This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Since the field covers such a vast array of services, data scientists can find a ton of great opportunities in their field. Data scientists use algorithms for creating datamodels. These datamodels predict outcomes of new data. Data science is one of the highest-paid jobs of the 21st century.
By maintaining historical data from disparate locations, a data warehouse creates a foundation for trend analysis and strategic decision-making. BigQuery supports various data ingestion methods, including batch loading and streaming inserts, while automatically optimizing query execution plans through partitioning and clustering.
What if you could automatically shard your PostgreSQL database across any number of servers and get industry-leading performance at scale without any special datamodelling steps? Schema-based sharding has almost no datamodelling restrictions or special steps compared to unsharded PostgreSQL.
That’s why our data visualization SDKs are database agnostic: so you’re free to choose the right stack for your application. Multi-model databases combine graphs with two other NoSQL datamodels – document and key-value stores. Transactional, analytical, or both…?
Summary: The fundamentals of Data Engineering encompass essential practices like datamodelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is Data Engineering?
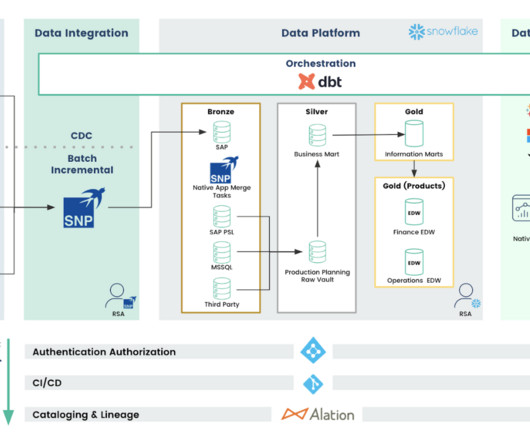
By centralizing SAP ERP data in Snowflake, organizations can gain deeper insights into key business metrics, trends, and performance indicators, enabling more informed decision-making, strategic planning, and operational optimization. Violations of license restrictions can result in penalties, additional fees, or even legal consequences.
Unsupervised Learning Unsupervised learning involves training models on data without labels, where the system tries to find hidden patterns or structures. This type of learning is used when labelled data is scarce or unavailable. Scalability Considerations Scalability is a key concern in model deployment.
We need robust versioning for data, models, code, and preferably even the internal state of applications—think Git on steroids to answer inevitable questions: What changed? Prior to the cloud, setting up and operating a cluster that can handle workloads like this would have been a major technical challenge.
The platform enables quick, flexible, and convenient options for storing, processing, and analyzing data. The solution was built on top of Amazon Web Services and is now available on Google Cloud and Microsoft Azure. Use Multiple DataModels With on-premise data warehouses, storing multiple copies of data can be too expensive.
Read More: Advanced SQL Tips and Tricks for Data Analysts. Hadoop Hadoop is an open-source framework designed for processing and storing big data across clusters of computer servers. It serves as the foundation for big data operations, enabling the storage and processing of large datasets.
Scikit-learn provides a consistent API for training and using machine learning models, making it easy to experiment with different algorithms and techniques. It also provides tools for model evaluation , including cross-validation, hyperparameter tuning, and metrics such as accuracy, precision, recall, and F1-score.
Model Development Data Scientists develop sophisticated machine-learning models to derive valuable insights and predictions from the data. These models may include regression, classification, clustering, and more. Data Warehousing: Amazon Redshift, Google BigQuery, etc.
SageMaker Studio offers built-in algorithms, automated model tuning, and seamless integration with AWS services, making it a powerful platform for developing and deploying machine learning solutions at scale. Metaflow Metaflow helps data scientists and machine learning engineers build, manage, and deploy data science projects.
You should test the entire ML model development chain, for example: Data collection: Test the quality, accuracy, and relevance of the data collected to ensure it meets the needs of the model. Feature creation: Validate and test the processes used to select, manipulate, and transform data.
In this article, we’ll explore how AI can transform unstructured data into actionable intelligence, empowering you to make informed decisions, enhance customer experiences, and stay ahead of the competition. What is Unstructured Data? Word2Vec , GloVe , and BERT are good sources of embedding generation for textual data.
LLM Gateways can enforce security policies, encrypt sensitive information, and manage access control to protect data. They act as a security layer, adding an extra level of protection when handling sensitive data. Model and Cloud Agnosticism Many LLM Gateways are designed to be model and cloud-agnostic.
NoSQL Databases NoSQL databases do not follow the traditional relational database structure, which makes them ideal for storing unstructured data. They allow flexible datamodels such as document, key-value, and wide-column formats, which are well-suited for large-scale data management.
A multilingual embedding model is an effective tool that combines semantic information for language understanding with the ability to encode text from various languages into a common embedding space. This allows it to be used for a variety of downstream tasks, including text classification, clustering, and others.
The data from D10 was never actually transferred to D11, meaning the business is now using 2 systems instead of 1. D11 datamodel doesn’t really support the data in D10 either. Technology teams demanded that BackEnd be built in Microsoft Azure Pipelines, to comply with “Strategic Vision”.
It’s almost like a specialized data processing and storage solution. For example, you can use BigQuery , AWS , or Azure. It can be a cluster run by Kubernetes or maybe something else. Mikiko Bazeley: Yeah, so we actually did a talk at Data Council. I would need to have the infrastructure to perform computations.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content