This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Remote work quickly transitioned from a perk to a necessity, and datascience—already digital at heart—was poised for this change. For data scientists, this shift has opened up a global market of remote datascience jobs, with top employers now prioritizing skills that allow remote professionals to thrive.
The Biggest DataScience Blogathon is now live! Martin Uzochukwu Ugwu Analytics Vidhya is back with the largest data-sharing knowledge competition- The DataScience Blogathon. Knowledge is power. Sharing knowledge is the key to unlocking that power.”―
Hey, are you the datascience geek who spends hours coding, learning a new language, or just exploring new avenues of datascience? The post DataScience Blogathon 28th Edition appeared first on Analytics Vidhya. If all of these describe you, then this Blogathon announcement is for you!
Hello, fellow datascience enthusiasts, did you miss imparting your knowledge in the previous blogathon due to a time crunch? Well, it’s okay because we are back with another blogathon where you can share your wisdom on numerous datascience topics and connect with the community of fellow enthusiasts.
The Cloud DataScience world is keeping busy. Azure HDInsight now supports Apache analytics projects This announcement includes Spark, Hadoop, and Kafka. The frameworks in Azure will now have better security, performance, and monitoring. It is titled, Building Your First Model with Azure Machine Learning.
Datascience bootcamps are intensive short-term educational programs designed to equip individuals with the skills needed to enter or advance in the field of datascience. They cover a wide range of topics, ranging from Python, R, and statistics to machine learning and data visualization.
Summary: Business Analytics focuses on interpreting historical data for strategic decisions, while DataScience emphasizes predictive modeling and AI. Introduction In today’s data-driven world, businesses increasingly rely on analytics and insights to drive decisions and gain a competitive edge.
AI engineering is the discipline that combines the principles of datascience, software engineering, and machine learning to build and manage robust AI systems. R provides excellent packages for data visualization, statistical testing, and modeling that are integral for analyzing complex datasets in AI. What is AI Engineering?
Data Lakehouses werden auf Cloud-basierten Objektspeichern wie Amazon S3 , Google Cloud Storage oder Azure Blob Storage aufgebaut. In einem Data Lakehouse werden die Daten in ihrem Rohformat gespeichert, und Transformationen und Datenverarbeitung werden je nach Bedarf durchgeführt. So basieren z.
Summary: The future of DataScience is shaped by emerging trends such as advanced AI and Machine Learning, augmented analytics, and automated processes. As industries increasingly rely on data-driven insights, ethical considerations regarding data privacy and bias mitigation will become paramount.
While specific requirements may vary depending on the organization and the role, here are the key skills and educational background that are required for entry-level data scientists — Skillset Mathematical and Statistical Foundation Datascience heavily relies on mathematical and statistical concepts.
Familiarize yourself with essential data technologies: Data engineers often work with large, complex data sets, and it’s important to be familiar with technologies like Hadoop, Spark, and Hive that can help you process and analyze this data.
Summary This blog post demystifies datascience for business leaders. It explains key concepts, explores applications for business growth, and outlines steps to prepare your organization for data-driven success. DataScience Cheat Sheet for Business Leaders In today’s data-driven world, information is power.
They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. With expertise in programming languages like Python , Java , SQL, and knowledge of big data technologies like Hadoop and Spark, data engineers optimize pipelines for data scientists and analysts to access valuable insights efficiently.
From Sale Marketing Business 7 Powerful Python ML For DataScience And Machine Learning need to be use. The data-driven world will be in full swing. With the growth of big data and artificial intelligence, it is important that you have the right tools to help you achieve your goals. To perform data analysis 6.
The roles of data scientists and data analysts cannot be over-emphasized as they are needed to support decision-making. This article will serve as an ultimate guide to choosing between DataScience and Data Analytics. Before going into the main purpose of this article, what is data?
It is typically a single store of all enterprise data, including raw copies of source system data and transformed data used for tasks such as reporting, visualization, advanced analytics, and machine learning. Data processing happens in batch mode with the data stored at rest and can take minutes or even hours.
Big data is changing the future of almost every industry. The market for big data is expected to reach $23.5 Datascience is an increasingly attractive career path for many people. If you want to become a data scientist, then you should start by looking at the career options available. billion by 2025.
