This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
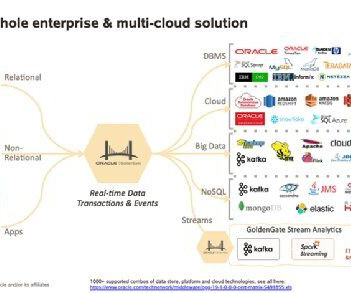
With this full-fledged solution, you don’t have to spend all your time and effort combining different services or duplicating data. OneLake, being built on AzureData Lake Storage (ADLS), supports various data formats, including Delta, Parquet, CSV, and JSON.
By automating the integration of all Fabric workloads into OneLake, Microsoft eliminates the need for developers, analysts, and business users to create their own data silos. This approach not only improves performance by eliminating the need for separate datawarehouses but also results in substantial cost savings for customers.
Summary: This blog provides a comprehensive roadmap for aspiring AzureData Scientists, outlining the essential skills, certifications, and steps to build a successful career in Data Science using Microsoft Azure. What is Azure?
The extraction of raw data, transforming to a suitable format for business needs, and loading into a datawarehouse. Data transformation. This process helps to transform raw data into clean data that can be analysed and aggregated. Data analytics and visualisation. Microsoft Azure.
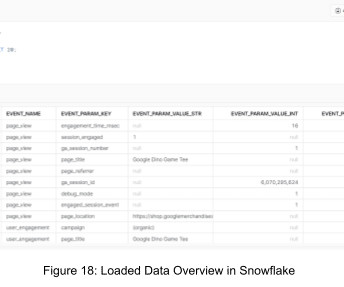
Google Analytics 4 (GA4) is a powerful tool for collecting and analyzing website and app data that many businesses rely heavily on to make informed business decisions. However, there might be instances where you need to migrate the raw eventdata from GA4 to Snowflake for more in-depth analysis and business intelligence purposes.
Diagnostic analytics: Diagnostic analytics goes a step further by analyzing historical data to determine why certain events occurred. By understanding the “why” behind past events, organizations can make informed decisions to prevent or replicate them. Ensure that data is clean, consistent, and up-to-date.
Data integration is essentially the Extract and Load portion of the Extract, Load, and Transform (ELT) process. Data ingestion involves connecting your data sources, including databases, flat files, streaming data, etc, to your datawarehouse. Snowflake provides native ways for data ingestion.
Recognizing these specific needs, Fivetran has developed a range of connectors, including dedicated applications, databases, files, and events, which can accommodate the diverse formats used by healthcare systems. Addressing these needs may pose challenges that lead to the implementation of custom solutions rather than a uniform approach.
Note: Recommended to only edit the configuration marked as TODO gg.target=snowflake #The Snowflake Event Handler #TODO: Edit JDBC ConnectionUrl gg.eventhandler.snowflake.connectionURL=jdbc:snowflake://.snowflakecomputing.com/?warehouse= The S3 Event Handler #TODO: Edit the AWS region #gg.eventhandler.s3.region= snowflakecomputing.com/?warehouse=
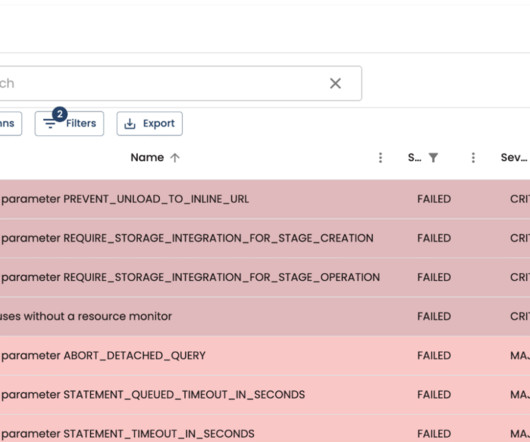
The ultimate need for vast storage spaces manifests in datawarehouses: specialized systems that aggregate data coming from numerous sources for centralized management and consistency. In this article, you’ll discover what a Snowflake datawarehouse is, its pros and cons, and how to employ it efficiently.
Training Your PyTorch Model Using Components and Pipelines in Azure ML In this post, we’ll explore how you can take your PyTorch model training to the next level, using Azure ML. This is where the BigQuery datawarehouse comes into play.
