This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Source: [link] Introduction AWS S3 is one of the object storage services offered by Amazon Web Services or AWS. The post Using AWS S3 with Python boto3 appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon.
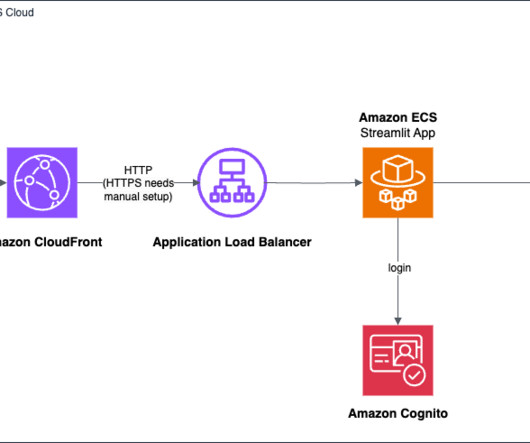
AWS provides a powerful set of tools and services that simplify the process of building and deploying generative AI applications, even for those with limited experience in frontend and backend development. The Python application uses the Streamlit library to provide a user-friendly interface for interacting with a generative AI model.
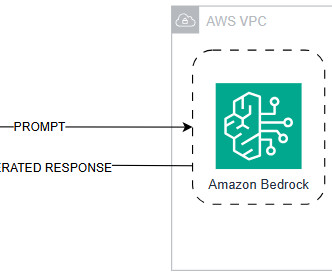
Because Amazon Bedrock is serverless, you don’t have to manage any infrastructure, and you can securely integrate and deploy generative AI capabilities into your applications using the AWS services you are already familiar with. client( service_name="bedrock-runtime", region_name="us-east-1" ) Define the model to invoke using its model ID.
AWS Lambda is a service that allows developers to run code without having to set up and manage such servers and hence is often classified under the […]. The post A primer on AWS Lambda Function appeared first on Analytics Vidhya.
Image 1- [link] Whether you are an experienced or an aspiring data scientist, you must have worked on machine learning model development comprising of data cleaning, wrangling, comparing different ML models, training the models on Python Notebooks like Jupyter. All the […].
AWS (Amazon Web Services) is a formidable force in this landscape. Once you navigate the complexities, two services, AWS Elastic Beanstalk and AWS Lambda, often become vital concerns. The question […] The post AWS Elastic Beanstalk and AWS Lambda: A Practical Guide & CCP Exam appeared first on Analytics Vidhya.
Source: [link] Introduction The AWS Command Line Interface (CLI) is a centralized management tool for managing AWS services. With this one tool, it can handle multiple AWS services from the […]. The post Creating and Managing DynamoDB Tables using AWS CLI appeared first on Analytics Vidhya.
The post Population Health Analytics with AWS HealthLake and QuickSight appeared first on Analytics Vidhya. Medical Interoperability is the ability to integrate and share secure healthcare information promptly across multiple systems. Medical Interoperability along with AI & Machine Learning […].
Introduction AWS is a cloud computing service that provides on-demand computing resources for storage, networking, Machine learning, etc on a pay-as-you-go pricing model. AWS is a premier cloud computing platform around the globe, and most organization uses AWS for global networking and data […].
The post Using AWS Athena and QuickSight for Data Analysis appeared first on Analytics Vidhya. Also, have you ever tried doing this with Athena and QuickSight? This blog post will walk you through the necessary steps to achieve this using Amazon services and tools. Amazon’s perfect combination of […].
It is a Lucene-based search engine developed in Java but supports clients in various languages such as Python, C#, Ruby, and PHP. The post Basic Concept and Backend of AWS Elasticsearch appeared first on Analytics Vidhya. It takes unstructured data from multiple sources as input and stores it […].
The post Building ML Model in AWS Sagemaker appeared first on Analytics Vidhya. AI/ML has become an integral part of research and innovations. The main objective of the AI system is to solve real-world problems where […].
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. Third, we’ll explore the robust infrastructure services from AWS powering AI innovation, featuring Amazon SageMaker , AWS Trainium , and AWS Inferentia under AI/ML, as well as Compute topics.
In 2018, I sat in the audience at AWS re:Invent as Andy Jassy announced AWS DeepRacer —a fully autonomous 1/18th scale race car driven by reinforcement learning. But AWS DeepRacer instantly captured my interest with its promise that even inexperienced developers could get involved in AI and ML.