Cloud certifications, specifically in AWS and Microsoft Azure, were most strongly associated with salary increases. As we’ll see later, cloud certifications (specifically in AWS and Microsoft Azure) were the most popular and appeared to have the largest effect on salaries. Many respondents acquired certifications. Salaries by Gender.
Since data is left in its raw form within the data lake, it’s easier for data teams to experiment with models and analysis techniques with greater flexibility. So let’s take a look at a few of the leading industry examples of data lakes. Snowflake Snowflake is a cross-cloud platform that looks to break down data silos.
Additionally, Data Engineers implement quality checks, monitor performance, and optimise systems to handle large volumes of data efficiently. Differences Between Data Engineering and DataScience While Data Engineering and DataScience are closely related, they focus on different aspects of data.
The following points illustrates some of the main reasons why data versioning is crucial to the success of any datascience and machine learning project: Storage space One of the reasons of versioning data is to be able to keep track of multiple versions of the same data which obviously need to be stored as well.
With courses that cover areas from Microsoft’s Azure platform to Hadoop, EDX has a course for almost every big data specialty. Then there are other options such as Queen Mary University of London’s MSc Big DataScience which is held in partnership with IBM.
Many announcements at Strata centered on product integrations, with vendors closing the loop and turning tools into solutions, most notably: A Paxata-HDInsight solution demo, where Paxata showcased the general availability of its Adaptive Information Platform for Microsoft Azure. DataRobot Data Prep. free trial.
This blog will delve into ETL Tools, exploring the top contenders and their roles in modern data integration. Let’s unlock the power of ETL Tools for seamless data handling. Also Read: Top 10 DataScience tools for 2024. It is a process for moving and managing data from various sources to a central data warehouse.
The datascience job market is rapidly evolving, reflecting shifts in technology and business needs. Heres what we noticed from analyzing this data, highlighting whats remained the same over the years, and what additions help make the modern data scientist in2025. Joking aside, this does infer particular skills.
Key Skills Experience with cloud platforms (AWS, Azure). They ensure that data is accessible for analysis by data scientists and analysts. Experience with big data technologies (e.g., Data Management and Processing Develop skills in data cleaning, organisation, and preparation.
Key Takeaways Big Data originates from diverse sources, including IoT and social media. Data lakes and cloud storage provide scalable solutions for large datasets. Processing frameworks like Hadoop enable efficient data analysis across clusters. Data Lakes allows for flexibility in handling different data types.
Using appropriate metrics like the F1 score also ensures a more balanced model performance evaluation, especially for imbalanced data. Model Deployment and Scalability Deploying Machine Learning models to production environments is crucial in applying DataScience insights to real-world problems.
Cloud Computing provides scalable infrastructure for data storage, processing, and management. Both technologies complement each other by enabling real-time analytics and efficient data handling. Cloud platforms like AWS and Azure support Big Data tools, reducing costs and improving scalability.
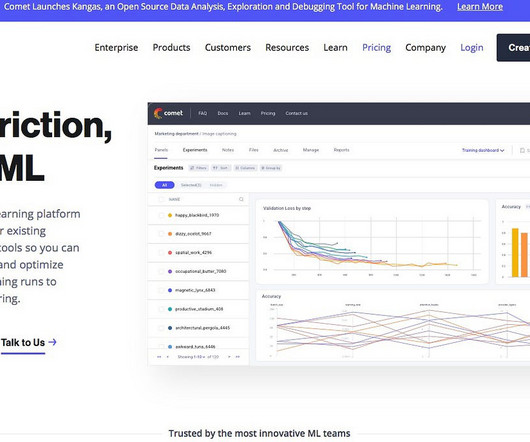
Comet also integrates with popular data storage and processing tools like Amazon S3, Google Cloud Storage, and Hadoop. This allows users to easily access their data and store their experiment results, making it easy to collaborate and share their work with others. Try Comet for free at comet.com.
While Git can store code locally and also on a hosting service like GitHub, GitLab, and Bitbucket, DVC uses a remote repository to store all data and models. It supports most major cloud providers, such as AWS, GCP, and Azure. Data versioning with DVC is very simple and straightforward.
Learning these tools is crucial for building scalable data pipelines. offers DataScience courses covering these tools with a job guarantee for career growth. Introduction Imagine a world where data is a messy jungle, and we need smart tools to turn it into useful insights.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content