This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Database Analyst Description Database Analysts focus on managing, analyzing, and optimizing data to support decision-making processes within an organization. They work closely with database administrators to ensure data integrity, develop reporting tools, and conduct thorough analyses to inform business strategies.
Extract : In this step, data is extracted from a vast array of sources present in different formats such as Flat Files, Hadoop Files, XML, JSON, etc. Here are few best Open-Source ETL tools on the market: Hadoop : Hadoop distinguishes itself as a general-purpose Distributed Computing platform.
Here comes the role of Hive in Hadoop. Hive is a powerful data warehousing infrastructure that provides an interface for querying and analyzing large datasets stored in Hadoop. In this blog, we will explore the key aspects of Hive Hadoop. What is Hadoop ? Hive is a data warehousing infrastructure built on top of Hadoop.
Accordingly, one of the most demanding roles is that of Azure Data Engineer Jobs that you might be interested in. The following blog will help you know about the Azure Data Engineering Job Description, salary, and certification course. How to Become an Azure Data Engineer?
Learn SQL: As a data engineer, you will be working with large amounts of data, and SQL is the most commonly used language for interacting with databases. Understanding how to write efficient and effective SQL queries is essential.
Data Lakehouses werden auf Cloud-basierten Objektspeichern wie Amazon S3 , Google Cloud Storage oder Azure Blob Storage aufgebaut. Spark ist direkt auf mehreren Cloud-Plattformen verfügbar, darunter AWS, Azure und Google Cloud Platform.Apacke Spark ist jedoch mehr als nur ein Tool, es ist die Grundbasis für die meisten anderen Tools.
Cost Efficiency and Scalability Open Table Formats are designed to work with cloud storage solutions like Amazon S3, Google Cloud Storage, and Azure Blob Storage, enabling cost-effective and scalable storage solutions. Amazon S3, Azure Data Lake, or Google Cloud Storage).
Unlike the old days where data was readily stored and available from a single database and data scientists only needed to learn a few programming languages, data has grown with technology. Understand the Databases. As a data engineer, you will be primarily working on databases. Forging a Career Path in the Field of Data Science.
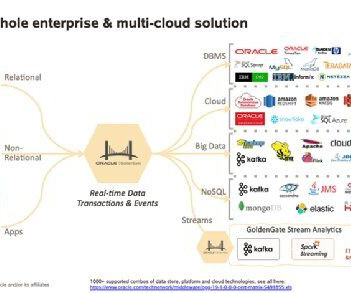
The task of keeping multiple databases in sync so that data is accurate, up-to-date, and highly available is every data consumer’s biggest challenge. Oracle is one of the largest IT companies whose flagship product, Oracle Database, is a relational database management system. What is Oracle? What is Oracle GoldenGate?
Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. Databases and SQL : Managing and querying relational databases using SQL, as well as working with NoSQL databases like MongoDB.
Hadoop, Snowflake, Databricks and other products have rapidly gained adoption. We will also address some of the key distinctions between platforms like Hadoop and Snowflake, which have emerged as valuable tools in the quest to process and analyze ever larger volumes of structured, semi-structured, and unstructured data.
Commonly used technologies for data storage are the Hadoop Distributed File System (HDFS), Amazon S3, Google Cloud Storage (GCS), or Azure Blob Storage, as well as tools like Apache Hive, Apache Spark, and TensorFlow for data processing and analytics.
They are responsible for building and maintaining data architectures, which include databases, data warehouses, and data lakes. Data Modelling Data modelling is creating a visual representation of a system or database. Physical Models: These models specify how data will be physically stored in databases.
DVC lacks crucial relational database features, making it an unsuitable choice for those familiar with relational databases. Dolt Created in 2019, Dolt is an open-source tool for managing SQL databases that uses version control similar to Git. It versions tables instead of files and has a SQL query interface for those tables.
They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. With expertise in programming languages like Python , Java , SQL, and knowledge of big data technologies like Hadoop and Spark, data engineers optimize pipelines for data scientists and analysts to access valuable insights efficiently.
Processing frameworks like Hadoop enable efficient data analysis across clusters. This includes structured data (like databases), semi-structured data (like XML files), and unstructured data (like text documents and videos). Key Takeaways Big Data originates from diverse sources, including IoT and social media.
