This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Drag and drop tools have revolutionized the way we approach machine learning (ML) workflows. Gone are the days of manually coding every step of the process – now, with drag-and-drop interfaces, streamlining your ML pipeline has become more accessible and efficient than ever before. H2O.ai H2O.ai
In these scenarios, as you start to embrace generative AI, large language models (LLMs) and machine learning (ML) technologies as a core part of your business, you may be looking for options to take advantage of AWS AI and ML capabilities outside of AWS in a multicloud environment.
Microsoft Azure Machine Learning Microsoft Azure Machine Learning is a cloud-based platform that can be used for a variety of data analysis tasks. It is a powerful tool that can be used to automate many of the tasks involved in data analysis, and it can also help businesses to discover new insights from their data.
Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machine learning (ML), retail, and data and analytics. You can import data from multiple data sources, such as Amazon Simple Storage Service (Amazon S3), Amazon Athena , Amazon Redshift , Amazon EMR , and Snowflake.
Image generated by Gemini Spark is an open-source distributed computing framework for high-speed data processing. It is widely supported by platforms like GCP and Azure, as well as Databricks, which was founded by the creators of Spark. This practice vastly enhances the speed of my datapreparation for machine learning projects.
Instead, businesses tend to rely on advanced tools and strategies—namely artificial intelligence for IT operations (AIOps) and machine learning operations (MLOps)—to turn vast quantities of data into actionable insights that can improve IT decision-making and ultimately, the bottom line.
And eCommerce companies have a ton of use cases where ML can help. The problem is, with more ML models and systems in production, you need to set up more infrastructure to reliably manage everything. And because of that, many companies decide to centralize this effort in an internal ML platform. But how to build it?
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
80% of the time goes in datapreparation ……blah blah…. In short, the whole datapreparation workflow is a pain, with different parts managed or owned by different teams or people distributed across different geographies depending upon the company size and data compliances required. What is the problem statement?
This guarantees businesses can fully utilize deep learning in their AI and ML initiatives. You can make more informed judgments about your AI and ML initiatives if you know these platforms' features, applications, and use cases. Performance and Scalability Consider the platform's training speed and inference efficiency.
Data science teams currently struggle with managing multiple experiments and models and need an efficient way to store, retrieve, and utilize details like model versions, hyperparameters, and performance metrics. ML model versioning: where are we at? The short answer is we are in the middle of a data revolution.
Given they’re built on deep learning models, LLMs require extraordinary amounts of data. Regardless of where this data came from, managing it can be difficult. MLOps is also ideal for data versioning and tracking, so the data scientists can keep track of different iterations of the data used for training and testing LLMs.
A traditional machine learning (ML) pipeline is a collection of various stages that include data collection, datapreparation, model training and evaluation, hyperparameter tuning (if needed), model deployment and scaling, monitoring, security and compliance, and CI/CD. What is MLOps?
Generative AI , AI, and machine learning (ML) are playing a vital role for capital markets firms to speed up revenue generation, deliver new products, mitigate risk, and innovate on behalf of their customers. About SageMaker JumpStart Amazon SageMaker JumpStart is an ML hub that can help you accelerate your ML journey.
Understanding Machine Learning algorithms and effective data handling are also critical for success in the field. Introduction Machine Learning ( ML ) is revolutionising industries, from healthcare and finance to retail and manufacturing. Fundamental Programming Skills Strong programming skills are essential for success in ML.
Dataflows represent a cloud-based technology designed for datapreparation and transformation purposes. Dataflows have different connectors to retrieve data, including databases, Excel files, APIs, and other similar sources, along with data manipulations that are performed using Online Power Query Editor.
Note : Now write some articles or blogs on the things you have learned because this thing will help you to develop soft skills as well if you want to publish some research paper on AI/ML so this writing habit will help you there for sure. It provides end-to-end pipeline components for building scalable and reliable ML production systems.
Artificial intelligence platforms enable individuals to create, evaluate, implement and update machine learning (ML) and deep learning models in a more scalable way. AI platform tools enable knowledge workers to analyze data, formulate predictions and execute tasks with greater speed and precision than they can manually.
BPCS’s deep understanding of Databricks can help organizations of all sizes get the most out of the platform, with services spanning data migration, engineering, science, ML, and cloud optimization. HPCC is a high-performance computing platform that helps organizations process and analyze large amounts of data.
Here are a few of the key concepts that you should know: Machine Learning (ML) This is a type of AI that allows computers to learn without being explicitly programmed. Machine Learning algorithms are trained on large amounts of data, and they can then use that data to make predictions or decisions about new data.
In this article, we will explore the essential steps involved in training LLMs, including datapreparation, model selection, hyperparameter tuning, and fine-tuning. We will also discuss best practices for training LLMs, such as using transfer learning, data augmentation, and ensembling methods.
