This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction YARN stands for Yet Another Resource Negotiator, a large-scale distributed data operating system used for BigDataAnalytics. The post The Tale of Apache Hadoop YARN! appeared first on Analytics Vidhya. Apart from resource management, […].
Introduction HDFS (Hadoop Distributed File System) is not a traditional database but a distributed file system designed to store and process bigdata. It is a core component of the Apache Hadoop ecosystem and allows for storing and processing large datasets across multiple commodity servers.
Introduction Bigdata processing is crucial today. Bigdataanalytics and learning help corporations foresee client demands, provide useful recommendations, and more. Hadoop, the Open-Source Software Framework for scalable and scattered computation of massive data sets, makes it easy.
Introduction BigData is a large and complex dataset generated by various sources and grows exponentially. It is so extensive and diverse that traditional data processing methods cannot handle it. The volume, velocity, and variety of BigData can make it difficult to process and analyze.
Bigdata, analytics, and AI all have a relationship with each other. For example, bigdataanalytics leverages AI for enhanced data analysis. In contrast, AI needs a large amount of data to improve the decision-making process. What is the relationship between bigdataanalytics and AI?
It integrates seamlessly with other AWS services and supports various data integration and transformation workflows. Google BigQuery: Google BigQuery is a serverless, cloud-based data warehouse designed for bigdataanalytics. It provides a scalable and fault-tolerant ecosystem for bigdata processing.
The rise of bigdata technologies and the need for data governance further enhance the growth prospects in this field. Machine Learning Engineer Description Machine Learning Engineers are responsible for designing, building, and deploying machine learning models that enable organizations to make data-driven decisions.
It can process any type of data, regardless of its variety or magnitude, and save it in its original format. Hadoop systems and data lakes are frequently mentioned together. However, instead of using Hadoop, data lakes are increasingly being constructed using cloud object storage services.
The company works consistently to enhance its business intelligence solutions through innovative new technologies including Hadoop-based services. Bigdata and data warehousing. With such large amounts of data available across industries, the need for efficient bigdataanalytics becomes paramount.
We have published a number of glowing articles on the benefits of bigdata in the world of marketing. However, many of these tutorials focus on the general benefits of bigdata, rather than specific, data-driven marketing strategies. BigData is the Key to Using Google Reviews for Optimal Impact.
Are you considering a career in bigdata ? Get ICT Training to Thrive in a Career in BigData. Data is a big deal. Many of the world’s biggest companies – like Amazon and Google have harnessed data to help them build colossal businesses that dominate their sectors. Online Courses.
Summary: A Hadoop cluster is a collection of interconnected nodes that work together to store and process large datasets using the Hadoop framework. Introduction A Hadoop cluster is a group of interconnected computers, or nodes, that work together to store and process large datasets using the Hadoop framework.
That’s where dataanalytics steps into the picture. BigDataAnalytics & Weather Forecasting: Understanding the Connection. Bigdataanalytics refers to a combination of technologies used to derive actionable insights from massive amounts of data.
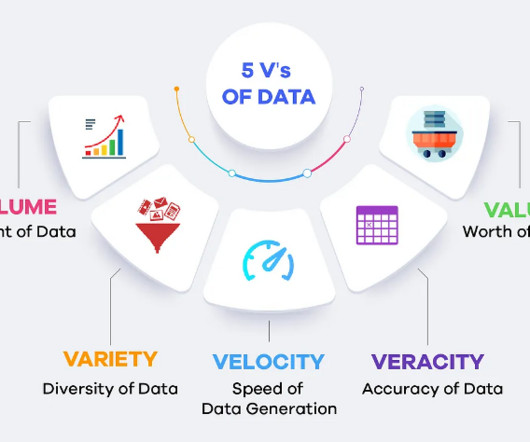
Summary: This blog delves into the multifaceted world of BigData, covering its defining characteristics beyond the 5 V’s, essential technologies and tools for management, real-world applications across industries, challenges organisations face, and future trends shaping the landscape.
Hadoop has become a highly familiar term because of the advent of bigdata in the digital world and establishing its position successfully. The technological development through BigData has been able to change the approach of data analysis vehemently. What is Hadoop? Let’s find out from the blog!
Summary: A comprehensive BigData syllabus encompasses foundational concepts, essential technologies, data collection and storage methods, processing and analysis techniques, and visualisation strategies. Fundamentals of BigData Understanding the fundamentals of BigData is crucial for anyone entering this field.
Summary: This article provides a comprehensive guide on BigData interview questions, covering beginner to advanced topics. Introduction BigData continues transforming industries, making it a vital asset in 2025. The global BigDataAnalytics market, valued at $307.51 What is BigData?
While there is a lot of discussion about the merits of data warehouses, not enough discussion centers around data lakes. We talked about enterprise data warehouses in the past, so let’s contrast them with data lakes. Both data warehouses and data lakes are used when storing bigdata.
The Power of BigData transcends the business sector. It moves beyond the vast amount of data to discover patterns and stories hidden inside. FUNDAMENTAL CHARACTERISTICS OF BIGDATABigdata isn’t defined by specific numbers or figures but by its sheer volume and rapid growth.
