This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Microsoft Azure HDInsight(or Microsoft HDFS) is a cloud-based Hadoop Distributed File System version. HDInsight works seamlessly with the Hadoop ecosystem, which includes technologies like MapReduce, Hive, […] The post Top 6 Microsoft HDFS Interview Questions appeared first on Analytics Vidhya.
Programming Questions Data science roles typically require knowledge of Python, SQL, R, or Hadoop. Additionally, experience in cloud platforms like AWS, Google Cloud, and Azure is often required, as most remote data workflows operate on cloud infrastructure.
Azure HDInsight now supports Apache analytics projects This announcement includes Spark, Hadoop, and Kafka. The frameworks in Azure will now have better security, performance, and monitoring. The first course in the Mastering Azure Machine Learning sequence has been released. I might have to join in the future.
Extract : In this step, data is extracted from a vast array of sources present in different formats such as Flat Files, Hadoop Files, XML, JSON, etc. Here are few best Open-Source ETL tools on the market: Hadoop : Hadoop distinguishes itself as a general-purpose Distributed Computing platform.
Here comes the role of Hive in Hadoop. Hive is a powerful data warehousing infrastructure that provides an interface for querying and analyzing large datasets stored in Hadoop. In this blog, we will explore the key aspects of Hive Hadoop. What is Hadoop ? Hive is a data warehousing infrastructure built on top of Hadoop.
Accordingly, one of the most demanding roles is that of Azure Data Engineer Jobs that you might be interested in. The following blog will help you know about the Azure Data Engineering Job Description, salary, and certification course. How to Become an Azure Data Engineer?
Familiarize yourself with essential data technologies: Data engineers often work with large, complex data sets, and it’s important to be familiar with technologies like Hadoop, Spark, and Hive that can help you process and analyze this data.
Cloud certifications, specifically in AWS and Microsoft Azure, were most strongly associated with salary increases. As we’ll see later, cloud certifications (specifically in AWS and Microsoft Azure) were the most popular and appeared to have the largest effect on salaries. Many respondents acquired certifications. What about Kafka?
The Biggest Data Science Blogathon is now live! Knowledge is power. Sharing knowledge is the key to unlocking that power.”― Martin Uzochukwu Ugwu Analytics Vidhya is back with the largest data-sharing knowledge competition- The Data Science Blogathon.
Cost Efficiency and Scalability Open Table Formats are designed to work with cloud storage solutions like Amazon S3, Google Cloud Storage, and Azure Blob Storage, enabling cost-effective and scalable storage solutions. Amazon S3, Azure Data Lake, or Google Cloud Storage).
Java is also widely used in big data technologies, supported by powerful Java-based tools like Apache Hadoop and Spark, which are essential for data processing in AI. Big Data Technologies With the growth of data-driven technologies, AI engineers must be proficient in big data platforms like Hadoop, Spark, and NoSQL databases.
Hey, are you the data science geek who spends hours coding, learning a new language, or just exploring new avenues of data science? If all of these describe you, then this Blogathon announcement is for you! Analytics Vidhya is back with its 28th Edition of blogathon, a place where you can share your knowledge about […].
Hello, fellow data science enthusiasts, did you miss imparting your knowledge in the previous blogathon due to a time crunch? Well, it’s okay because we are back with another blogathon where you can share your wisdom on numerous data science topics and connect with the community of fellow enthusiasts.
Hadoop, Snowflake, Databricks and other products have rapidly gained adoption. We will also address some of the key distinctions between platforms like Hadoop and Snowflake, which have emerged as valuable tools in the quest to process and analyze ever larger volumes of structured, semi-structured, and unstructured data.
Big data platforms such as Apache Hadoop and Spark help handle massive datasets efficiently. They must also stay updated on tools such as TensorFlow, Hadoop, and cloud-based platforms like AWS or Azure. Programming languages like Python and R are commonly used for data manipulation, visualization, and statistical modeling.