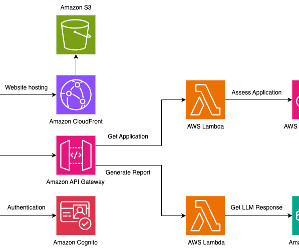
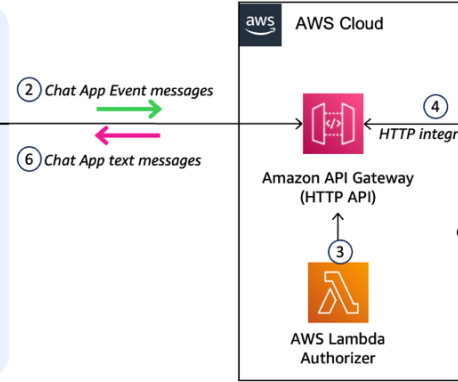
The translation playground could be adapted into a scalable serverless solution as represented by the following diagram using AWS Lambda , Amazon Simple Storage Service (Amazon S3), and Amazon API Gateway. To run the project code, make sure that you have fulfilled the AWS CDK prerequisites for Python.
convenient Introduction AWS Lambda is a serverless computing service that lets you run code in response to events while having the underlying compute resources managed for you automatically. The post AWS Lambda: A Convenient Way to Send Emails and Analyze Logs appeared first on Analytics Vidhya.
The post Introduction to Amazon API Gateway using AWS Lambda appeared first on Analytics Vidhya. If you want to make noodles, you just take the ingredients out of the cupboard, fire up the stove, and make it yourself. This […].
Deploying PySpark on AWS applications on the cloud can be a game-changer, offering scalability and flexibility for data-intensive tasks. Amazon Web Services (AWS) provides an ideal platform for such deployments, and when combined […] The post What Are the Best Practices for Deploying PySpark on AWS?
This article explores the intricacies of automating ETL pipelines using Apache Airflow on AWS EC2. It […] The post Streamlining Data Workflow with Apache Airflow on AWS EC2 appeared first on Analytics Vidhya.
To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023. In this blog post, we showcase how you can perform efficient supervised fine tuning for a Meta Llama 3 model using PEFT on AWS Trainium with SageMaker HyperPod. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
In this post, we explore how to use the power of AWS Resilience Hub and Amazon Bedrock to bridge this gap and streamline the process of sharing architectural findings across your organization. Prerequisites For this walkthrough, the following are required: An AWS account. AWS Management Console access. A Python 3.12
Source: Link Introduction In this article, we are going to talk about a dynamo DB a No-SQL, and a very highly scalable database provided by Amazon AWS. The post Working with DynamoDb in Python using BOTO3 appeared first on Analytics Vidhya. It is […].
AWS has always provided customers with choice. In terms of hardware choice, in addition to NVIDIA GPUs and AWS custom AI chips, CPU-based instances represent (thanks to the latest innovations in CPU hardware) an additional choice for customers who want to run generative AI inference, like hosting small language models and asynchronous agents.
The post Automate Model Deployment with GitHub Actions and AWS appeared first on Analytics Vidhya. First, you build software, test it for possible faults, and finally deploy it for the end user’s accessibility. The same can be applied to […].
8B and 70B inference support on AWS Trainium and AWS Inferentia instances in Amazon SageMaker JumpStart. Trainium and Inferentia, enabled by the AWS Neuron software development kit (SDK), offer high performance and lower the cost of deploying Meta Llama 3.1 An AWS Identity and Access Management (IAM) role to access SageMaker.
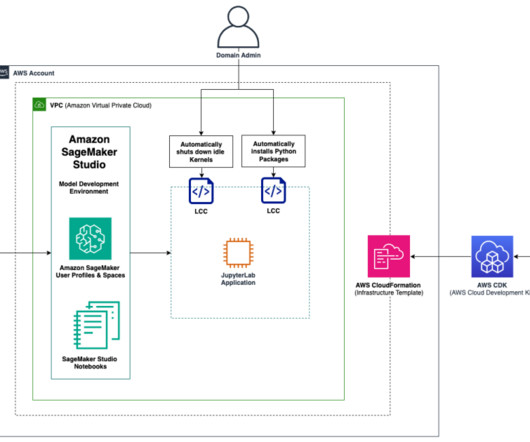
Solution overview The solution constitutes a best-practice Amazon SageMaker domain setup with a configurable list of domain user profiles and a shared SageMaker Studio space using the AWS Cloud Development Kit (AWS CDK). The AWS CDK is a framework for defining cloud infrastructure as code. The AWS CDK installed.
