This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Remote work quickly transitioned from a perk to a necessity, and datascience—already digital at heart—was poised for this change. For data scientists, this shift has opened up a global market of remote datascience jobs, with top employers now prioritizing skills that allow remote professionals to thrive.
This article was published as a part of the DataScience Blogathon. Introduction ETL is the process that extracts the data from various data sources, transforms the collected data, and loads that data into a common data repository. AzureData Factory […].
This article was published as a part of the DataScience Blogathon. Introduction Azuredata factory (ADF) is a cloud-based ETL (Extract, Transform, Load) tool and data integration service which allows you to create a data-driven workflow. In this article, I’ll show […].
Introduction In the era of Data storehouse, the need for assimilating the data from contrasting sources into a single consolidated database requires you to Extract the data from its parent source, Transform and amalgamate it, and thus, Load it into the consolidated database (ETL).
Continuous Integration and Continuous Delivery (CI/CD) for Data Pipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable data pipelines is paramount in datascience and data engineering. It supports a holistic data model, allowing for rapid prototyping of various models.
In the contemporary age of Big Data, Data Warehouse Systems and DataScience Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for Cloud Data Infrastructures?
Azure Machine Learning Datasets Learn all about Azure Datasets, why to use them, and how they help. Some news this week out of Microsoft and Amazon. Amazon Builders’ Library is now available in 16 Languages The Builder’s Library is a huge collection of resources about how Amazon builds and manages software.
Datascience bootcamps are intensive short-term educational programs designed to equip individuals with the skills needed to enter or advance in the field of datascience. They cover a wide range of topics, ranging from Python, R, and statistics to machine learning and data visualization.
DataScience Dojo is offering Meltano CLI for FREE on Azure Marketplace preconfigured with Meltano, a platform that provides flexibility and scalability. Not to worry as DataScience Dojo’s Meltano CLI instance fixes all of that. Meltano CLI stands out as a data engineering tool. Already feeling tired?
Die Bedeutung effizienter und zuverlässiger Datenpipelines in den Bereichen DataScience und Data Engineering ist enorm. Vielfältige Unterstützung: Kompatibel mit verschiedenen Datenbankmanagementsystemen wie MS SQL Server und Azure Synapse Analytics. Data Lakes: Unterstützt MS Azure Blob Storage.
One of them is Azure functions. In this article we’re going to check what is an Azure function and how we can employ it to create a basic extract, transform and load (ETL) pipeline with minimal code. Extract, transform and Load Before we begin, let’s shed some light on what an ETL pipeline essentially is.
Best tools and platforms for MLOPs – DataScience Dojo Google Cloud Platform Google Cloud Platform is a comprehensive offering of cloud computing services. Google Cloud Platform is a great option for businesses that need high-performance computing, such as datascience, AI, machine learning, and financial services.
Summary: Selecting the right ETL platform is vital for efficient data integration. Consider your business needs, compare features, and evaluate costs to enhance data accuracy and operational efficiency. Introduction In today’s data-driven world, businesses rely heavily on ETL platforms to streamline data integration processes.
Over the past few years DataScience has MIGRATED from individual computers to service cloud platforms. I just finished learning Azure’s service cloud platform using Coursera and the Microsoft Learning Path for DataScience.
Summary: This article explores the significance of ETLData in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
These professionals will work with their colleagues to ensure that data is accessible, with proper access. So let’s go through each step one by one, and help you build a roadmap toward becoming a data engineer. Identify your existing datascience strengths. Stay on top of data engineering trends.
Depending on the data strategy of one organization, one cost-effective approach to process mining could be to leverage cloud computing resources. Cloud platforms, such as Amazon Web Services (AWS), Microsoft Azure, or Google Cloud Platform (GCP), provide scalable and flexible infrastructure options.
But it’s interoperable on any cloud like Azure, AWS or GCP. was originally published in IBM DataScience in Practice on Medium, where people are continuing the conversation by highlighting and responding to this story. It focus on the monitoring and retraining policies that are keen for continious training.
The fusion of data in a central platform enables smooth analysis to optimize processes and increase business efficiency in the world of Industry 4.0 using methods from business intelligence , process mining and datascience. Cloud Data Platform for shopfloor management and data sources such like MES, ERP, PLM and machine data.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Big Data Technologies: Hadoop, Spark, etc. Read more to know.
For budding data scientists and data analysts, there are mountains of information about why you should learn R over Python and the other way around. Though both are great to learn, what gets left out of the conversation is a simple yet powerful programming language that everyone in the datascience world can agree on, SQL.
Then we have some other ETL processes to constantly land the past 5 years of data into the Datamarts. Then we have some other ETL processes to constantly land the past 5 years of data into the Datamarts. No-code/low-code experience using a diagram view in the data preparation layer similar to Dataflows.