Google’s Hadoop allowed for unlimited data storage on inexpensive servers, which we now call the Cloud. Searching for a topic on a search engine can provide us with a vast amount of information in seconds. Deighton studies how this evolution came to be. Innovations in the early 20th century changed how data could be used.
Commonly used technologies for data storage are the Hadoop Distributed File System (HDFS), Amazon S3, Google Cloud Storage (GCS), or Azure Blob Storage, as well as tools like Apache Hive, Apache Spark, and TensorFlow for data processing and analytics.
Microsoft’s Azure Data Lake The Azure Data Lake is considered to be a top-tier service in the data storage market. Amazon Web Services Similar to Azure, Amazon Simple Storage Service is an object storage service offering scalability, data availability, security, and performance.
Among these tools, Apache Hadoop, Apache Spark, and Apache Kafka stand out for their unique capabilities and widespread usage. Apache HadoopHadoop is a powerful framework that enables distributed storage and processing of large data sets across clusters of computers.
Many announcements at Strata centered on product integrations, with vendors closing the loop and turning tools into solutions, most notably: A Paxata-HDInsight solution demo, where Paxata showcased the general availability of its Adaptive Information Platform for Microsoft Azure. Alation and Paxata announced their product integration.
Spark outperforms old parallel systems such as Hadoop, as it is written using Scala and helps interface with other programming languages and other tools such as Dask. Popular cloud platforms include the Microsoft Azure, Google Cloud Platform, and Amazon Web Services. Data processing is often done in batches.
Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. Cloud Computing : Utilizing cloud services for data storage and processing, often covering platforms such as AWS, Azure, and Google Cloud.
With courses that cover areas from Microsoft’s Azure platform to Hadoop, EDX has a course for almost every big data specialty. They work with some of the industry’s biggest players, like Microsoft, to help produce detailed and engaging courses that can be taken from anywhere.
Key Skills Experience with cloud platforms (AWS, Azure). Hadoop , Apache Spark ) is beneficial for handling large datasets effectively. Cloud Computing Skills Familiarize yourself with cloud platforms like AWS , Google Cloud , or Microsoft Azure to manage infrastructure and deploy AI models efficiently.
Its popularity stems from its user-friendly interface and seamless integration with widely used Microsoft applications like Excel and Azure, making it highly accessible for organisations already using Microsoft products. Tableau supports integrations with third-party tools, including Salesforce, Hadoop, and Google Analytics.
Key Features Out-of-the-Box Connectors: Includes connectors for databases like Hadoop, CRM systems, XML, JSON, and more. HadoopHadoop is an open-source framework designed for processing and storing big data across clusters of computer servers. Read Further: Azure Data Engineer Jobs. How to drop a database in SQL server?
With expertise in programming languages like Python , Java , SQL, and knowledge of big data technologies like Hadoop and Spark, data engineers optimize pipelines for data scientists and analysts to access valuable insights efficiently. Big Data Technologies: Hadoop, Spark, etc. Big Data Processing: Apache Hadoop, Apache Spark, etc.
Processing frameworks like Hadoop enable efficient data analysis across clusters. Cloud Storage: Services like Amazon S3, Google Cloud Storage, and Microsoft Azure Blob Storage provide scalable storage solutions that can accommodate massive datasets with ease. Data lakes and cloud storage provide scalable solutions for large datasets.
Processing frameworks like Hadoop enable efficient data analysis across clusters. Cloud Storage: Services like Amazon S3, Google Cloud Storage, and Microsoft Azure Blob Storage provide scalable storage solutions that can accommodate massive datasets with ease. Data lakes and cloud storage provide scalable solutions for large datasets.
Check out this course to build your skillset in Seaborn — [link] Big Data Technologies Familiarity with big data technologies like Apache Hadoop, Apache Spark, or distributed computing frameworks is becoming increasingly important as the volume and complexity of data continue to grow.
