This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
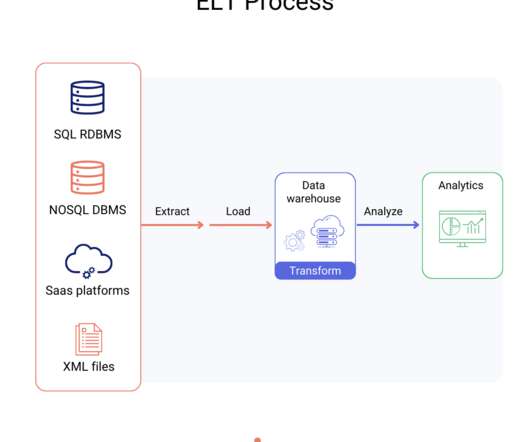
Data Science Dojo is offering Airbyte for FREE on Azure Marketplace packaged with a pre-configured web environment enabling you to quickly start the ELT process rather than spending time setting up the environment. If you can’t import all your data, you may only have a partial picture of your business.
With this full-fledged solution, you don’t have to spend all your time and effort combining different services or duplicating data. OneLake, being built on AzureData Lake Storage (ADLS), supports various data formats, including Delta, Parquet, CSV, and JSON.
Summary: This blog provides a comprehensive roadmap for aspiring AzureData Scientists, outlining the essential skills, certifications, and steps to build a successful career in Data Science using Microsoft Azure. What is Azure?
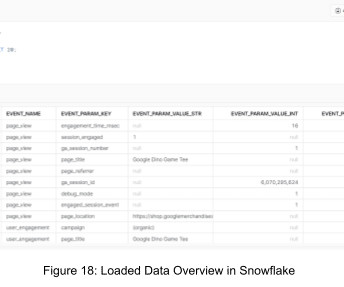
Google Analytics 4 (GA4) is a powerful tool for collecting and analyzing website and app data that many businesses rely heavily on to make informed business decisions. However, there might be instances where you need to migrate the raw eventdata from GA4 to Snowflake for more in-depth analysis and business intelligence purposes.
You can see our photos from the event here , and be sure to follow our YouTube for virtual highlights from the conference as well. Over in San Francisco, we had a keynote for each day of the event. Other Events Aside from networking events and all of our sessions, we had a few other special events.
Data Engineering : Building and maintaining datapipelines, ETL (Extract, Transform, Load) processes, and data warehousing. Cloud Computing : Utilizing cloud services for data storage and processing, often covering platforms such as AWS, Azure, and Google Cloud.
Recognizing these specific needs, Fivetran has developed a range of connectors, including dedicated applications, databases, files, and events, which can accommodate the diverse formats used by healthcare systems. Addressing these needs may pose challenges that lead to the implementation of custom solutions rather than a uniform approach.
MLOps aims to bridge the gap between data science and operational teams so they can reliably and efficiently transition ML models from development to production environments, all while maintaining high model performance and accuracy. AIOps integrates these models into existing IT systems to enhance their functions and performance.
Enterprise data architects, data engineers, and business leaders from around the globe gathered in New York last week for the 3-day Strata Data Conference , which featured new technologies, innovations, and many collaborative ideas. We look at data as an asset, regardless of whether the use case is AML/fraud or new revenue.
Apache Kafka is an open-source , distributed streaming platform that allows developers to build real-time, event-driven applications. With Apache Kafka, developers can build applications that continuously use streaming data records and deliver real-time experiences to users.
This unified schema streamlines downstream consumption and analytics because the data follows a standardized schema and new sources can be added with minimal datapipeline changes. After the security log data is stored in Amazon Security Lake, the question becomes how to analyze it.
Effective data governance enhances quality and security throughout the data lifecycle. What is Data Engineering? Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. They are crucial in ensuring data is readily available for analysis and reporting.
In the later part of this article, we will discuss its importance and how we can use machine learning for streaming data analysis with the help of a hands-on example. What is streaming data? This will also help us observe the importance of stream data. It can be used to collect, store, and process streaming data in real-time.
Microsoft Azure ML Platform The Azure Machine Learning platform provides a collaborative workspace that supports various programming languages and frameworks. Monte Carlo Monte Carlo is a popular data observability platform that provides real-time monitoring and alerting for data quality issues.
