This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Azure Synapse provides a unified platform to ingest, explore, prepare, transform, manage, and serve data for BI (Business Intelligence) and machine learning needs. In this blog, we will explore how to optimize performance and reduce costs when using dedicated SQL pools in Azure Synapse Analytics.
Azure Data Studio has rapidly gained popularity among developers and database administrators for its user-friendly design and powerful features. As a versatile tool, it simplifies the management of both SQL Server and Azure SQL databases, offering a modern alternative to traditional database management solutions.
The company aims to enhance its artificial intelligence capabilities, particularly within its Azure cloud services. Microsoft acquires 485,000 Nvidia AI chips to boost Azure Analysts at Omdia reveal that Microsofts chip orders exceed those of its closest competitors, indicating its aggressive push in AI infrastructure development.
Welcome to this comprehensive guide on Azure Machine Learning , Microsoft’s powerful cloud-based platform that’s revolutionizing how organizations build, deploy, and manage machine learning models. Sit back, relax, and enjoy this exploration of Azure Machine Learning’s capabilities, benefits, and practical applications.
The complexity of Kubernetes manifests and cluster management can pose significant challenges, potentially slowing down development cycles and resource utilization. Solution overview Implementing this solution is straightforward, whether you’re working with existing SageMaker HyperPod clusters or setting up a new deployment.
Rise of data lakes Data lakes originated in Hadoop clusters during the early 2000s and offered a cost-effective means of storing a variety of data types, including structured, semi-structured, and unstructured data. Decoupled storage and compute: Enhanced scalability through separate server clusters for storage and processing.
It gives these users a single, intuitive entry point to interact with data and AI—without needing to understand clusters, queries, models, or notebooks. Databricks One is a new product experience designed specifically for business users.
At Databricks, we run our compute infrastructure on AWS, Azure, and GCP. We orchestrate containerized services using Kubernetes clusters. We develop and manage.
In this post, well explore how different Azure disk types perform under distributed database workloads, using YugabyteDB as our distributed database. Well dive deep into benchmarking methodologies and reveal practical insights about Azure storage performance characteristics.
It provides a large cluster of clusters on a single machine. AWS SageMaker is useful for creating basic models, including regression, classification, and clustering. Microsoft Azure Machine Learning Microsoft Azure Machine Learning is a set of tools for creating, managing, and analyzing models.
Microsoft Azure. Azure Arc You can now run Azure services anywhere (on-prem, on the edge, any cloud) you can run Kubernetes. Azure Synapse Analytics This is the future of data warehousing. AWS Parallel Cluster for Machine Learning AWS Parallel Cluster is an open-source cluster management tool.
Scikit-learn can be used for a variety of data analysis tasks, including: Classification Regression Clustering Dimensionality reduction Feature selection Leveraging Scikit-learn in data analysis projects Scikit-learn can be used in a variety of data analysis projects. RapidMiner was also used by the World Bank to develop a poverty index.
The skill clusters are formed via the discipline of Topic Modelling , a method from unsupervised machine learning , which show the differences in the distribution of requirements between them. DATANOMIQ Jobskills Webapp The whole web app is hosted and deployed on the Microsoft Azure Cloud via CI/CD and Infrastructure as Code (IaC).
The key here is to focus on concepts like supervised vs. unsupervised learning, regression, classification, clustering, and model evaluation. LLMOps Instructional Video Series - A comprehensive 5-part series with live demonstrations in Azure AI Studio, guiding you through various aspects of LLMOps.
Close to 30 minutes for 1TB Now read from parquet Create a Azure AD app registration Create a secret Store the clientid, secret, and tenantid in a keyvault add app id as data user, and also ingestor Provide contributor in Access IAM of the ADX cluster. format("com.microsoft.kusto.spark.datasource"). mode("Append").
In this post, well explore how different Azure disk types perform under distributed database workloads, using YugabyteDB as our distributed database. Well dive deep into benchmarking methodologies and reveal practical insights about Azure storage performance characteristics.