Spark: Spark is a popular platform used for big data processing in the Hadoop ecosystem. Using a cloud provider such as Google Cloud Platform, Amazon AWS, Azure Cloud, or IBM SoftLayer 2. Deploying a machine learning library in the cloud can be difficult.
Experience with cloud platforms like; AWS, AZURE, etc. Knowledge of big data platforms like; Hadoop and Apache Spark. Experience with machine learning frameworks for supervised and unsupervised learning. Experience with visualization tools like; Tableau and Power BI.
LakeFS Most big data storage solutions such as Azure, Google cloud storage, and Amazon S3 have good performance, cost-effective, and have good connectivity with other tooling. Such a server is not provided by every Git hosting service and in some cases will require either setting it up or switching to a different Git provider.
Cloud platforms like AWS , Google Cloud Platform (GCP), and Microsoft Azure provide managed services for Machine Learning, offering tools for model training, storage, and inference at scale. Big Data Tools Integration Big data tools like Apache Spark and Hadoop are vital for managing and processing massive datasets.
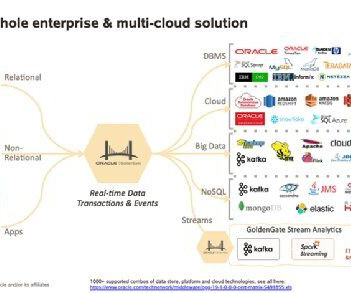
This is an architecture that’s well suited for the cloud since AWS S3 or Azure DLS2 can provide the requisite storage. It can include technologies that range from Oracle, Teradata and Apache Hadoop to Snowflake on Azure, RedShift on AWS or MS SQL in the on-premises data center, to name just a few. Yet, the overlap is evident.
Cloud platforms like AWS and Azure support Big Data tools, reducing costs and improving scalability. Companies like Amazon Web Services (AWS) and Microsoft Azure provide this service. It supports Big Data tools like Hadoop and Spark, allowing businesses to scale analytics operations efficiently. Google App Engine is an example.
Popular data lake solutions include Amazon S3 , Azure Data Lake , and Hadoop. Apache Hadoop Apache Hadoop is an open-source framework that supports the distributed processing of large datasets across clusters of computers. Data Processing Tools These tools are essential for handling large volumes of unstructured data.
Gain Experience with Big Data Technologies With the rise of Big Data, familiarity with technologies like Hadoop and Spark is essential. Familiarise yourself with cloud platforms like AWS, Google Cloud Platform , or Microsoft Azure for storing and processing large datasets. Additionally, familiarity with cloud platforms (e.g.,
Hadoop/Spark: Frameworks for distributed storage and processing of big data. Cloud Platforms (AWS, Azure, Google Cloud): Infrastructure for scalable and cost-effective data storage and analysis. SQL (Structured Query Language): Language for managing and querying relational databases.
It supports most major cloud providers, such as AWS, GCP, and Azure. LakeFS is fully compatible with many ecosystems of data engineering tools such as AWS, Azure, Spark, Databrick, MlFlow, Hadoop and others. The remote repository can be on the same computer, or it can be on the cloud.
Comet also integrates with popular data storage and processing tools like Amazon S3, Google Cloud Storage, and Hadoop. Comet also works with popular cloud platforms like AWS, GCP, and Azure, making it easy to deploy models to the cloud with just a few clicks.
Hadoop, though less common in new projects, is still crucial for batch processing and distributed storage in large-scale environments. Cloud Services Most major companies are using either Amazon Web Services (AWS) or Microsoft Azure, so excelling in one or the other will help any aspiring data scientist.
To store Image data, Cloud storage like Amazon S3 and GCP buckets, Azure Blob Storage are some of the best options, whereas one might want to utilize Hadoop + Hive or BigQuery to store clickstream and other forms of text and tabular data. One might want to utilize an off-the-shelf ML Ops Platform to maintain different versions of data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content