This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
One prominent framework is Hadoop, which uses the Hadoop Distributed File System (HDFS) to provide robust data storage and processing capabilities. Hadoop systems Hadoop has gained traction as a foundational technology for building data lakes.
Top Employers Microsoft, Facebook, and consulting firms like Accenture are actively hiring in this field of remote data science jobs, with salaries generally ranging from $95,000 to $140,000. Additionally, knowledge of programming languages like Python or R can be beneficial for advanced analytics.
Summary: BigData tools empower organizations to analyze vast datasets, leading to improved decision-making and operational efficiency. Ultimately, leveraging BigDataanalytics provides a competitive advantage and drives innovation across various industries. Use Cases : Yahoo!
To define the term, let’s first say that structured data includes spreadsheets with their formalized rows and columns, “form-based” data resources where we know the fields in a document and so we know what values to expect… and of course relational databases, the purest form of an ordered and structured data repository.
Introduction HDFS (Hadoop Distributed File System) is not a traditional database but a distributed file system designed to store and process bigdata. It is a core component of the Apache Hadoop ecosystem and allows for storing and processing large datasets across multiple commodity servers.
Welcome to the world of databases, where the choice between SQL (Structured Query Language) and NoSQL (Not Only SQL) databases can be a significant decision. In this blog, we’ll explore the defining traits, benefits, use cases, and key factors to consider when choosing between SQL and NoSQL databases.
It can process any type of data, regardless of its variety or magnitude, and save it in its original format. Hadoop systems and data lakes are frequently mentioned together. However, instead of using Hadoop, data lakes are increasingly being constructed using cloud object storage services.
Data warehouse, also known as a decision support database, refers to a central repository, which holds information derived from one or more data sources, such as transactional systems and relational databases. The data collected in the system may in the form of unstructured, semi-structured, or structured data.
Summary: A Hadoop cluster is a collection of interconnected nodes that work together to store and process large datasets using the Hadoop framework. Introduction A Hadoop cluster is a group of interconnected computers, or nodes, that work together to store and process large datasets using the Hadoop framework.
Here comes the role of Hive in Hadoop. Hive is a powerful data warehousing infrastructure that provides an interface for querying and analyzing large datasets stored in Hadoop. In this blog, we will explore the key aspects of Hive Hadoop. What is Hadoop ? Thus ensuring optimal performance.
For instance, Tomorrow’s weather API retrieves crucial weather data, such as temperature, precipitation, air quality index, pollen index, etc., Also, it extracts historical weather data from various databases. Any app that uses Tomorrow’s weather API gets access to all this powerful data in real-time.
Type of Data: structured and unstructured from different sources of data Purpose: Cost-efficient bigdata storage Users: Engineers and scientists Tasks: storing data as well as bigdataanalytics, such as real-time analytics and deep learning Sizes: Store data which might be utilized.
BigData Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python.
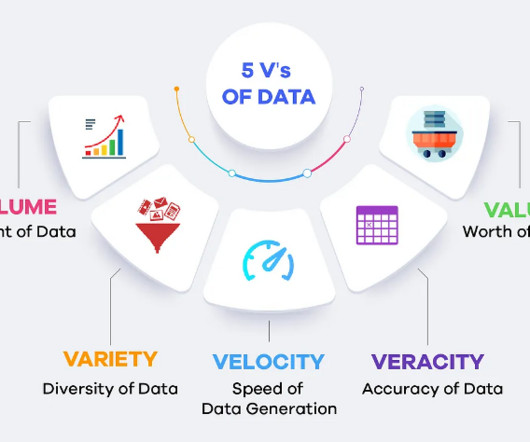
Velocity It indicates the speed at which data is generated and processed, necessitating real-time analytics capabilities. Businesses need to analyse data as it streams in to make timely decisions. This diversity requires flexible data processing and storage solutions.
The importance of BigData lies in its potential to provide insights that can drive business decisions, enhance customer experiences, and optimise operations. Organisations can harness BigDataAnalytics to identify trends, predict outcomes, and make informed decisions that were previously unattainable with smaller datasets.
They can use data on online user engagement to optimize their business models. They are able to utilize Hadoop-based data mining tools to improve their market research capabilities and develop better products. Companies that use bigdataanalytics can increase their profitability by 8% on average.
Introduction BigData continues transforming industries, making it a vital asset in 2025. The global BigDataAnalytics market, valued at $307.51 First, lets understand the basics of BigData. Key Takeaways Understand the 5Vs of BigData: Volume, Velocity, Variety, Veracity, Value.
As a result, the need to handle, process and store these large volumes of data requires BigData. Furthermore, the business organisations in the market are at an additional advantage considering that BigDataAnalytics has been revolutionising the IT sector. helps keep the data.
Key Takeaways BigData originates from diverse sources, including IoT and social media. Data lakes and cloud storage provide scalable solutions for large datasets. Processing frameworks like Hadoop enable efficient data analysis across clusters. Variety Variety indicates the different types of data being generated.
Key Takeaways BigData originates from diverse sources, including IoT and social media. Data lakes and cloud storage provide scalable solutions for large datasets. Processing frameworks like Hadoop enable efficient data analysis across clusters. Variety Variety indicates the different types of data being generated.
The real advantage of bigdata lies not just in the sheer quantity of information but in the ability to process it in real-time. Variety Data comes in a myriad of formats including text, images, videos, and more. Veracity Veracity relates to the accuracy and trustworthiness of the data.
Traditional marketing methods rely on guesswork, whereas BigData harnesses consumer behaviour insights to craft personalised, impactful strategies. The global BigDataanalytics market, valued at $307.51 This blog explores how BigData is redefining marketing materials to meet evolving objectives.
Consequently, here is an overview of the essential requirements that you need to have to get a job as an Azure Data Engineer. In-depth knowledge of distributed systems like Hadoop and Spart, along with computing platforms like Azure and AWS. Sound knowledge of relational databases or NoSQL databases like Cassandra.
SQL: Mastering Data Manipulation Structured Query Language (SQL) is a language designed specifically for managing and manipulating databases. While it may not be a traditional programming language, SQL plays a crucial role in Data Science by enabling efficient querying and extraction of data from databases.
They encompass all the origins from which data is collected, including: Internal Data Sources: These include databases, enterprise resource planning (ERP) systems, customer relationship management (CRM) systems, and flat files within an organization. Data can be structured (e.g., databases), semi-structured (e.g.,
Types of Unstructured Data As unstructured data grows exponentially, organisations face the challenge of processing and extracting insights from these data sources. Unlike structured data, unstructured data doesn’t fit neatly into predefined models or databases, making it harder to analyse using traditional methods.
The systems are designed to ensure data integrity, concurrency and quick response times for enabling interactive user transactions. In online analytical processing, operations typically consist of major fractions of large databases. The process therefore, helps in improving the scalability and fault tolerance.
This explosive growth is driven by the increasing volume of data generated daily, with estimates suggesting that by 2025, there will be around 181 zettabytes of data created globally. This foundational knowledge is essential for any Data Science project.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content