This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Azure Synapse provides a unified platform to ingest, explore, prepare, transform, manage, and serve data for BI (Business Intelligence) and machine learning needs. Introduction Dedicated SQL pools offer fast and reliable data import and analysis, allowing businesses to access accurate insights while optimizing performance and reducing costs.
Welcome to this comprehensive guide on Azure Machine Learning , Microsoft’s powerful cloud-based platform that’s revolutionizing how organizations build, deploy, and manage machine learning models. Sit back, relax, and enjoy this exploration of Azure Machine Learning’s capabilities, benefits, and practical applications.
Microsoft Azure. Azure Arc You can now run Azure services anywhere (on-prem, on the edge, any cloud) you can run Kubernetes. Azure Synapse Analytics This is the future of data warehousing. SQL Server 2019 SQL Server 2019 went Generally Available. Amazon Web Services. Google Cloud.
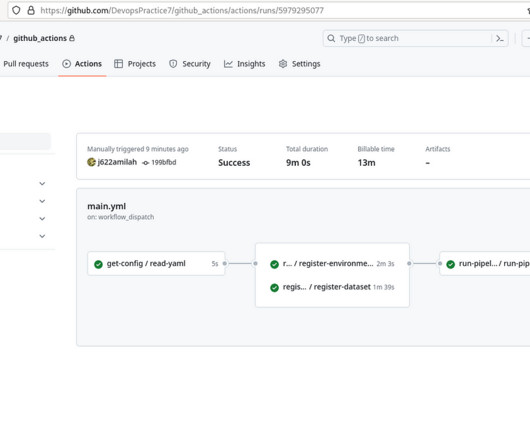
The skill clusters are formed via the discipline of Topic Modelling , a method from unsupervised machine learning , which show the differences in the distribution of requirements between them. DATANOMIQ Jobskills Webapp The whole web app is hosted and deployed on the Microsoft Azure Cloud via CI/CD and Infrastructure as Code (IaC).
I just finished learning Azure’s service cloud platform using Coursera and the Microsoft Learning Path for Data Science. But, since I did not know Azure or AWS, I was trying to horribly re-code them by hand with python and pandas; knowing these services on the cloud platform could have saved me a lot of time, energy, and stress.
I recently took the Azure Data Scientist Associate certification exam DP-100, thankfully I passed after about 3–4 months for studying the Microsoft Data Science Learning Path and the Coursera Microsoft Azure Data Scientist Associate Specialization. Resources include the: Resource group, Azure ML studio, Azure Compute Cluster.
IBM’s recommendations included API-specific improvements, bot UX optimization, workflow optimization, DevOps microservices and design consideration, and best practices for Azure manage services.
It then performs transformations using the Hadoop cluster or the features of the database. Azure Data Factory : This is a fully managed service that connects to a wide range of On-Premise and Cloud sources. It can easily transform, copy, and enrich the data, finally writing it to Azure data services as a destination. Conclusion.
Its PostgreSQL foundation ensures compatibility with most SQL clients. Architecture At its core, Redshift consists of clusters made up of compute nodes, coordinated by a leader node that manages communications, parses queries, and executes plans by distributing tasks to the compute nodes.
As such, you should begin by learning the basics of SQL. SQL is an established language used widely in data engineering. Just like programming, SQL has multiple dialects. Besides SQL, you should also learn how to model data. As a data engineer, you will be primarily working on databases. Follow Industry Trends.
Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deep learning. Databases and SQL : Managing and querying relational databases using SQL, as well as working with NoSQL databases like MongoDB.
Clustering (Unsupervised). With Clustering the data is divided into groups. By applying clustering based on distance, the villages are divided into groups. The center of each cluster is the optimal location for setting up health centers. The center of each cluster is the optimal location for setting up health centers.
I mostly use U-SQL, a mix between C# and SQL that can distribute in very large clusters. Once the data is processed I do machine learning: clustering, topic finding, extraction, and classification. So you use a lot of the Azure tools in your job? My data sources are usually news, logs and web documents.
Moreover, the cluster can be rebalanced based on disk usage, such that large schemas automatically get more resources dedicated to them, while small schemas are efficiently packed together. If you skip one of these steps, performance might be poor due to network overhead, or you might run into distributed SQL limitations. alert_id , m.