Introduction When we start learning AWS, we usually learn bits and pieces of it, like some of the core services; working around the AWS console, we could create a new ec2 instance or an s3 bucket and upload something to it. But in most cases, we couldn’t put all the services together into an actual application.
It simplifies the often complex and time-consuming tasks involved in setting up and managing an MLflow environment, allowing ML administrators to quickly establish secure and scalable MLflow environments on AWS. AWS CodeArtifact , which provides a private PyPI repository so that SageMaker can use it to download necessary packages.
As we know, we are currently using the VIT […] The post Building End-to-End Generative AI Models with AWS Bedrock appeared first on Analytics Vidhya. The evaluation of Gen AI began with the Transformer architecture, and this strategy has since been adopted in other fields. Let’s take an example.
The post Crafting Serverless ETL Pipeline Using AWS Glue and PySpark appeared first on Analytics Vidhya. It involves extracting the operational data from various sources, transforming it into a format suitable for business needs, and loading it into data storage systems. Traditionally, ETL processes are […].
Enter AWS EMR, or Amazon Elastic […] The post What is AWS EMR? This question has plagued many businesses and organizations as they navigate the complexities of big data. From log analysis to financial modeling, the need for scalable and flexible solutions has never been greater.
Were excited to announce the open source release of AWS MCP Servers for code assistants a suite of specialized Model Context Protocol (MCP) servers that bring Amazon Web Services (AWS) best practices directly to your development workflow. This post is the first in a series covering AWS MCP Servers.
We’re excited to announce the release of SageMaker Core , a new Python SDK from Amazon SageMaker designed to offer an object-oriented approach for managing the machine learning (ML) lifecycle. The SageMaker Core SDK comes bundled as part of the SageMaker Python SDK version 2.231.0 or greater is installed in the environment.
Solutions should be flexible to adopt, allow seamless integration with other systems, and provide a path to automate MLOps using AWS services and third-party tools, as we’ll explore in this post with Pulumi and Datadog. Lastly, the model-c endpoint also has access to input S3 objects in the Crexi AWS account in addition to Amazon Textract.
The post Building a Data Pipeline with PySpark and AWS appeared first on Analytics Vidhya. ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Apache Spark is a framework used in cluster computing environments.
To address this need, AWS generative AI best practices framework was launched within AWS Audit Manager , enabling auditing and monitoring of generative AI applications. Figure 1 depicts the systems functionalities and AWS services. Select AWS Generative AI Best Practices Framework for assessment. Choose Create assessment.
Previously, setting up a custom labeling job required specifying two AWS Lambda functions: a pre-annotation function, which is run on each dataset object before it’s sent to workers, and a post-annotation function, which is run on the annotations of each dataset object and consolidates multiple worker annotations if needed.
The post Creating an ML Web App and Deploying it on AWS appeared first on Analytics Vidhya. Some modern applications deploy embedded models in edge and mobile devices. ML web app Model creation is easy but the ML model that you […].
In this blog post, I will look at what makes physical AWS DeepRacer racing—a real car on a real track—different to racing in the virtual world—a model in a simulated 3D environment. The AWS DeepRacer League is wrapping up. The original AWS DeepRacer, without modifications, has a smaller speed range of about 2 meters per second.
Powered by generative AI services on AWS and large language models (LLMs) multi-modal capabilities, HCLTechs AutoWise Companion provides a seamless and impactful experience. Technical architecture The overall solution is implemented using AWS services and LangChain. AWS Glue AWS Glue is used for data cataloging.
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. The following figure illustrates the high-level design of the solution.
Using vLLM on AWS Trainium and Inferentia makes it possible to host LLMs for high performance inference and scalability. Deploy vLLM on AWS Trainium and Inferentia EC2 instances In these sections, you will be guided through using vLLM on an AWS Inferentia EC2 instance to deploy Meta’s newest Llama 3.2 You will use inf2.xlarge
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content