This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Machine learning (ML) is the technology that automates tasks and provides insights. It allows data scientists to build models that can automate specific tasks. It comes in many forms, with a range of tools and platforms designed to make working with ML more efficient. It also has ML algorithms built into the platform.
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.
Each platform offers unique capabilities tailored to varying needs, making the platform a critical decision for any Data Science project. Major Cloud Platforms for Data Science Amazon Web Services ( AWS ), Microsoft Azure, and Google Cloud Platform (GCP) dominate the cloud market with their comprehensive offerings.
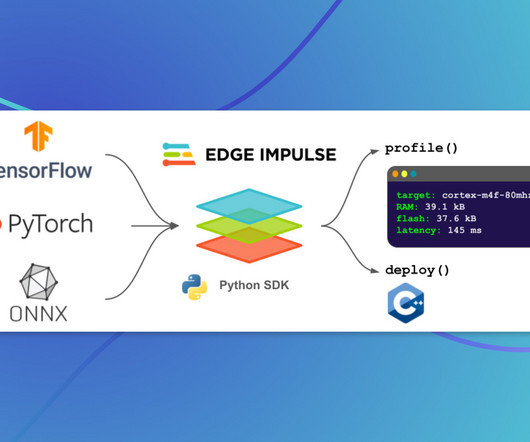
Last Updated on April 4, 2023 by Editorial Team Introducing a Python SDK that allows enterprises to effortlessly optimize their ML models for edge devices. With their groundbreaking web-based Studio platform, engineers have been able to collect data, develop and tune ML models, and deploy them to devices.
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
Together with Azure by Microsoft, and Google Cloud Platform from Google, AWS is one of the three mousquetters of Cloud based platforms, and a solution that many businesses use in their day to day. AWS ML removes traditional barriers to entry while providing professional-grade capabilities.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
Long-term ML project involves developing and sustaining applications or systems that leverage machine learning models, algorithms, and techniques. An example of a long-term ML project will be a bank fraud detection system powered by ML models and algorithms for pattern recognition. 2 Ensuring and maintaining high-quality data.
Instead, businesses tend to rely on advanced tools and strategies—namely artificial intelligence for IT operations (AIOps) and machine learning operations (MLOps)—to turn vast quantities of data into actionable insights that can improve IT decision-making and ultimately, the bottom line.
Cloud Computing, APIs, and Data Engineering NLP experts don’t go straight into conducting sentiment analysis on their personal laptops. TensorFlow is desired for its flexibility for ML and neural networks, PyTorch for its ease of use and innate design for NLP, and scikit-learn for classification and clustering.
Cloud certifications, specifically in AWS and Microsoft Azure, were most strongly associated with salary increases. As we’ll see later, cloud certifications (specifically in AWS and Microsoft Azure) were the most popular and appeared to have the largest effect on salaries. Many respondents acquired certifications. Salaries by Gender.
Unleashing Innovation and Success: Comet — The Trusted ML Platform for Enterprise Environments Machine learning (ML) is a rapidly developing field, and businesses are increasingly depending on ML platforms to fuel innovation, improve efficiency, and mine data for insights.
Source: Author Introduction Machine learning (ML) models, like other software, are constantly changing and evolving. Version control systems (VCS) play a key role in this area by offering a structured method to track changes made to models and handle versions of data and code used in these ML projects.
Just as a writer needs to know core skills like sentence structure, grammar, and so on, data scientists at all levels should know core data science skills like programming, computer science, algorithms, and so on. As MLOps become more relevant to ML demand for strong software architecture skills will increase as well.
Dolt LakeFS Delta Lake Pachyderm Git-like versioning Database tool Data lake Datapipelines Experiment tracking Integration with cloud platforms Integrations with ML tools Examples of data version control tools in ML DVC Data Version Control DVC is a version control system for data and machine learning teams.
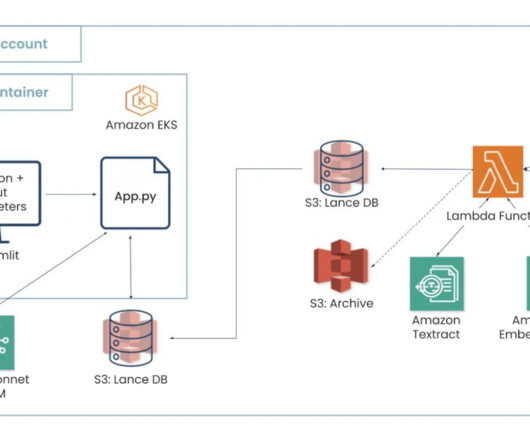
A novel approach to solve this complex security analytics scenario combines the ingestion and storage of security data using Amazon Security Lake and analyzing the security data with machine learning (ML) using Amazon SageMaker. Deploy the trained ML model to a SageMaker inference endpoint.
A traditional machine learning (ML) pipeline is a collection of various stages that include data collection, data preparation, model training and evaluation, hyperparameter tuning (if needed), model deployment and scaling, monitoring, security and compliance, and CI/CD. What is MLOps?
Familiar Client Side Libraries – Snowpark brings in-house and deeply integrated, DataFrame-style programming abstract and OSS-compatible APIs to the languages data practitioners like to use (Python, Scala, etc). It also includes the Snowpark ML API for more efficient machine language (ML) modeling and ML operations.