Partitioning and clustering features inherent to OTFs allow data to be stored in a manner that enhances query performance. Cost Efficiency and Scalability Open Table Formats are designed to work with cloud storage solutions like Amazon S3, Google Cloud Storage, and Azure Blob Storage, enabling cost-effective and scalable storage solutions.
Thirty seconds is a good default for human users; if you find that queries are regularly queueing, consider making your warehouse a multi-cluster that scales on-demand. Cluster Count If your warehouse has to serve many concurrent requests, you may need to increase the cluster count to meet demand. authorization server.
TensorFlow is desired for its flexibility for ML and neural networks, PyTorch for its ease of use and innate design for NLP, and scikit-learn for classification and clustering. Knowing some SQL is also essential. While even knowing one of these is attractive, being flexible and adaptable by knowing all three and more will really pop.
It was built using a combination of in-house and external cloud services on Microsoft Azure for large language models (LLMs), Pinecone for vectorized databases, and Amazon Elastic Compute Cloud (Amazon EC2) for embeddings. Opportunities for innovation CreditAI by Octus version 1.x x uses Retrieval Augmented Generation (RAG).
One is a scripting language such as Python, and the other is a Query language like SQL (Structured Query Language) for SQL Databases. There is one Query language known as SQL (Structured Query Language), which works for a type of database. SQL Databases are MySQL , PostgreSQL , MariaDB , etc.
It has the following features: It facilitates querying, summarizing, and analyzing large datasets Hadoop also provides a SQL-like language called HiveQL Hive allows users to write queries to extract valuable insights from structured and semi-structured data stored in Hadoop. Hive is a data warehousing infrastructure built on top of Hadoop.
Familiarity with libraries like pandas, NumPy, and SQL for data handling is important. Check out this course to upskill on Apache Spark — [link] Cloud Computing technologies such as AWS, GCP, Azure will also be a plus. This includes skills in data cleaning, preprocessing, transformation, and exploratory data analysis (EDA).
In this post, we’ll take a look at some of the factors you could investigate, and introduce the six databases our customers work with most often: Amazon Neptune ArangoDB Azure Cosmos DB JanusGraph Neo4j TigerGraph Why these six graph databases? Relational databases (with recursive SQL queries), document stores, key-value stores, etc.,
Iceberg tables in Snowflake Data Cloud are a new type of table where the actual data is stored outside Snowflake in a public cloud object storage location (Amazon S3, Google Cloud Storage, or Azure Storage) in Apache Iceberg table format which can be accessed by Snowflake using objects called external volume and catalog integration.
Microsoft SQL Server Integration Services (SSIS) Microsoft SQL Server Integration Services (SSIS) is an enterprise-level platform for data integration and transformation. Read More: Advanced SQL Tips and Tricks for Data Analysts. How to drop a database in SQL server? Read Further: Azure Data Engineer Jobs.
With expertise in programming languages like Python , Java , SQL, and knowledge of big data technologies like Hadoop and Spark, data engineers optimize pipelines for data scientists and analysts to access valuable insights efficiently. These models may include regression, classification, clustering, and more.
The solution was built on top of Amazon Web Services and is now available on Google Cloud and Microsoft Azure. Multi-Cloud Options You can host Snowflake on numerous popular cloud platforms, including Microsoft Azure, Google Cloud, and Amazon Web Services. Therefore, the tool is referred to as cloud-agnostic. What does Snowflake do?
We had bigger sessions on getting started with machine learning or SQL, up to advanced topics in NLP, and how to make deepfakes. On Wednesday, Henk Boelman, Senior Cloud Advocate at Microsoft, spoke about the current landscape of Microsoft Azure, as well as some interesting use cases and recent developments.
The shared-nothing architecture ensures that users don’t have to worry about distributing data across multiple cluster nodes. Snowflake hides user data objects and makes them accessible only through SQL queries through the compute layer. Cloud Storage Snowflake leverages the cloud’s native object storage services (e.g.
And the highlight, for us data intelligence folks, was the Databricks’ announcement that Unity Catalog , its unified governance solution for all data assets on its Lakehouse platform, will soon be available on AWS and Azure in the upcoming weeks. A simple model to control access to data via a UI or SQL. and much more!
Various types of storage options are available, including: Relational Databases: These databases use Structured Query Language (SQL) for data management and are ideal for handling structured data with well-defined relationships. SQLSQL is crucial for querying and managing relational databases.