Azure is Microsoft’s public cloud platform. Azure offers a large collection of services, which includes platform as a service (PaaS), infrastructure as a service (IaaS) and managed database service capabilities. Azure Marketplace serves as the conduit through which this deployment is made possible.
I just finished learning Azure’s service cloud platform using Coursera and the Microsoft Learning Path for Data Science. But, since I did not know Azure or AWS, I was trying to horribly re-code them by hand with python and pandas; knowing these services on the cloud platform could have saved me a lot of time, energy, and stress.
Submission Suggestions Move Microsoft Graph metadata to Azure Data Explorer using pandas dataframe was originally published in MLearning.ai on Medium, where people are continuing the conversation by highlighting and responding to this story.
Microsoft’s cloud computing arm, Azure, tested a system of the exact same size and were behind Eos by mere seconds. Azure powers GitHub’s coding assistant CoPilot and OpenAI’s ChatGPT.) We delivered more than what was promised—a 103 percent reduction in time-to-train for a 384-accelerator cluster.”
I recently took the Azure Data Scientist Associate certification exam DP-100, thankfully I passed after about 3–4 months for studying the Microsoft Data Science Learning Path and the Coursera Microsoft Azure Data Scientist Associate Specialization. Resources include the: Resource group, Azure ML studio, Azure Compute Cluster.
Machine Learning (ML) algorithms: Clustering: Identification of similar data subsets. This integration serves to elevate the efficiency and effectiveness of search processes. Advanced AI integration Natural Language Processing (NLP): Enhances the understanding of unstructured data. Classification: Labeling new data based on existing datasets.
Submission Suggestions Predictive Maintenance using Azure Machine Learning AutoML and Inference using Managed Online… was originally published in MLearning.ai setup environment env = Environment( name="automl-tabular-env", description="environment for automl inference", #image="mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04:20210727.v1",
IBM’s recommendations included API-specific improvements, bot UX optimization, workflow optimization, DevOps microservices and design consideration, and best practices for Azure manage services.
External tables : External tables will allow us to query data stored in external cloud storage services like Amazon S3, Google Cloud Storage, or Azure Data Lake Storage without loading the data into Snowflake. Always set the minimum cluster count to 1 to prevent over-provisioning.
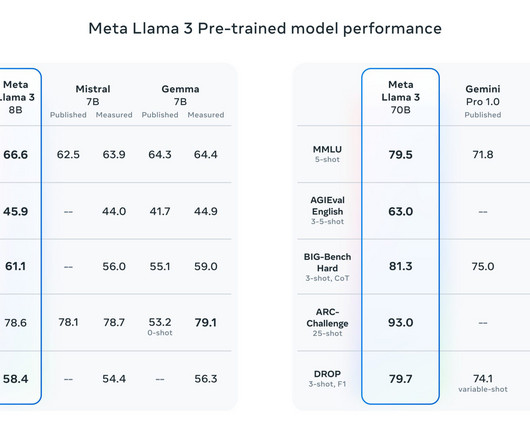
Performance and Innovation Meta’s LLaMA 3 has been trained on significantly larger datasets compared to earlier versions, utilizing custom-built GPU clusters that enable it to process vast amounts of data efficiently.
Build expertise in computer vision, clustering algorithms, deep learning essentials, multi-agent reinforcement, DQN, and more. USAII is an esteemed member of the Institute for Credentialing Excellence and ANSI. With speedster discounts and other on-program perks; you are sure to benefit from this world-class top AI certification.
The key components of Instana are host agents and agent sensors deployed on platforms like IBM Cloud®, AWS, and Azure. Supported cloud platforms with IBM Instana IBM Instana supports IBM Cloud, AWS, Azure and SAP. Currently, Instana supports SAP BTP Kyma cluster monitoring.
It then performs transformations using the Hadoop cluster or the features of the database. Azure Data Factory : This is a fully managed service that connects to a wide range of On-Premise and Cloud sources. It can easily transform, copy, and enrich the data, finally writing it to Azure data services as a destination.