And, as organizations progress and grow, “data drift” starts to impact data usage, models, and your business. In today’s AI/ML-driven world of data analytics, explainability needs a repository just as much as those doing the explaining need access to metadata, EG, information about the data being used.
This pipeline facilitates the smooth, automated flow of information, preventing many problems that enterprises face, such as data corruption, conflict, and duplication of data entries. A streaming datapipeline is an enhanced version which is able to handle millions of events in real-time at scale. Happy Learning!
To help, phData designed and implemented AI-powered datapipelines built on the Snowflake AI Data Cloud , Fivetran, and Azure to automate invoice processing. Migrations from legacy on-prem systems to cloud data platforms like Snowflake and Redshift. This is where AI truly shines.
Managing unstructured data is essential for the success of machine learning (ML) projects. Without structure, data is difficult to analyze and extracting meaningful insights and patterns is challenging. This article will discuss managing unstructured data for AI and ML projects. What is Unstructured Data?
In this blog, we’ll show you how to build a robust energy price forecasting solution within the Snowflake Data Cloud ecosystem. We’ll cover how to get the data via the Snowflake Marketplace, how to apply machine learning with Snowpark , and then bring it all together to create an automated ML model to forecast energy prices.
It does not support the ‘dvc repro’ command to reproduce its datapipeline. DVC Released in 2017, Data Version Control ( DVC for short) is an open-source tool created by iterative. However, these tools have functional gaps for more advanced data workflows.
Today, all leading CSPs, including Amazon Web Services (AWS Lambda), Microsoft Azure (Azure Functions) and IBM (IBM Cloud Code Engine) offer serverless platforms. Today, serverless helps developers build scalable big datapipelines without having to manage the underlying infrastructure.
Automation Automation plays a pivotal role in streamlining ETL processes, reducing the need for manual intervention, and ensuring consistent data availability. By automating key tasks, organisations can enhance efficiency and accuracy, ultimately improving the quality of their datapipelines.
The platform enables quick, flexible, and convenient options for storing, processing, and analyzing data. The solution was built on top of Amazon Web Services and is now available on Google Cloud and Microsoft Azure. ML models, in turn, require significant volumes of adequate data to ensure accuracy.
This includes important stages such as feature engineering, model development, datapipeline construction, and data deployment. For example, when it comes to deploying projects on cloud platforms, different companies may utilize different providers like AWS, GCP, or Azure.
As MLOps become more relevant to ML demand for strong software architecture skills will increase aswell. Machine Learning As machine learning is one of the most notable disciplines under data science, most employers are looking to build a team to work on ML fundamentals like algorithms, automation, and so on.
Fine-tune Your Own Open-Source SLMs Devvret Rishi, CEO of Predibase, and Chloe Leung, ML solutions architect at Predibase Discover how to cost-effectively customize open-source small language models (SLMs) to outperform GPT-4 on various tasks. Cloning NotebookLM with Open Weights Models Niels Bantilan, Chief ML Engineer atUnion.AI
The generative AI solutions from GCP Vertex AI, AWS Bedrock, Azure AI, and Snowflake Cortex all provide access to a variety of industry-leading foundational models. This option also has minimal upfront infrastructure cost and operates on a pay-as-you-go model when using models.
Both persistent staging and data lakes involve storing large amounts of raw data. But persistent staging is typically more structured and integrated into your overall customer datapipeline. It’s not just a dumping ground for data, but a crucial step in your customer data processing workflow.
These activities cover disparate fields such as basic data processing, analytics, and machine learning (ML). ML is often associated with PBAs, so we start this post with an illustrative figure. The ML paradigm is learning followed by inference. The union of advances in hardware and ML has led us to the current day.
TL;DR Bias is inherent to building a ML model. Adhering to data protection laws is not as complex if we focus less on the internal structure of the algorithms and more on the practical contexts of use. Hosting the model in secure, GDPR-compliant cloud environments, such as Amazon Web Services or Azure. Bias exists on a spectrum.
From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. As the number of ML-powered apps and services grows, it gets overwhelming for data scientists and ML engineers to build and deploy models at scale.
As a Data Analyst, you’ve honed your skills in data wrangling, analysis, and communication. But the allure of tackling large-scale projects, building robust models for complex problems, and orchestrating datapipelines might be pushing you to transition into Data Science architecture.
There is a VSCode Extension that enables its integration into traditional development pipelines. How to use the Codex models to work with code - Azure OpenAI Service Codex is the model powering Github Copilot. GPT-4 DataPipelines: Transform JSON to SQL Schema Instantly Blockstream’s public Bitcoin API.
DataRobot now delivers both visual and code-centric data preparation and datapipelines, along with automated machine learning that is composable, and can be driven by hosted notebooks or a graphical user experience. Modular and Extensible, Building on Existing Investments. Every organization is unique.
Why Migrate to a Modern Data Stack? Data teams can focus on delivering higher-value data tasks with better organizational visibility. Move Beyond One-off Analytics: The Modern Data Stack empowers you to elevate your data for advanced analytics and integration of AI/ML, enabling faster generation of actionable business insights.
Simply put, focusing solely on data analysis, coding or modeling will no longer cuts it for most corporate jobs. You have to understand data, how to extract value from them and how to monitor model performances. AWS, Google Cloud, or Azure) is essential. Cloud platforms: Expertise in at least one major cloud provider (e.g.,
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content