This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Continuous Integration and Continuous Delivery (CI/CD) for DataPipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable datapipelines is paramount in data science and data engineering. They transform data into a consistent format for users to consume.
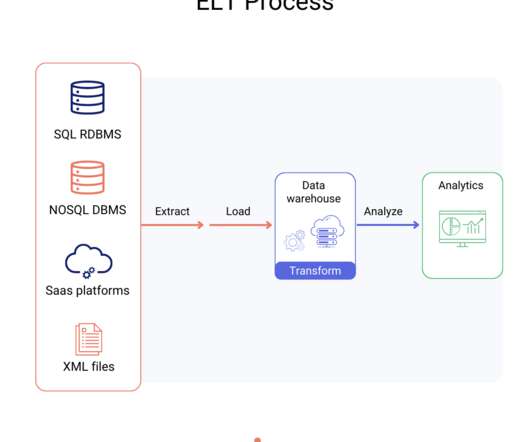
Introduction Azuredata factory (ADF) is a cloud-based data ingestion and ETL (Extract, Transform, Load) tool. The data-driven workflow in ADF orchestrates and automates data movement and data transformation.
Data Science Dojo is offering Airbyte for FREE on Azure Marketplace packaged with a pre-configured web environment enabling you to quickly start the ELT process rather than spending time setting up the environment. If you can’t import all your data, you may only have a partial picture of your business.
With this full-fledged solution, you don’t have to spend all your time and effort combining different services or duplicating data. OneLake, being built on AzureData Lake Storage (ADLS), supports various data formats, including Delta, Parquet, CSV, and JSON.
Data engineering is a crucial field that plays a vital role in the datapipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and data engineers are responsible for designing and implementing the systems and infrastructure that make this possible.
A lot of Open-Source ETL tools house a graphical interface for executing and designing DataPipelines. It can be used to manipulate, store, and analyze data of any structure. It generates Java code for the DataPipelines instead of running Pipeline configurations through an ETL Engine. Conclusion.
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
Summary: This blog provides a comprehensive roadmap for aspiring AzureData Scientists, outlining the essential skills, certifications, and steps to build a successful career in Data Science using Microsoft Azure. What is Azure?
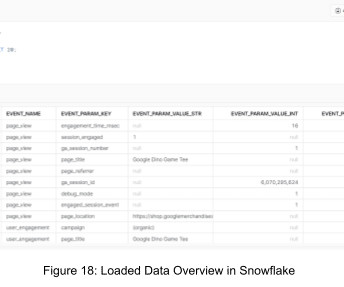
In this step-by-step guide, we will walk you through setting up a data ingestion pipeline using AzureData Factory (ADF), Google BigQuery, and the Snowflake Data Cloud. By the end of this tutorial, you’ll have a seamless pipeline that fetches and syncs your GA4 raw events data to Snowflake efficiently.
Cloud Computing, APIs, and Data Engineering NLP experts don’t go straight into conducting sentiment analysis on their personal laptops. Data Engineering Platforms Spark is still the leader for datapipelines but other platforms are gaining ground. Knowing some SQL is also essential.
One big issue that contributes to this resistance is that although Snowflake is a great cloud data warehousing platform, Microsoft has a data warehousing tool of its own called Synapse. In a perfect world, Microsoft would have clients push even more storage and compute to its Azure Synapse platform.
Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python. Databases and SQL : Managing and querying relational databases using SQL, as well as working with NoSQL databases like MongoDB.
Its PostgreSQL foundation ensures compatibility with most SQL clients. While it shares similarities with PostgreSQL, there are key differences that must be considered during application development. Strengths : High performance with SQL support, easy integration with other AWS services, and strong security features.
Cloud certifications, specifically in AWS and Microsoft Azure, were most strongly associated with salary increases. As we’ll see later, cloud certifications (specifically in AWS and Microsoft Azure) were the most popular and appeared to have the largest effect on salaries. Many respondents acquired certifications. What about Kafka?
Computer Science and Computer Engineering Similar to knowing statistics and math, a data scientist should know the fundamentals of computer science as well. While knowing Python, R, and SQL are expected, you’ll need to go beyond that. Big Data As datasets become larger and more complex, knowing how to work with them will be key.
SQL Server – The SQL Server connector, another widely-used database-type connector, provides similar functionality but is tailored for Microsoft’s SQL Server. The phData team achieved a major milestone by successfully setting up a secure end-to-end datapipeline for a substantial healthcare enterprise.
Key Skills for Data Science: A data scientist typically needs a blend of skills: Mathematics and Statistics: To understand the theoretical underpinnings of models. Programming: Often in languages like Python or R, using libraries for data manipulation, analysis, and machine learning.
Effective data governance enhances quality and security throughout the data lifecycle. What is Data Engineering? Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. They are crucial in ensuring data is readily available for analysis and reporting.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Visualization: Matplotlib, Seaborn, Tableau, etc.
The software you might use OAuth with includes: Tableau Power BI Sigma Computing If so, you will need an OAuth provider like Okta, Microsoft Azure AD, Ping Identity PingFederate, or a Custom OAuth 2.0 When to use SCIM vs phData's Provision Tool SCIM manages users and groups with Azure Active Directory or Okta. authorization server.
We had bigger sessions on getting started with machine learning or SQL, up to advanced topics in NLP, and of course, plenty related to large language models and generative AI. You can see our photos from the event here , and be sure to follow our YouTube for virtual highlights from the conference as well.