Apache Hadoop Apache Hadoop is an open-source framework that allows for distributed storage and processing of large datasets across clusters of computers using simple programming models. Key Features : Scalability : Hadoop can handle petabytes of data by adding more nodes to the cluster. Statistics Kafka handles over 1.1
To ensure high availability and scalability, the mainframe is supported by a cluster of servers that work together to handle the bank’s computing needs. In addition to its mainframe, the bank has a strong relationship with Microsoft and leverages Microsoft Azure cloud platform to extend its IT infrastructure.
Commonly used technologies for data storage are the Hadoop Distributed File System (HDFS), Amazon S3, Google Cloud Storage (GCS), or Azure Blob Storage, as well as tools like Apache Hive, Apache Spark, and TensorFlow for data processing and analytics. All processing and machine-learning-related tasks are implemented in the analytics platform.
Autoscaling When traffic spikes, Kubernetes can automatically spin up new clusters to handle the additional workload. However, unlike VMs, Kubernetes orchestrates container interactions that transcend apps and clusters. This includes data in CI/CD pipelines (which feed into K8s clusters) and GitOps workflows (which power K8s clusters).
The strategic value of IoT development and data analytics Sierra Wireless Sierra Wireless , a wireless communications equipment designer and service provider, has been honing its focus on IoT software and managed services following its acquisition of M2M Group, a cluster of companies dedicated to IoT connectivity, in 2020.
Architecture At its core, Redshift consists of clusters made up of compute nodes, coordinated by a leader node that manages communications, parses queries, and executes plans by distributing tasks to the compute nodes. Its PostgreSQL foundation ensures compatibility with most SQL clients.
Clustering (Unsupervised). With Clustering the data is divided into groups. By applying clustering based on distance, the villages are divided into groups. The center of each cluster is the optimal location for setting up health centers. The center of each cluster is the optimal location for setting up health centers.
Nodes run the pods and are usually grouped in a Kubernetes cluster, abstracting the underlying physical hardware resources. As an open-source system, Kubernetes services are supported by all the leading public cloud providers, including IBM, Amazon Web Services (AWS), Microsoft Azure and Google.
High-Performance Computing (HPC) Clusters These clusters combine multiple GPUs or TPUs to handle extensive computations required for training large generative models. The demand for advanced hardware continues to grow as organisations seek to develop more sophisticated Generative AI applications.
Unsupervised Learning: Focuses on identifying patterns in unlabeled data, such as clustering customers based on purchasing behavior or reducing data dimensions for visualization. Cloud Computing: Scaling AI Solutions Cloud computing platforms like AWS, Google Cloud, and Microsoft Azure are indispensable for deploying and scaling AI models.
I mostly use U-SQL, a mix between C# and SQL that can distribute in very large clusters. Once the data is processed I do machine learning: clustering, topic finding, extraction, and classification. So you use a lot of the Azure tools in your job? It’s petabytes of data, so a lot of my time is spent processing it.
In this blog, we’ll review the DataRobot new Time Series clustering feature, which gives you a creative edge to build time series forecasting models by automatically grouping series that are identical to each other and then building models tailored to these groups. You can also connect to Snowflake, Azure, Redshift and many other databases.
Through the Pegasus program, Snorkel has access to premier sales resources and technical assets to accelerate AI workloads including early access to Azure AI services, leading models from OpenAI and Mistral, and accelerated high-performance compute. Snorkel’s recent top tier ranking on the AlpacaEval 2.0 LLM leaderboard.
Organizations that want to build their own models or want granular control are choosing Amazon Web Services (AWS) because we are helping customers use the cloud more efficiently and leverage more powerful, price-performant AWS capabilities such as petabyte-scale networking capability, hyperscale clustering, and the right tools to help you build.
Partitioning and clustering features inherent to OTFs allow data to be stored in a manner that enhances query performance. Cost Efficiency and Scalability Open Table Formats are designed to work with cloud storage solutions like Amazon S3, Google Cloud Storage, and Azure Blob Storage, enabling cost-effective and scalable storage solutions.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content