This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When it comes to data, there are two main types: data lakes and datawarehouses. What is a data lake? An enormous amount of raw data is stored in its original format in a data lake until it is required for analytics applications. Which one is right for your business?
The market for datawarehouses is booming. While there is a lot of discussion about the merits of datawarehouses, not enough discussion centers around data lakes. We talked about enterprise datawarehouses in the past, so let’s contrast them with data lakes. DataWarehouse.
Data engineering tools offer a range of features and functionalities, including data integration, data transformation, data quality management, workflow orchestration, and data visualization. Essential data engineering tools for 2023 Top 10 data engineering tools to watch out for in 2023 1.
Dating back to the 1970s, the data warehousing market emerged when computer scientist Bill Inmon first coined the term ‘datawarehouse’. Created as on-premise servers, the early datawarehouses were built to perform on just a gigabyte scale. The post How Will The Cloud Impact Data Warehousing Technologies?
Summary: A Hadoop cluster is a collection of interconnected nodes that work together to store and process large datasets using the Hadoop framework. Introduction A Hadoop cluster is a group of interconnected computers, or nodes, that work together to store and process large datasets using the Hadoop framework.
Here comes the role of Hive in Hadoop. Hive is a powerful data warehousing infrastructure that provides an interface for querying and analyzing large datasets stored in Hadoop. In this blog, we will explore the key aspects of Hive Hadoop. What is Hadoop ? Thus ensuring optimal performance.
Additionally, students should grasp the significance of BigData in various sectors, including healthcare, finance, retail, and social media. Understanding the implications of BigDataanalytics on business strategies and decision-making processes is also vital.
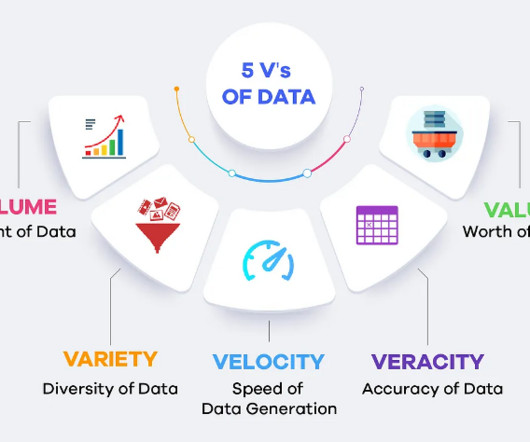
Introduction BigData continues transforming industries, making it a vital asset in 2025. The global BigDataAnalytics market, valued at $307.51 First, lets understand the basics of BigData. Key Takeaways Understand the 5Vs of BigData: Volume, Velocity, Variety, Veracity, Value.
The real advantage of bigdata lies not just in the sheer quantity of information but in the ability to process it in real-time. Variety Data comes in a myriad of formats including text, images, videos, and more. Veracity Veracity relates to the accuracy and trustworthiness of the data.
This involves several key processes: Extract, Transform, Load (ETL): The ETL process extracts data from different sources, transforms it into a suitable format by cleaning and enriching it, and then loads it into a datawarehouse or data lake. Data Lakes: These store raw, unprocessed data in its original format.
Consequently, here is an overview of the essential requirements that you need to have to get a job as an Azure Data Engineer. In-depth knowledge of distributed systems like Hadoop and Spart, along with computing platforms like Azure and AWS. Which service would you use to create DataWarehouse in Azure?
Data from various sources, collected in different forms, require data entry and compilation. That can be made easier today with virtual datawarehouses that have a centralized platform where data from different sources can be stored. One challenge in applying data science is to identify pertinent business issues.
Creating multimodal embeddings means training models on datasets with multiple data types to understand how these types of information are related. Multimodal embeddings help combine unstructured data from various sources in datawarehouses and ETL pipelines.
Summary: BigData tools empower organizations to analyze vast datasets, leading to improved decision-making and operational efficiency. Ultimately, leveraging BigDataanalytics provides a competitive advantage and drives innovation across various industries. Use Cases : Yahoo!
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content