This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction We are all pretty much familiar with the common modern clouddata warehouse model, which essentially provides a platform comprising a data lake (based on a cloud storage account such as AzureData Lake Storage Gen2) AND a data warehouse compute engine […].
By automating the provisioning and management of cloud resources through code, IaC brings a host of advantages to the development and maintenance of Data Warehouse Systems in the cloud. So why using IaC for CloudData Infrastructures? Of course, Terraform and the Azure CLI needs to be installed before.
Welcome to CloudData Science 7. Announcements around an exciting new open-source deep learning library, a new data challenge and more. It involves solving a data puzzle using Big Query. Google has an updated DataEngineering Learning path. There is a new challenge every week. Training and Courses.
Introduction Microsoft Azure HDInsight(or Microsoft HDFS) is a cloud-based Hadoop Distributed File System version. A distributed file system runs on commodity hardware and manages massive data collections. It is a fully managed cloud-based environment for analyzing and processing enormous volumes of data.
The fusion of data in a central platform enables smooth analysis to optimize processes and increase business efficiency in the world of Industry 4.0 using methods from business intelligence , process mining and data science. CloudData Platform for shopfloor management and data sources such like MES, ERP, PLM and machine data.
Occasionally a product in Microsoft Azure will go down. Luckily, Azure has a status page to tell you which servers and services are down. Here is a quick video to help you find that status page.
With this full-fledged solution, you don’t have to spend all your time and effort combining different services or duplicating data. OneLake, being built on AzureData Lake Storage (ADLS), supports various data formats, including Delta, Parquet, CSV, and JSON. In the menu bar on the left, select Workspaces.
Here are details about the 3 certification of interest to data scientists and dataengineers. AzureData Scientist Associate. Exams Required: DP-100: Designing and Implementing a Data Science Solution on Azure. For more details and to register, go to the AzureData Scientist Associate page.
Data Lakehouses werden auf Cloud-basierten Objektspeichern wie Amazon S3 , Google Cloud Storage oder Azure Blob Storage aufgebaut. In einem Data Lakehouse werden die Daten in ihrem Rohformat gespeichert, und Transformationen und Datenverarbeitung werden je nach Bedarf durchgeführt. So basieren z.
Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles. By integrating QnABot with Azure Active Directory, Principal facilitated single sign-on capabilities and role-based access controls.
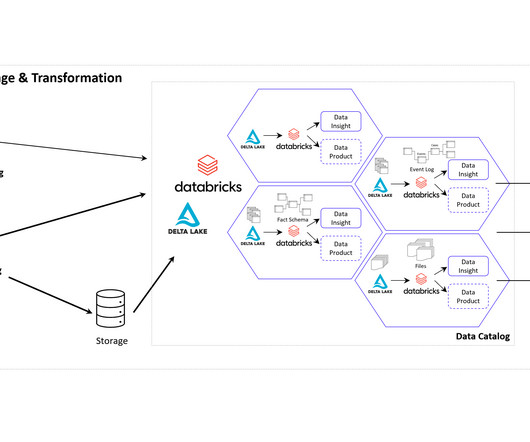
The creation of this data model requires the data connection to the source system (e.g. SAP ERP), the extraction of the data and, above all, the data modeling for the event log. DATANOMIQ Data Mesh Cloud Architecture – This image is animated! Click to enlarge!
Dataengineering has become an integral part of the modern tech landscape, driving advancements and efficiencies across industries. So let’s explore the world of open-source tools for dataengineers, shedding light on how these resources are shaping the future of data handling, processing, and visualization.
auf den Analyse-Ressourcen der Microsoft AzureCloud oder in auf der databricks-Plattform. Gemeinsam haben sie alle die Funktion als Zwischenebene zwischen den Datenquellen und den Process Mining, BI und Data Science Applikationen. Umgesetzt werden diese Anwendungsfälle bisher vor allem auf dritten Plattformen, wie z.
Length of Interview: 30 – 45 minutes Interview 2: Leadership In this interview, you will meet with the Director of the Solutions Engineering team. The discussion points in this interview will include a review of your current experience as it relates to clouddataengineering and solution engineering.
Data Versioning and Time Travel Open Table Formats empower users with time travel capabilities, allowing them to access previous dataset versions. Versioning also ensures a safer experimentation environment, where data scientists can test new models or hypotheses on historical data snapshots without impacting live data.
The Cloud represents an iteration beyond the on-prem data warehouse, where computing resources are delivered over the Internet and are managed by a third-party provider. Examples include: Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP). Data integrations and pipelines can also impact latency.
One big issue that contributes to this resistance is that although Snowflake is a great clouddata warehousing platform, Microsoft has a data warehousing tool of its own called Synapse. In a perfect world, Microsoft would have clients push even more storage and compute to its Azure Synapse platform.
Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python.
Fivetran works with all three Snowflake cloud providers. If using a network policy with Snowflake, be sure to add Fivetran’s IP address list , which will ensure AzureData Factory (ADF) AzureData Factory is a fully managed, serverless data integration service built by Microsoft.
Organizations must ensure their data pipelines are well designed and implemented to achieve this, especially as their engagement with clouddata platforms such as the Snowflake DataCloud grows. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable data pipelines.
Best practices are a pivotal part of any software development, and dataengineering is no exception. This ensures the data pipelines we create are robust, durable, and secure, providing the desired data to the organization effectively and consistently. Below are the best practices. What are Matillion's limitations?
The platform enables quick, flexible, and convenient options for storing, processing, and analyzing data. The solution was built on top of Amazon Web Services and is now available on Google Cloud and Microsoft Azure. Therefore, the tool is referred to as cloud-agnostic. What does Snowflake do?
However, Snowflake offers many of the capabilities needed for a self-service data platform, enabling a distributed, domain-driven architecture and offering capabilities to help implement data as a product and federated computational governance. Regularly communicate the progress, successes, and challenges of data mesh implementation.
However, if there’s one thing we’ve learned from years of successful clouddata implementations here at phData, it’s the importance of: Defining and implementing processes Building automation, and Performing configuration …even before you create the first user account. authorization server.
Matillion is also built for scalability and future data demands, with support for clouddata platforms such as Snowflake DataCloud , Databricks, Amazon Redshift, Microsoft Azure Synapse, and Google BigQuery, making it future-ready, everyone-ready, and AI-ready. Contact phData today!
This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for dataengineers to enhance and sustain their pipelines. Before delving into the technical details, let’s review some fundamental concepts.
While data fabric takes a product-and-tech-centric approach, data mesh takes a completely different perspective. Data mesh inverts the common model of having a centralized team (such as a dataengineering team), who manage and transform data for wider consumption. But why is such an inversion needed?
Here’s how a composable CDP might incorporate the modeling approaches we’ve discussed: Data Storage and Processing : This is your foundation. You might choose a clouddata warehouse like the Snowflake AI DataCloud or BigQuery. Building a composable CDP requires some serious dataengineering chops.
Modern low-code/no-code ETL tools allow dataengineers and analysts to build pipelines seamlessly using a drag-and-drop and configure approach with minimal coding. Matillion ETL for Snowflake is an ELT/ETL tool that allows for the ingestion, transformation, and building of analytics for data in the Snowflake AI DataCloud.
One of this aspect is the cloud architecture for the realization of Data Mesh. Data Mesh on AzureCloud with Databricks and Delta Lake for Applications of Business Intelligence, Data Science and Process Mining. It offers robust IoT and edge computing capabilities, advanced data analytics, and AI services.
With the birth of clouddata warehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. First up, let’s dive into the foundation of every Modern Data Stack, a cloud-based data warehouse.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content