This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Overview Learn about the integration capabilities of Power BI with Azure Machine Learning (ML) Understand how to deploy machine learning models in a production. The post The Power of Azure ML and Power BI: Dataflows and Model Deployment appeared first on Analytics Vidhya.
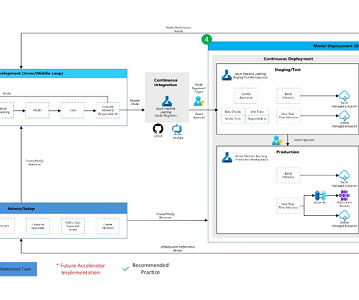
This resulted in a wide number of accelerators, code repositories, or even full-fledged products that were built using or on top of Azure Machine Learning (Azure ML). The Azure data platforms in this diagram are neither exhaustive nor prescriptive. Creation of Azure Machine Learning workspaces for the project.
It is widely supported by platforms like GCP and Azure, as well as Databricks, which was founded by the creators of Spark. This is the first one, where we look at some functions for data quality checks, which are the initial steps I take in EDA. Let’s get started. 🤠 🔗 All code and config are available on GitHub.
This includes skills in data cleaning, preprocessing, transformation, and exploratory data analysis (EDA). Check out this course to upskill on Apache Spark — [link] Cloud Computing technologies such as AWS, GCP, Azure will also be a plus. Familiarity with libraries like pandas, NumPy, and SQL for data handling is important.
For Data Analysis you can focus on such topics as Feature Engineering , Data Wrangling , and EDA which is also known as Exploratory Data Analysis. First learn the basics of Feature Engineering, and EDA then take some different-different data sheets (data frames) and apply all the techniques you have learned to date.
For example, when it comes to deploying projects on cloud platforms, different companies may utilize different providers like AWS, GCP, or Azure. Therefore, having proficiency in a specific cloud platform, such as Azure, does not mean you will exclusively work with that platform in the industry.
Exploratory Data Analysis (EDA) EDA is a crucial step where Data Scientists visually explore and analyze the data to identify patterns, trends, and potential correlations. Cloud Platforms: AWS, Azure, Google Cloud, etc. They clean and preprocess the data to remove inconsistencies and ensure its quality.
Exploratory Data Analysis (EDA) EDA is a crucial preliminary step in understanding the characteristics of the dataset. EDA guides subsequent preprocessing steps and informs the selection of appropriate AI algorithms based on data insights. Feature Engineering : Creating or transforming new features to enhance model performance.
To store Image data, Cloud storage like Amazon S3 and GCP buckets, Azure Blob Storage are some of the best options, whereas one might want to utilize Hadoop + Hive or BigQuery to store clickstream and other forms of text and tabular data. One might want to utilize an off-the-shelf ML Ops Platform to maintain different versions of data.
It is also essential to evaluate the quality of the dataset by conducting exploratory data analysis (EDA), which involves analyzing the dataset’s distribution, frequency, and diversity of text. It is therefore important to carefully plan and execute data preparation tasks to ensure the best possible performance of the machine learning model.
How to use the Codex models to work with code - Azure OpenAI Service Codex is the model powering Github Copilot. There is a VSCode Extension that enables its integration into traditional development pipelines. The StarCoder Chat provides a conversational experience about programming related topics.
Universities still mostly focus on things like EDA, data cleaning, and building/fine-tune models. AWS, Google Cloud, or Azure) is essential. Its less about just building models and more about how those models fit into scalable, business-critical systems usually in the cloud.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content