Processing frameworks like Hadoop enable efficient data analysis across clusters. This includes structured data (like databases), semi-structured data (like XML files), and unstructured data (like text documents and videos). Key Takeaways Big Data originates from diverse sources, including IoT and social media.
It involves retrieving data from various sources, such as databases, spreadsheets, or even cloud storage. The ETL tool must work with your current systems, support your existing databases and applications, and be able to connect to various data sources. It supports a wide range of databases and provides robust ETL capabilities.
Key Skills Experience with cloud platforms (AWS, Azure). Familiarity with SQL for database management. Strong understanding of database management systems (e.g., Hadoop , Apache Spark ) is beneficial for handling large datasets effectively. They ensure that AI systems are scalable and efficient.
Its popularity stems from its user-friendly interface and seamless integration with widely used Microsoft applications like Excel and Azure, making it highly accessible for organisations already using Microsoft products. Tableau supports many data sources, including cloud databases, SQL databases, and Big Data platforms.
Familiarity with Databases; SQL for structured data, and NOSQL for unstructured data. Experience with cloud platforms like; AWS, AZURE, etc. Knowledge of big data platforms like; Hadoop and Apache Spark. Knowledge of big data platforms like; Hadoop and Apache Spark. Basic programming knowledge in R or Python.
This is an architecture that’s well suited for the cloud since AWS S3 or Azure DLS2 can provide the requisite storage. data platforms and databases), all interacting with one another to provide greater value. A data fabric can consist of multiple data warehouses, data lakes, IoT/Edge devices and transactional databases.
Data can come from different sources, such as databases or directly from users, with additional sources, including platforms like GitHub, Notion, or S3 buckets. Vector Databases Vector databases help store unstructured data by storing the actual data and its vector representation. mp4,webm, etc.), and audio files (.wav,mp3,acc,
But, it is not rare that data engineers and database administrators process, control, and store terabytes of data in projects that are not related to machine learning. Data from different formats, databases, and sources are combined together for modeling. It supports most major cloud providers, such as AWS, GCP, and Azure.
Unlike structured data, unstructured data doesn’t fit neatly into predefined models or databases, making it harder to analyse using traditional methods. While sensor data is typically numerical and has a well-defined format, such as timestamps and data points, it only fits the standard tabular structure of databases.
databases, CSV files). Cloud platforms like AWS , Google Cloud Platform (GCP), and Microsoft Azure provide managed services for Machine Learning, offering tools for model training, storage, and inference at scale. Structured data refers to data organised in tables or spreadsheets (e.g.,
So, a better database architecture would be to maintain multiple tables where one of the tables maintains the past 3 months history with session-level details, whereas other tables may contain weekly aggregated click, ATC, and order data. One might want to utilize an off-the-shelf ML Ops Platform to maintain different versions of data.
Java is also widely used in big data technologies, supported by powerful Java-based tools like Apache Hadoop and Spark, which are essential for data processing in AI. Big Data Technologies With the growth of data-driven technologies, AI engineers must be proficient in big data platforms like Hadoop, Spark, and NoSQL databases.
Focus on Python and R for Data Analysis, along with SQL for database management. Gain Experience with Big Data Technologies With the rise of Big Data, familiarity with technologies like Hadoop and Spark is essential. AWS or Azure) will be increasingly important as more organisations migrate their operations online.
Understanding Data Structured Data: Organized data with a clear format, often found in databases or spreadsheets. SQL (Structured Query Language): Language for managing and querying relational databases. Hadoop/Spark: Frameworks for distributed storage and processing of big data.
Best Big Data Tools Popular tools such as Apache Hadoop, Apache Spark, Apache Kafka, and Apache Storm enable businesses to store, process, and analyse data efficiently. Key Features : Scalability : Hadoop can handle petabytes of data by adding more nodes to the cluster. Use Cases : Yahoo!
A data engineer creates and manages the pipelines that transfer data from different sources to databases or cloud storage. Data Storage : Keeping data safe in databases or cloud platforms. It allows them to retrieve, manipulate, and manage structured data in relational databases. What Does a Data Engineer Do?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content