstructured data, with no managing infrastructure or ML experience required. Prerequisites For this walkthrough, you should have the following: An AWS account. A SageMaker Studio domain and user.
Amazon Kendra is a highly accurate and intelligent search service that enables users to search unstructured and structured data using naturallanguageprocessing (NLP) and advanced search algorithms. With Amazon Kendra, you can find relevant answers to your questions quickly, without sifting through documents.
Explore the feature processing pipelines and lineage in Amazon SageMaker Studio. Prerequisites To follow this tutorial, you need the following: An AWS account. AWS Identity and Access Management (IAM) permissions. Define the aggregate() function to aggregate the data using PySpark SQL and user-defined functions (UDFs).
Descriptive analytics is a fundamental method that summarizes past data using tools like Excel or SQL to generate reports. Techniques like NaturalLanguageProcessing (NLP) and computer vision are applied to extract insights from text and images. Data Scientists rely on technical proficiency.
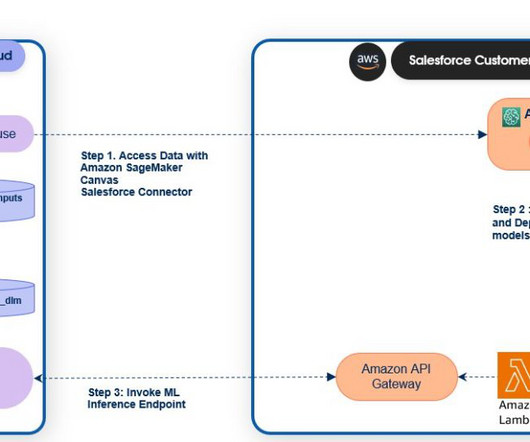
SageMaker Canvas provides a visual point-and-click interface to generate accurate ML predictions for classification, regression, forecasting, naturallanguageprocessing (NLP), and computer vision (CV). Perform ANSI SQL queries on Salesforce Data Cloud data (Data Cloud_query_api ). For Callback URL , enter [link].studio.sagemaker.aws/canvas/default/lab
As pioneers in the NaturalLanguageProcessing (NLP) space, Lyngo has leveled the data playing field with tools that allow anyone to learn from data. You don’t have to know SQL to query your data, and you don’t have to be an analyst to draw data-driven conclusions. Step two is where Lyngo and SQL come in.
It provides tools that offer data connectors to ingest your existing data with various sources and formats (PDFs, docs, APIs, SQL, and more). Prerequisites For this example, you need an AWS account with a SageMaker domain and appropriate AWS Identity and Access Management (IAM) permissions.
Familiarity with libraries like pandas, NumPy, and SQL for data handling is important. Check out this course to upskill on Apache Spark — [link] Cloud Computing technologies such as AWS, GCP, Azure will also be a plus. This includes skills in data cleaning, preprocessing, transformation, and exploratory data analysis (EDA).
AWS provides the most complete set of services for the entire end-to-end data journey for all workloads, all types of data, and all desired business outcomes. The high-level steps involved in the solution are as follows: Use AWS Step Functions to orchestrate the health data anonymization pipeline.
This could involve better preprocessing tools, semi-supervised learning techniques, and advances in naturallanguageprocessing. You can create a custom transform using Pandas, PySpark, Python user-defined functions, and SQL PySpark. About the Authors Ajjay Govindaram is a Senior Solutions Architect at AWS.
This allows users to accomplish different NaturalLanguageProcessing (NLP) functional tasks and take advantage of IBM vetted pre-trained open-source foundation models. Encoder-decoder and decoder-only large language models are available in the Prompt Lab today. To bridge the tuning gap, watsonx.ai
Build Classification and Regression Models with Spark on AWS Suman Debnath | Principal Developer Advocate, Data Engineering | Amazon Web Services This immersive session will cover optimizing PySpark and best practices for Spark MLlib.
Celonis unterscheidet sich von den meisten anderen Tools noch dahingehend, dass es versucht, die ganze Kette des Process Minings in einer einzigen und ausschließlichen Cloud-Anwendung in einer Suite bereitzustellen. in Databricks oder den KI-Tools von Google, AWS und Mircosoft Azure (Azure Cognitive Services, Azure Machine Learning etc.).
Proficiency in programming languages like Python and SQL. Key Skills Experience with cloud platforms (AWS, Azure). Familiarity with SQL for database management. Key Skills Proficiency in programming languages such as Python or Java. Salary Range: 12,00,000 – 35,00,000 per annum.
The Large Language Models (LLMs) have the ability to interpret and create from data, whether through naturallanguageprocessing (NLP) or synthetic data generation, which can result in enriched data visualization. This section will focus on setting up AWS Bedrock and Snowflake Cortex in Matllion DPC.
Relational databases (like MySQL) or No-SQL databases (AWS DynamoDB) can store structured or even semi-structured data but there is one inherent problem. Options (Free vs Paid) Closing Introduction In today’s increasingly globalized world, the ability to communicate in multiple languages has become a highly valuable skill.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content