Snowpark, offered by the Snowflake AI Data Cloud , consists of libraries and runtimes that enable secure deployment and processing of non-SQL code, such as Python, Java, and Scala. Developers can seamlessly build datapipelines, ML models, and data applications with User-Defined Functions and Stored Procedures.
Microsoft Azure ML Platform The Azure Machine Learning platform provides a collaborative workspace that supports various programming languages and frameworks. It could help you detect and prevent datapipeline failures, data drift, and anomalies. Flyte Flyte is a platform for orchestrating ML pipelines at scale.
IBM Infosphere DataStage IBM Infosphere DataStage is an enterprise-level ETL tool that enables users to design, develop, and run datapipelines. Key Features: Graphical Framework: Allows users to design datapipelines with ease using a graphical user interface. Read More: Advanced SQL Tips and Tricks for Data Analysts.
It does not support the ‘dvc repro’ command to reproduce its datapipeline. DVC Released in 2017, Data Version Control ( DVC for short) is an open-source tool created by iterative. Dolt Created in 2019, Dolt is an open-source tool for managing SQL databases that uses version control similar to Git.
Best practices are a pivotal part of any software development, and data engineering is no exception. This ensures the datapipelines we create are robust, durable, and secure, providing the desired data to the organization effectively and consistently.
This individual is responsible for building and maintaining the infrastructure that stores and processes data; the kinds of data can be diverse, but most commonly it will be structured and unstructured data. They’ll also work with software engineers to ensure that the data infrastructure is scalable and reliable.
If using a network policy with Snowflake, be sure to add Fivetran’s IP address list , which will ensure AzureData Factory (ADF) AzureData Factory is a fully managed, serverless data integration service built by Microsoft. Source data formats can only be Parquer, JSON, or Delimited Text (CSV, TSV, etc.).
The shared-nothing architecture ensures that users don’t have to worry about distributing data across multiple cluster nodes. Snowflake hides user data objects and makes them accessible only through SQL queries through the compute layer. This includes tasks such as data cleansing, enrichment, and aggregation.
Integration : Can it connect with existing systems like AWS, Azure, or Google Cloud? It supports complex data transformations and offers advanced features like data quality management and metadata management. PowerCenter is particularly favored by large organizations with extensive data integration needs.
Generative AI can be used to automate the data modeling process by generating entity-relationship diagrams or other types of data models and assist in UI design process by generating wireframes or high-fidelity mockups. There is a VSCode Extension that enables its integration into traditional development pipelines.
Dolt LakeFS Delta Lake Pachyderm Git-like versioning Database tool Data lake Datapipelines Experiment tracking Integration with cloud platforms Integrations with ML tools Examples of data version control tools in ML DVC Data Version Control DVC is a version control system for data and machine learning teams.
The platform enables quick, flexible, and convenient options for storing, processing, and analyzing data. The solution was built on top of Amazon Web Services and is now available on Google Cloud and Microsoft Azure. Data warehousing is a vital constituent of any business intelligence operation. What does Snowflake do?
With Snowflake’s acquisition of Streamlit in 2022, Streamlit applications are now able to be hosted within your Snowflake environment, eliminating the need for extensive knowledge of Docker, Kubernetes, cloud platforms like AWS, GCP, or Azure, authentication and authorization patterns, etc.,
Kafka helps simplify the communication between customers and businesses, using its datapipeline to accurately record events and keep records of orders and cancellations—alerting all relevant parties in real-time. Developing with Kafka has many advantages over other platforms, here are a few of its most popular benefits.
Automation Automation plays a pivotal role in streamlining ETL processes, reducing the need for manual intervention, and ensuring consistent data availability. By automating key tasks, organisations can enhance efficiency and accuracy, ultimately improving the quality of their datapipelines.
Here’s the structured equivalent of this same data in tabular form: With structured data, you can use query languages like SQL to extract and interpret information. In contrast, such traditional query languages struggle to interpret unstructured data. This text has a lot of information, but it is not structured.
Microsoft Azure ML Provided by Microsoft , Azure Machine Learning (ML) is a cloud-based machine learning platform that enables data scientists and developers to build, train, and deploy machine learning models at scale. compute instances, storage) used to run Airflow and store workflow data.
Computer Science and Computer Engineering Similar to knowing statistics and math, a data scientist should know the fundamentals of computer science as well. While knowing Python, R, and SQL is expected, youll need to go beyond that. Employers arent just looking for people who can program.
This two-part series will explore how data discovery, fragmented data governance , ongoing data drift, and the need for ML explainability can all be overcome with a data catalog for accurate data and metadata record keeping. The Cloud Data Migration Challenge. Datapipeline orchestration.
Support for Numerous Data Sources: Fivetran supports over 200 data sources, including popular databases, applications, and cloud platforms like Salesforce, Google Analytics, SQL Server, Snowflake, and many more. Additionally, unsupported data sources can be integrated using Fivetran’s cloud function connectors.
I have worked with customers where R and SQL were the first-class languages of their data science community. You don’t need a bigger boat : The repository curated by Jacopo Tagliabue shows how several (mostly open-source) tools can be effectively combined together to run datapipelines at scale with very small teams.
However, if the tool supposes an option where we can write our custom programming code to implement features that cannot be achieved using the drag-and-drop components, it broadens the horizon of what we can do with our datapipelines. JV_STAGING_TBL} Here is what the outline of the pipeline looks like.
Datapipeline orchestration tools are designed to automate and manage the execution of datapipelines. These tools help streamline and schedule data movement and processing tasks, ensuring efficient and reliable data flow. What are Orchestration Tools?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content