It covers essential topics such as SQL queries, data visualization, statistical analysis, machine learning concepts, and data manipulation techniques. Key Takeaways SQL Mastery: Understand SQL’s importance, join tables, and distinguish between SELECT and SELECT DISTINCT. How do you join tables in SQL?
Speed Kafka’s data processing system uses APIs in a unique way that help it to optimize data integration to many other database storage designs, such as the popular SQL and NoSQL architectures , used for big data analytics. Developers using Apache can speed app development with support for whatever requirements their organization has.
Many enterprises, large or small, are storing data in cloud object storage like AWS S3, Azure ADLS Gen2, or Google Bucket because it offers scalable and cost-effective solutions for managing vast amounts of data. Figure 1 Figure 2 To understand the table design of an external table, you can run the desc external table SQL statement.
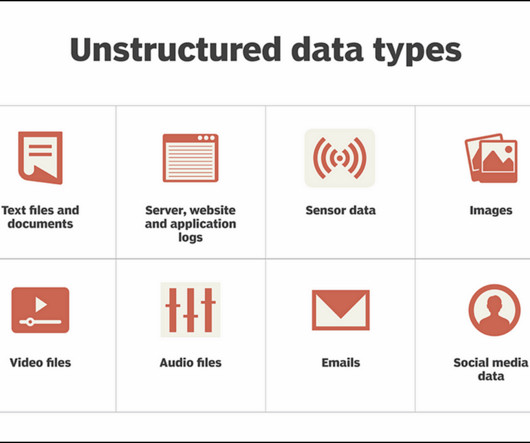
Relational databases (like MySQL) or No-SQL databases (AWS DynamoDB) can store structured or even semi-structured data but there is one inherent problem. A database that help index and search at blazing speed. Unstructured data is hard to store in relational databases.
It offers implementations of various machine learning algorithms, including linear and logistic regression , decision trees , random forests , support vector machines , clustering algorithms , and more. It is commonly used in MLOps workflows for deploying and managing machine learning models and inference services.
Microsoft Azure ML Platform The Azure Machine Learning platform provides a collaborative workspace that supports various programming languages and frameworks. Kubeflow integrates with popular ML frameworks, supports versioning and collaboration, and simplifies the deployment and management of ML pipelines on Kubernetes clusters.
These outputs, stored in vector databases like Weaviate, allow Prompt Enginers to directly access these embeddings for tasks like semantic search, similarity analysis, or clustering. R also excels in data analysis and visualization, which are important in understanding the output of LLMs and in fine-tuning prompt strategies.
While knowing Python, R, and SQL is expected, youll need to go beyond that. Similar to previous years, SQL is still the second most popular skill, as its used for many backend processes and core skills in computer science and programming. Employers arent just looking for people who can program.
Tools like pandas and SQL help manipulate and query data , while libraries such as matplotlib and Seaborn are used for data visualisation. Algorithm and Model Development Understanding various Machine Learning algorithms—such as regression , classification , clustering , and neural networks —is fundamental.
Here’s the structured equivalent of this same data in tabular form: With structured data, you can use query languages like SQL to extract and interpret information. Popular data lake solutions include Amazon S3 , Azure Data Lake , and Hadoop. This text has a lot of information, but it is not structured.
Orchestrators are concerned with lower-level abstractions like machines, instances, clusters, service-level grouping, replication, and so on. I have worked with customers where R and SQL were the first-class languages of their data science community.
Understanding Matillion and Snowflake, the Python Component, and Why it is Used Matillion is a SaaS-based data integration platform that can be hosted in AWS, Azure, or GCP and supports multiple cloud data warehouses. After this, we can use the Matillion SQL component to run the memory processing logic as SQL or Stored procedure in Snowflake.
You see them all the time with a headline like: “data science, machine learning, Java, Python, SQL, or blockchain, computer vision.” For example, you can use BigQuery , AWS , or Azure. We assume that they want to do stuff they normally would, with Python, SQL, and PySpark, with data frames. It’s two things.
Azure Data Studio has rapidly gained popularity among developers and database administrators for its user-friendly design and powerful features. As a versatile tool, it simplifies the management of both SQL Server and AzureSQL databases, offering a modern alternative to traditional database management solutions.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content