This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Key Skills: Mastery in machine learning frameworks like PyTorch or TensorFlow is essential, along with a solid foundation in unsupervised learning methods. Stanford AI Lab recommends proficiency in deeplearning, especially if working in experimental or cutting-edge areas.
The Biggest Data Science Blogathon is now live! Knowledge is power. Sharing knowledge is the key to unlocking that power.”― Martin Uzochukwu Ugwu Analytics Vidhya is back with the largest data-sharing knowledge competition- The Data Science Blogathon.
Hey, are you the data science geek who spends hours coding, learning a new language, or just exploring new avenues of data science? If all of these describe you, then this Blogathon announcement is for you! Analytics Vidhya is back with its 28th Edition of blogathon, a place where you can share your knowledge about […].
Hello, fellow data science enthusiasts, did you miss imparting your knowledge in the previous blogathon due to a time crunch? Well, it’s okay because we are back with another blogathon where you can share your wisdom on numerous data science topics and connect with the community of fellow enthusiasts.
Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deeplearning. Tools and frameworks like Scikit-Learn, TensorFlow, and Keras are often covered.
Scikit-Learn: Scikit-Learn is a machine learning library that makes it easy to train and deploy machine learning models. It has a wide range of features, including data preprocessing, feature extraction, deeplearning training, and model evaluation. How Do I Use These Libraries?
Without linear algebra, understanding the mechanics of DeepLearning and optimisation would be nearly impossible. Neural Networks These models simulate the structure of the human brain, allowing them to learn complex patterns in large datasets. Neural networks are the foundation of DeepLearning techniques.
With expertise in programming languages like Python , Java , SQL, and knowledge of big data technologies like Hadoop and Spark, data engineers optimize pipelines for data scientists and analysts to access valuable insights efficiently. Machine Learning: Supervised and unsupervised learning techniques, deeplearning, etc.
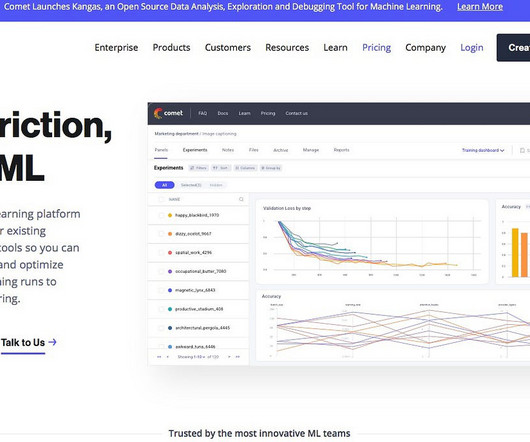
It automates the process of hyperparameter tuning, making it easy to find the best hyperparameters for a given machine learning problem. This is especially useful for deeplearning models, which can have many hyperparameters that need to be optimized. Using Comet saves time and reduces the risk of human error.
Machine Learning As machine learning is one of the most notable disciplines under data science, most employers are looking to build a team to work on ML fundamentals like algorithms, automation, and so on. DeepLearningDeeplearning is a cornerstone of modern AI, and its applications are expanding rapidly.
Popular data lake solutions include Amazon S3 , Azure Data Lake , and Hadoop. Apache Hadoop Apache Hadoop is an open-source framework that supports the distributed processing of large datasets across clusters of computers. Data Processing Tools These tools are essential for handling large volumes of unstructured data.
These vector databases store complex data by transforming the original unstructured data into numerical embeddings; this is enabled through deeplearning models. AI also plays an important role in this process because it uses deeplearning methods to create embeddings that find all the key features of the original data.
For example, predictive maintenance in manufacturing uses machine learning to anticipate equipment failures before they occur, reducing downtime and saving costs. DeepLearningDeeplearning is a subset of machine learning based on artificial neural networks, where the model learns to perform tasks directly from text, images, or sounds.
Machine Learning: Subset of AI that enables systems to learn from data without being explicitly programmed. Supervised Learning: Learning from labeled data to make predictions or decisions. Unsupervised Learning: Finding patterns or insights from unlabeled data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content