As the sibling of datascience, data analytics is still a hot field that garners significant interest. Companies have plenty of data at their disposal and are looking for people who can make sense of it and make deductions quickly and efficiently. Cloud Services: Google Cloud Platform, AWS, Azure.
Ensure that data is clean, consistent, and up-to-date. Use ETL (Extract, Transform, Load) processes or data integration tools to streamline data ingestion. Scalable architecture: Design a scalable cloud architecture that can handle growing data volumes and user demands.
Reporting Tools Many reporting tools leverage ODBC to pull data from different databases, enabling users to generate comprehensive reports and insights from a unified interface. A notable feature of this driver is its compatibility with Azure SQL Database, enabling users to connect to cloud-based SQL databases effortlessly.
DataScience & AINews DeepSeek R1 Now Available on Azure AI Foundry and GitHub, Expanding AI Accessibility for Developers Microsofts Azure AI Foundry has added DeepSeek R1 to its growing portfolio of over 1,800 AI models at a time with AI shakeups. Register by Friday for 50%off!
Additionally, Data Engineers implement quality checks, monitor performance, and optimise systems to handle large volumes of data efficiently. Differences Between Data Engineering and DataScience While Data Engineering and DataScience are closely related, they focus on different aspects of data.
Its core components include: Lakehouse : Offers robust data storage and processing capabilities. Data Factory : Simplifies the creation of ETL pipelines to integrate data from diverse sources. It supports a broad range of data types and sources, ensuring robust data management across silos.
Users can quickly identify key trends, outliers , and data relationships, making it easier to make informed decisions based on comprehensive, AI-powered analysis. Power Query Power Query is another transformative AI tool that simplifies data extraction, transformation, and loading ( ETL ).
Jupyter notebooks have been one of the most controversial tools in the datascience community. Nevertheless, many data scientists will agree that they can be really valuable – if used well. I’ll show you best practices for using Jupyter Notebooks for exploratory data analysis. Aside neptune.ai
Data Warehousing and ETL Processes What is a data warehouse, and why is it important? A data warehouse is a centralised repository that consolidates data from various sources for reporting and analysis. It is essential to provide a unified data view and enable business intelligence and analytics.
Thankfully, there are tools available to help with metadata management, such as AWS Glue, AzureData Catalog, or Alation, that can automate much of the process. What are the Best Data Modeling Methodologies and Processes? Data lakes are meant to be flexible for new incoming data, whether structured or unstructured.
While Git can store code locally and also on a hosting service like GitHub, GitLab, and Bitbucket, DVC uses a remote repository to store all data and models. It supports most major cloud providers, such as AWS, GCP, and Azure. Data versioning with DVC is very simple and straightforward.
Typically, data is gathered over a predetermined period of time, and the batch is subsequently processed as a whole. When there is a delay in the availability of data for analysis and real-time processing is not necessary, this method works well.
Slow Response to New Information: Legacy data systems often lack the computation power necessary to run efficiently and can be cost-inefficient to scale. This typically results in long-running ETL pipelines that cause decisions to be made on stale or old data.
30% Off ODSC East, Fan-Favorite Speakers, Foundation Models for Times Series, and ETL Pipeline Orchestration The ODSC East 2025 Schedule isLIVE! Explore the must-attend sessions and cutting-edge tracks designed to equip AI practitioners, data scientists, and engineers with the latest advancements in AI and machine learning.
Learning these tools is crucial for building scalable data pipelines. offers DataScience courses covering these tools with a job guarantee for career growth. Introduction Imagine a world where data is a messy jungle, and we need smart tools to turn it into useful insights.
From customer service chatbots to data-driven decision-making , Watson enables businesses to extract insights from large-scale datasets with precision. Microsoft Azure AI Microsofts AI ecosystem offers a versatile suite of machine learning models, cognitive services, and automation tools.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































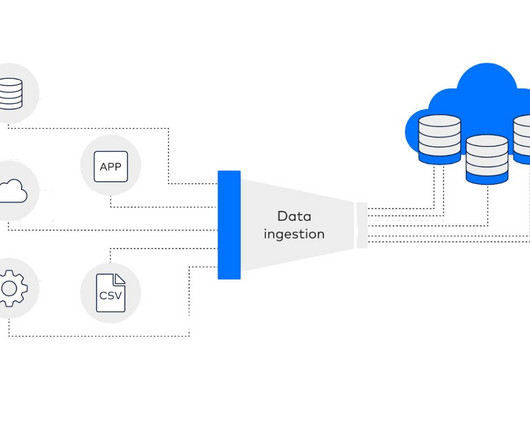










Let's personalize your content