Table of Contents Introduction to PyCaret Benefits of PyCaret Installation and Setup DataPreparation Model Training and Selection Hyperparameter Tuning Model Evaluation and Analysis Model Deployment and MLOps Working with Time Series Data Conclusion 1. or higher and a stable internet connection for the installation process.
Tools like Apache NiFi, Talend, and Informatica provide user-friendly interfaces for designing workflows, integrating diverse data sources, and executing ETL processes efficiently. Choosing the right tool based on the organisation’s specific needs, such as data volume and complexity, is vital for optimising ETL efficiency.
Example output of Spectrogram Build Dataset and Data loader Data loaders help modularize our notebook by separating the datapreparation step and the model training step. Sample Data By using image_location, I am able to store images on disk as opposed to loading all the images in memory.
Data Management Tools These platforms often provide robust data management features that assist in datapreparation, cleaning, and augmentation, which are crucial for training effective AI models. Organisations can adjust their usage based on demand without significant infrastructure investments.
Nevertheless, many data scientists will agree that they can be really valuable – if used well. And that’s what we’re going to focus on in this article, which is the second in my series on Software Patterns for Data Science & ML Engineering. in a pandas DataFrame) but in the company’s data warehouse (e.g.,
Open Source ML/DL Platforms: Pytorch, Tensorflow, and scikit-learn Hiring managers continue to favor the most popular open-source machine/deep learning platforms including Pytorch, Tensorflow, and scikit-learn. It’s a pre-trained model capable of various tasks like text classification, question answering, and sentiment analysis.
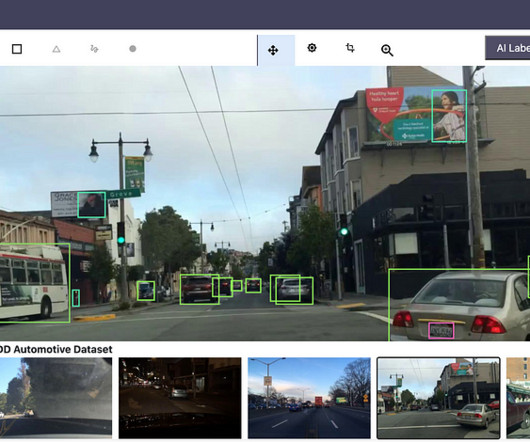
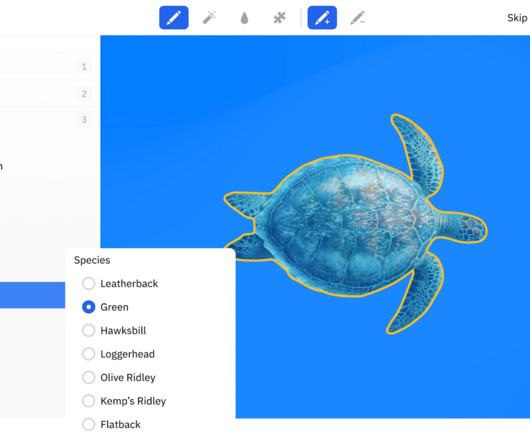
Image labeling and annotation are the foundational steps in accurately labeling the image data and developing machine learning (ML) models for the computer vision task. require image annotation so that ML models can interpret the images at a granular level and produce high-quality predictions in real-world applications.
These activities cover disparate fields such as basic data processing, analytics, and machine learning (ML). ML is often associated with PBAs, so we start this post with an illustrative figure. The ML paradigm is learning followed by inference. The union of advances in hardware and ML has led us to the current day.
ML opens up new opportunities for computers to solve tasks previously performed by humans and trains the computer system to make accurate predictions when inputting data. Top ML Companies. Veda technologies enable faster data processing, task automation, and organization of patient information. Indium Software.
Data Management Costs Data Collection : Involves sourcing diverse datasets, including multilingual and domain-specific corpora, from various digital sources, essential for developing a robust LLM. You can automatically manage and monitor your clusters using AWS, GCD, or Azure.
This explosive growth is driven by the increasing volume of data generated daily, with estimates suggesting that by 2025, there will be around 181 zettabytes of data created globally. Embrace Cloud Computing Cloud computing is integral to modern Data Science practices. Additionally, familiarity with cloud platforms (e.g.,
DataRobot now delivers both visual and code-centric datapreparation and data pipelines, along with automated machine learning that is composable, and can be driven by hosted notebooks or a graphical user experience. Modular and Extensible, Building on Existing Investments. Every organization is unique.
From customer service chatbots to data-driven decision-making , Watson enables businesses to extract insights from large-scale datasets with precision. Microsoft Azure AI Microsofts AI ecosystem offers a versatile suite of machine learning models, cognitive services, and automation tools.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content