This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data Science Dojo is offering Meltano CLI for FREE on Azure Marketplace preconfigured with Meltano, a platform that provides flexibility and scalability. Modern stack : It is built using modern open-source technologies such as Python, Flask, and Vue.js, making it easy to extend and integrate with other tools. It is customizable.
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
Summary: This blog provides a comprehensive roadmap for aspiring AzureData Scientists, outlining the essential skills, certifications, and steps to build a successful career in Data Science using Microsoft Azure. What is Azure?
We also discuss different types of ETL pipelines for ML use cases and provide real-world examples of their use to help data engineers choose the right one. What is an ETL datapipeline in ML? Xoriant It is common to use ETL datapipeline and datapipeline interchangeably.
Data engineering is a crucial field that plays a vital role in the datapipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and data engineers are responsible for designing and implementing the systems and infrastructure that make this possible.
This better reflects the common Python practice of having your top level module be the project name. Data storage ¶ V1 was designed to encourage data scientists to (1) separate their data from their codebase and (2) store their data on the cloud. We have now added support for Azure and GCS as well.
Together with Azure by Microsoft, and Google Cloud Platform from Google, AWS is one of the three mousquetters of Cloud based platforms, and a solution that many businesses use in their day to day. That’s where Amazon Web Services shines, offering a comprehensive suite of tools that simplify the entire process.
Cloud Computing, APIs, and Data Engineering NLP experts don’t go straight into conducting sentiment analysis on their personal laptops. Data Engineering Platforms Spark is still the leader for datapipelines but other platforms are gaining ground. Knowing some SQL is also essential.
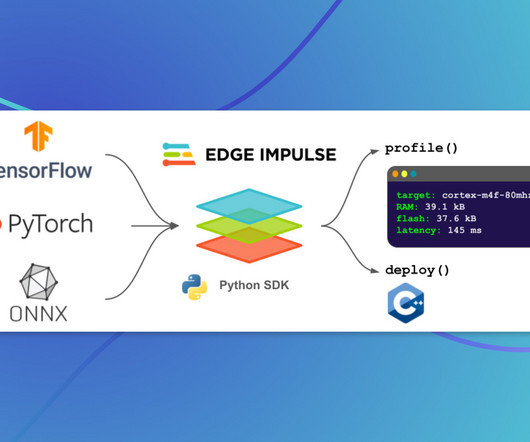
Last Updated on April 4, 2023 by Editorial Team Introducing a Python SDK that allows enterprises to effortlessly optimize their ML models for edge devices. Coupled with BYOM, the new Python SDK streamlines workflows even further, letting ML teams leverage Edge Impulse directly from their own development environments.
Snowpark, offered by the Snowflake AI Data Cloud , consists of libraries and runtimes that enable secure deployment and processing of non-SQL code, such as Python, Java, and Scala. In this blog, we’ll cover the steps to get started, including: How to set up an existing Snowpark project on your local system using a Python IDE.
Data science bootcamps are intensive short-term educational programs designed to equip individuals with the skills needed to enter or advance in the field of data science. They cover a wide range of topics, ranging from Python, R, and statistics to machine learning and data visualization.
This doesn’t mean anything too complicated, but could range from basic Excel work to more advanced reporting to be used for data visualization later on. Computer Science and Computer Engineering Similar to knowing statistics and math, a data scientist should know the fundamentals of computer science as well.
Cloud certifications, specifically in AWS and Microsoft Azure, were most strongly associated with salary increases. As we’ll see later, cloud certifications (specifically in AWS and Microsoft Azure) were the most popular and appeared to have the largest effect on salaries. Many respondents acquired certifications. What about Kafka?
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., Microsoft Azure ML Platform The Azure Machine Learning platform provides a collaborative workspace that supports various programming languages and frameworks.
As a Data Analyst, you’ve honed your skills in data wrangling, analysis, and communication. But the allure of tackling large-scale projects, building robust models for complex problems, and orchestrating datapipelines might be pushing you to transition into Data Science architecture.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage.
Effective data governance enhances quality and security throughout the data lifecycle. What is Data Engineering? Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. They are crucial in ensuring data is readily available for analysis and reporting.
Some of our most popular in-person sessions were: MLOps: Monitoring and Managing Drift: Oliver Zeigermann | Machine Learning Architect ODSC Keynote: Human-Centered AI: Peter Norvig, PhD | Engineering Director, Education Fellow | Google, Stanford Institute for Human-Centered Artificial Intelligence (HAI) The Cost of AI Compute and Why AI Clouds Will (..)
This individual is responsible for building and maintaining the infrastructure that stores and processes data; the kinds of data can be diverse, but most commonly it will be structured and unstructured data. They’ll also work with software engineers to ensure that the data infrastructure is scalable and reliable.
Best practices are a pivotal part of any software development, and data engineering is no exception. This ensures the datapipelines we create are robust, durable, and secure, providing the desired data to the organization effectively and consistently.