Db2 can run on Red Hat OpenShift and Kubernetes environments, ROSA & EKS on AWS, and ARO & AKS on Azure deployments. Customers can also choose to run IBM Db2 database and IBM Db2 Warehouse as a fully managed service. Many consider a NoSQL database essential for high data ingestion rates.
Role of Data Engineers in the Data Ecosystem Data Engineers play a crucial role in the data ecosystem by bridging the gap between raw data and actionable insights. They are responsible for building and maintaining data architectures, which include databases, datawarehouses, and data lakes.
Google BigQuery When it comes to cloud datawarehouses, Snowflake, Amazon Redshift, and Google BigQuery are often at the forefront of discussions. Each platform offers unique features and benefits, making it vital for data engineers to understand their differences. Interested in attending an ODSC event?
Research and new offerings in AI fuel the field of data science. At ODSC events, we love to highlight our partners’ latest developments, products, services, and research, so that you can see how organizations from around the world are changing the landscape of AI. The event is only a few weeks away, so don’t delay!
Kaggle Grandmaster Jiwei Liu and NVIDIA experts will answer all your questions about the upcoming event. Syncari : Tailored for data teams, Syncari integrates and unifies data across systems, enhancing real-time AI-driven decision-making.
They’ll also work with software engineers to ensure that the data infrastructure is scalable and reliable. These professionals will work with their colleagues to ensure that data is accessible, with proper access. The reason this is an important skill is that ETL is a critical process for data warehousing and business intelligence.
IBM Security® Guardium® Data Protection empowers security teams to safeguard sensitive data through discovery and classification, data activity monitoring, vulnerability assessments and advanced threat detection.
Taking it one step further, if you don’t want your data traversing the public internet, you can implement one of the private connections available from the cloud provider your Snowflake account is created on, i.e., Azure Private Link, AWS Privatelink, or Google Cloud Service Private Connect.
This two-part series will explore how data discovery, fragmented data governance , ongoing data drift, and the need for ML explainability can all be overcome with a data catalog for accurate data and metadata record keeping. The Cloud Data Migration Challenge. Automatic sampling to test transformation.
Co-location data centers: These are data centers that are owned and operated by third-party providers and are used to house the IT equipment of multiple organizations. Edge data centers: These are data centers that are located closer to the edge of the network, where data is generated and consumed, rather than in central locations.
Delphi Prerequisites and Compatibility: It requires a dbt Cloud Team or Enterprise account and supports popular datawarehouses like Snowflake, BigQuery, Databricks, and Redshift. These jobs can be triggered via schedule or events, ensuring your data assets are always up-to-date.
Schon damals in Ansätzen, aber spätestens heute gilt es zu recht als Best Practise, die Datenanbindung an ein DataWarehouse zu machen und in diesem die Daten für die Reports aufzubereiten. Ein DataWarehouse ist eine oder eine Menge von Datenbanken. Was gerade zum Trend wird, ist der Aufbau eines Data Lakehouses.
Dabei darf gerne in Erinnerung gerufen werden, dass Process Mining im Kern eine Graphenanalyse ist, die ein Event Log in Graphen umwandelt, Aktivitäten (Events) stellen dabei die Knoten und die Prozesszeiten die Kanten dar, zumindest ist das grundsätzlich so. Es handelt sich dabei also um eine Analysemethodik und nicht um ein Tool.
Understanding Matillion and Snowflake, the Python Component, and Why it is Used Matillion is a SaaS-based data integration platform that can be hosted in AWS, Azure, or GCP and supports multiple cloud datawarehouses. If not, it will retry after a certain duration (E.g., 30 minutes).
Methods that allow our customer data models to be as dynamic and flexible as the customers they represent. In this guide, we will explore concepts like transitional modeling for customer profiles, the power of event logs for customer behavior, persistent staging for raw customer data, real-time customer data capture, and much more.
Statistics : A survey by Databricks revealed that 80% of Spark users reported improved performance in their data processing tasks compared to traditional systems. Google Cloud BigQuery Google Cloud BigQuery is a fully-managed enterprise datawarehouse that enables super-fast SQL queries using the processing power of Googles infrastructure.
Apache Kafka Apache Kafka is a distributed event streaming platform used for real-time data processing. It helps data engineers collect, store, and process streams of records in a fault-tolerant way, making it crucial for building reliable data pipelines.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content