Apache Kafka For data engineers dealing with real-time data, Apache Kafka is a game-changer. This open-source streaming platform enables the handling of high-throughput data feeds, ensuring that datapipelines are efficient, reliable, and capable of handling massive volumes of data in real-time.
Data engineers will also work with data scientists to design and implement datapipelines; ensuring steady flows and minimal issues for data teams. They’ll also work with software engineers to ensure that the data infrastructure is scalable and reliable. Interested in attending an ODSC event?
Today, all leading CSPs, including Amazon Web Services (AWS Lambda), Microsoft Azure (Azure Functions) and IBM (IBM Cloud Code Engine) offer serverless platforms. In a serverless model, an event triggers app code to run. Automated serverless functions are stateless and designed to handle individual events.
This article was co-written by Mayank Singh & Ayush Kumar Singh Your organization’s datapipelines will inevitably run into issues, ranging from simple permission errors to significant network or infrastructure incidents. Failed Webhooks If webhooks are configured and the webhook event fails, a notification will be sent out.
What Are the Best Third-Party Data Ingestion Tools for Snowflake? Fivetran Fivetran is a tool dedicated to replicating applications, databases, events, and files into a high-performance data warehouse, such as Snowflake. Tips When Considering ADF: ADF will only write to Snowflake accounts that are based in Azure.
DataRobot now delivers both visual and code-centric data preparation and datapipelines, along with automated machine learning that is composable, and can be driven by hosted notebooks or a graphical user experience. Virtual Event. Modular and Extensible, Building on Existing Investments. Every organization is unique.
The platform enables quick, flexible, and convenient options for storing, processing, and analyzing data. The solution was built on top of Amazon Web Services and is now available on Google Cloud and Microsoft Azure. Each model carries its specific benefits and allows for reloading and reprocessing of data in the event of errors.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
High demand has risen from a range of sectors, including crypto mining, gaming, generic data processing, and AI. Socio-political events have also caused delays and issues, such as a COVID backlog, and with inert gases for manufacturing coming from Russia. All the way through this pipeline, activities could be accelerated using PBAs.
Whether you rely on cloud-based services like Amazon SageMaker , Google Cloud AI Platform, or Azure Machine Learning or have developed your custom ML infrastructure, Comet integrates with your chosen solution. It goes beyond compatibility with open-source solutions and extends its support to managed services and in-house ML platforms.
This two-part series will explore how data discovery, fragmented data governance , ongoing data drift, and the need for ML explainability can all be overcome with a data catalog for accurate data and metadata record keeping. The Cloud Data Migration Challenge. Datapipeline orchestration.
Data Engineering Data engineering remains integral to many data science roles, with workflow pipelines being a key focus. Tools like Apache Airflow are widely used for scheduling and monitoring workflows, while Apache Spark dominates big datapipelines due to its speed and scalability.
Data Science Dojo is offering Memphis broker for FREE on Azure Marketplace preconfigured with Memphis, a platform that provides a P2P architecture, scalability, storage tiering, fault-tolerance, and security to provide real-time processing for modern applications suitable for large volumes of data. Try Memphis Now !
The service will consume the features in real time, generate predictions in near real-time , such as in an event processing pipeline, and write the outputs to a prediction queue. Solution Data lakes and warehouses are the two key components of any datapipeline. Data engineers are mostly in charge of it.
However, if the tool supposes an option where we can write our custom programming code to implement features that cannot be achieved using the drag-and-drop components, it broadens the horizon of what we can do with our datapipelines. The default value is 360 seconds. If not, it will retry after a certain duration (E.g., 30 minutes).
Methods that allow our customer data models to be as dynamic and flexible as the customers they represent. In this guide, we will explore concepts like transitional modeling for customer profiles, the power of event logs for customer behavior, persistent staging for raw customer data, real-time customer data capture, and much more.
Summary: Data engineering tools streamline data collection, storage, and processing. Learning these tools is crucial for building scalable datapipelines. offers Data Science courses covering these tools with a job guarantee for career growth. Below are 20 essential tools every data engineer should know.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content