Applying Machine Learning with Snowpark Now that we have our data from the Snowflake Marketplace, it’s time to leverage Snowpark to apply machine learning. Python has long been the favorite programming language of data scientists. For a short demo on Snowpark, be sure to check out the video below.
If using a network policy with Snowflake, be sure to add Fivetran’s IP address list , which will ensure AzureData Factory (ADF) AzureData Factory is a fully managed, serverless data integration service built by Microsoft. Source data formats can only be Parquer, JSON, or Delimited Text (CSV, TSV, etc.).
The software you might use OAuth with includes: Tableau Power BI Sigma Computing If so, you will need an OAuth provider like Okta, Microsoft Azure AD, Ping Identity PingFederate, or a Custom OAuth 2.0 When to use SCIM vs phData's Provision Tool SCIM manages users and groups with Azure Active Directory or Okta. authorization server.
IBM Infosphere DataStage IBM Infosphere DataStage is an enterprise-level ETL tool that enables users to design, develop, and run datapipelines. Key Features: Graphical Framework: Allows users to design datapipelines with ease using a graphical user interface. Read Further: AzureData Engineer Jobs.
This pipeline facilitates the smooth, automated flow of information, preventing many problems that enterprises face, such as data corruption, conflict, and duplication of data entries. A streaming datapipeline is an enhanced version which is able to handle millions of events in real-time at scale. Happy Learning!
How to use the Codex models to work with code - Azure OpenAI Service Codex is the model powering Github Copilot. GPT-4 DataPipelines: Transform JSON to SQL Schema Instantly Blockstream’s public Bitcoin API. The data would be interesting to analyze. The article has good points with any LLM Use prompt to guide.
Scikit-learn Scikit-learn is a machine learning library in Python that is majorly used for data mining and data analysis. Similar to SageMaker, Azure ML offers a range of tools and services for the entire machine learning lifecycle, from data preparation and model development to deployment and monitoring.
Dolt LakeFS Delta Lake Pachyderm Git-like versioning Database tool Data lake Datapipelines Experiment tracking Integration with cloud platforms Integrations with ML tools Examples of data version control tools in ML DVC Data Version Control DVC is a version control system for data and machine learning teams.
With these tools, you can create separate environments with specific Python versions and all the necessary Python libraries in them. This ensures that each Python project can run within its own environment and with a specified Python version, without bothering other Python projects.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
This unified schema streamlines downstream consumption and analytics because the data follows a standardized schema and new sources can be added with minimal datapipeline changes. After the security log data is stored in Amazon Security Lake, the question becomes how to analyze it. For Runtime , choose Python 3.10.
Computer Science and Computer Engineering Similar to knowing statistics and math, a data scientist should know the fundamentals of computer science as well. While knowing Python, R, and SQL is expected, youll need to go beyond that. Employers arent just looking for people who can program.
Finally, participants will build their own AI Agent from scratch using Python and AI orchestrators like LangChain. Participants will dive into building real-world AI applications such as chatbots, AI agents, RAG systems, recommendation engines, and datapipelines.
In terms of resulting speedups, the approximate order is programming hardware, then programming against PBA APIs, then programming in an unmanaged language such as C++, then a managed language such as Python. The CUDA platform is used through complier directives and extensions to standard languages, such as the Python cuNumeric library.
Think about it this way: it is easy to integrate GDPR-compliant services like ChatGPTs enterprise version or to use AI models in a law-compliant way through platforms such as Azures OpenAI offering , as providers take the necessary steps to ensure their platforms are compliant with regulations. gender, race, age).
.” — Conor Murphy , Lead Data Scientist at Databricks, in “Survey of Production ML Tech Stacks” at the Data+AI Summit 2022 Your team should be motivated by MLOps to show everything that goes into making a machine learning model, from getting the data to deploying and monitoring the model.
However, if the tool supposes an option where we can write our custom programming code to implement features that cannot be achieved using the drag-and-drop components, it broadens the horizon of what we can do with our datapipelines. Top 10 Python Scripts for use in Matillion for Snowflake 1. The default value is Python3.
Data Science Dojo is offering Memphis broker for FREE on Azure Marketplace preconfigured with Memphis, a platform that provides a P2P architecture, scalability, storage tiering, fault-tolerance, and security to provide real-time processing for modern applications suitable for large volumes of data. Try Memphis Now !
Datapipeline orchestration tools are designed to automate and manage the execution of datapipelines. These tools help streamline and schedule data movement and processing tasks, ensuring efficient and reliable data flow. What are Orchestration Tools?
Uncomfortable reality: In the era of large language models (LLMs) and AutoML, traditional skills like Python scripting, SQL, and building predictive models are no longer enough for data scientist to remain competitive in the market. You have to understand data, how to extract value from them and how to monitor model performances.
Summary: Data engineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable datapipelines.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content