Here comes the role of Hive in Hadoop. Hive is a powerful data warehousing infrastructure that provides an interface for querying and analyzing large datasets stored in Hadoop. In this blog, we will explore the key aspects of Hive Hadoop. What is Hadoop ? Thus ensuring optimal performance.
The fact that data collection is a vital part of the decision-making process requires gathering data from multiple sources. Companies have been using BigData to analyse large volumes of data. There are three types of BigData structured, unstructured and semi-structured. What is BigData?
Data Storage Systems: Taking a look at Redshift, MySQL, PostGreSQL, Hadoop and others NoSQL Databases NoSQL databases are a type of database that does not use the traditional relational model. NoSQL databases are designed to store and manage large amounts of unstructured data.
The post BigData’s Potential For Disruptive Innovation appeared first on Dataconomy. An innovation that creates a new value network and market, and disrupts an existing market and value network by displacing the leading, highly established alliances, products and firms is known as Disruptive Innovation. But, every.
Summary: BigData encompasses vast amounts of structured and unstructured data from various sources. Key components include data storage solutions, processing frameworks, analytics tools, and governance practices. Key Takeaways BigData originates from diverse sources, including IoT and social media.
Summary: BigData encompasses vast amounts of structured and unstructured data from various sources. Key components include data storage solutions, processing frameworks, analytics tools, and governance practices. Key Takeaways BigData originates from diverse sources, including IoT and social media.
Summary: Map Reduce Architecture splits bigdata into manageable tasks, enabling parallel processing across distributed nodes. This design ensures scalability, fault tolerance, faster insights, and maximum performance for modern high-volume data challenges. billion in 2023 and will likely expand at a CAGR of 14.9%
Summary: BigData as a Service (BDaaS) offers organisations scalable, cost-effective solutions for managing and analysing vast data volumes. By outsourcing BigData functionalities, businesses can focus on deriving insights, improving decision-making, and driving innovation while overcoming infrastructure complexities.
Summary: BigData and Cloud Computing are essential for modern businesses. BigData analyses massive datasets for insights, while Cloud Computing provides scalable storage and computing power. Thats where bigdata and cloud computing come in. This massive collection of data is what we call BigData.
Bigdata is becoming more important to modern marketing. You can’t afford to ignore the benefits of dataanalytics in your marketing campaigns. Search Engine Watch has a great article on using dataanalytics for SEO. Keep in mind that bigdata drives search engines in 2020.
They can use data on online user engagement to optimize their business models. They are able to utilize Hadoop-based data mining tools to improve their market research capabilities and develop better products. Companies that use bigdataanalytics can increase their profitability by 8% on average.
BigData Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python.
Data scientists who work with Hadoop or Spark can certainly remember when those platforms came out; they’re still quite new compared to mainframes. Today, mainframe computer models have evolved to meet the challenges of cloud computing and bigdataanalytics.
Read more > #4 4 Real-World Examples of Financial Institutions Making Use of BigDataBigdata has moved beyond “new tech” status and into mainstream use. Within the financial industry, there are some specialized uses for data integration and bigdataanalytics.
While data science and machine learning are related, they are very different fields. In a nutshell, data science brings structure to bigdata while machine learning focuses on learning from the data itself. What is data science? This post will dive deeper into the nuances of each field.
Defining clear objectives and selecting appropriate techniques to extract valuable insights from the data is essential. Here are some project ideas suitable for students interested in bigdataanalytics with Python: 1. Here are a few business analyticsbigdata projects: 1.
Data Engineering is one of the most productive job roles today because it imbibes both the skills required for software engineering and programming and advanced analytics needed by Data Scientists. How to Become an Azure Data Engineer? Which service would you use to create Data Warehouse in Azure?
This blog delves into how Uber utilises DataAnalytics to enhance supply efficiency and service quality, exploring various aspects of its approach, technologies employed, case studies, challenges faced, and future directions. What Technologies Does Uber Use for Data Processing?
Java: Scalability and Performance Java is renowned for its scalability and robustness, making it an excellent choice for handling large-scale data processing. With its powerful ecosystem and libraries like Apache Hadoop and Apache Spark, Java provides the tools necessary for distributed computing and parallel processing.
As a programming language it provides objects, operators and functions allowing you to explore, model and visualise data. The programming language can handle BigData and perform effective data analysis and statistical modelling.
This explosive growth is driven by the increasing volume of data generated daily, with estimates suggesting that by 2025, there will be around 181 zettabytes of data created globally. The field has evolved significantly from traditional statistical analysis to include sophisticated Machine Learning algorithms and BigData technologies.
They store structured data in a format that facilitates easy access and analysis. Data Lakes: These store raw, unprocessed data in its original format. They are useful for bigdataanalytics where flexibility is needed.
The type of data processing enables division of data and processing tasks among the multiple machines or clusters. Distributed processing is commonly in use for bigdataanalytics, distributed databases and distributed computing frameworks like Hadoop and Spark.
This metadata will help make the data labelling, feature extraction, and model training processes smoother and easier. These processes are essential in AI-based bigdataanalytics and decision-making. Data Lakes Data lakes are crucial in effectively handling unstructured data for AI applications.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content