This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the data-driven world […] The post Monitoring Data Quality for Your BigDataPipelines Made Easy appeared first on Analytics Vidhya. Determine success by the precision of your charts, the equipment’s dependability, and your crew’s expertise. A single mistake, glitch, or slip-up could endanger the trip.
.- Dale Carnegie” Apache Kafka is a Software Framework for storing, reading, and analyzing streaming data. The post Build a Simple Realtime DataPipeline appeared first on Analytics Vidhya. The Internet of Things(IoT) devices can generate a large […].
Dataengineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential dataengineering tools for 2023 Top 10 dataengineering tools to watch out for in 2023 1.
Dataengineers play a crucial role in managing and processing bigdata. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. What is dataengineering?
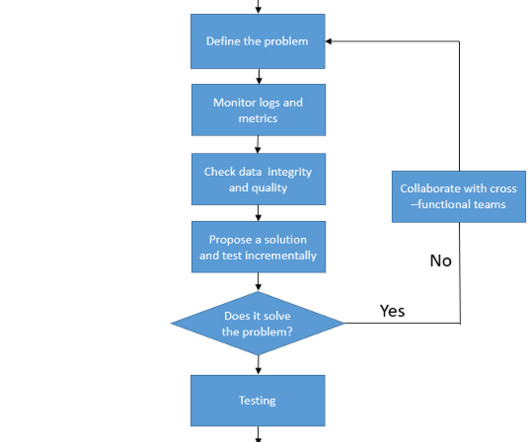
Bigdatapipelines are the backbone of modern data processing, enabling organizations to collect, process, and analyze vast amounts of data in real-time. Issues such as data inconsistencies, performance bottlenecks, and failures are inevitable.In Validate data format and schema compatibility.
Driven by significant advancements in computing technology, everything from mobile phones to smart appliances to mass transit systems generate and digest data, creating a bigdata landscape that forward-thinking enterprises can leverage to drive innovation. However, the bigdata landscape is just that.
With the explosive growth of bigdata over the past decade and the daily surge in data volumes, it’s essential to have a resilient system to manage the vast influx of information without failures. The success of any data initiative hinges on the robustness and flexibility of its bigdatapipeline.
Chatbots and virtual assistants are some of the common applications developed by NLP engineers for modern businesses. Bigdataengineer Potential pay range – US$206,000 to 296,000/yr They operate at the backend to build and maintain complex systems that store and process the vast amounts of data that fuel AI applications.
Aspiring and experienced DataEngineers alike can benefit from a curated list of books covering essential concepts and practical techniques. These 10 Best DataEngineering Books for beginners encompass a range of topics, from foundational principles to advanced data processing methods. What is DataEngineering?
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
While growing data enables companies to set baselines, benchmarks, and targets to keep moving ahead, it poses a question as to what actually causes it and what it means to your organization’s engineering team efficiency. What’s causing the data explosion? Explosive data growth can be too much to handle.
Unfolding the difference between dataengineer, data scientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Data Visualization: Matplotlib, Seaborn, Tableau, etc.
Experts in data science are needed in all kinds of industries, from companies developing dating apps to government security. Businesses and organizations of all kinds rely on bigdata to find solutions to problems and provide better services, so there are lots of different types of careers you could pursue with a degree in data science.
We couldn’t be more excited to announce two events that will be co-located with ODSC East in Boston this April: The DataEngineering Summit and the Ai X Innovation Summit. DataEngineering Summit Our second annual DataEngineering Summit will be in-person for the first time! Learn more about them below.
It seems straightforward at first for batch data, but the engineering gets even more complicated when you need to go from batch data to incorporating real-time and streaming data sources, and from batch inference to real-time serving.
Additionally, imagine being a practitioner, such as a data scientist, dataengineer, or machine learning engineer, who will have the daunting task of learning how to use a multitude of different tools. A feature platform should automatically process the datapipelines to calculate that feature.
Rajesh Nedunuri is a Senior DataEngineer within the Amazon Worldwide Returns and ReCommerce Data Services team. He specializes in designing, building, and optimizing large-scale data solutions.
BigData As datasets become larger and more complex, knowing how to work with them will be key. Bigdata isn’t an abstract concept anymore, as so much data comes from social media, healthcare data, and customer records, so knowing how to parse all of that is needed.
DataEngineerDataengineers are responsible for the end-to-end process of collecting, storing, and processing data. They use their knowledge of data warehousing, data lakes, and bigdata technologies to build and maintain datapipelines.
BigData Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python.
If the data sources are additionally expanded to include the machines of production and logistics, much more in-depth analyses for error detection and prevention as well as for optimizing the factory in its dynamic environment become possible.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, dataengineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. For example, neptune.ai
The LookML view and model information is brought into Amazon S3 through a separate datapipeline (not shown). About the Authors Apurva Gawad is a Senior DataEngineer at Twilio specializing in building scalable systems for data ingestion and empowering business teams to derive valuable insights from data.
Data Analytics in the Age of AI, When to Use RAG, Examples of Data Visualization with D3 and Vega, and ODSC East Selling Out Soon Data Analytics in the Age of AI Let’s explore the multifaceted ways in which AI is revolutionizing data analytics, making it more accessible, efficient, and insightful than ever before.
To pursue a data science career, you need a deep understanding and expansive knowledge of machine learning and AI. And you should have experience working with bigdata platforms such as Hadoop or Apache Spark. Your skill set should include the ability to write in the programming languages Python, SAS, R and Scala.
This pipeline facilitates the smooth, automated flow of information, preventing many problems that enterprises face, such as data corruption, conflict, and duplication of data entries. A streaming datapipeline is an enhanced version which is able to handle millions of events in real-time at scale.
Managing datapipelines efficiently is paramount for any organization. The Snowflake Data Cloud has introduced a groundbreaking feature that promises to simplify and supercharge this process: Snowflake Dynamic Tables. Flexibility: Dynamic tables allow batch and streaming pipelines to be specified in the same way.
However, not all of it is necessarily actionable and some get stuck in queues or bigdata batch processing. Additionally, Apache Flink contextualizes your data by detecting patterns, enabling you to understand how things happen alongside each other.
JuMa is tightly integrated with a range of BMW Central IT services, including identity and access management, roles and rights management, BMW Cloud Data Hub (BMW’s data lake on AWS) and on-premises databases. He works closely with enterprise customers to design data platforms and build advanced analytics and ML use cases.
The first generation of data architectures represented by enterprise data warehouse and business intelligence platforms were characterized by thousands of ETL jobs, tables, and reports that only a small group of specialized dataengineers understood, resulting in an under-realized positive impact on the business.
Let’s demystify this using the following personas and a real-world analogy: Data and ML engineers (owners and producers) – They lay the groundwork by feeding data into the feature store Data scientists (consumers) – They extract and utilize this data to craft their models Dataengineers serve as architects sketching the initial blueprint.
The advent of bigdata, affordable computing power, and advanced machine learning algorithms has fueled explosive growth in data science across industries. However, research shows that up to 85% of data science projects fail to move beyond proofs of concept to full-scale deployment.
Integration: Airflow integrates seamlessly with other dataengineering and Data Science tools like Apache Spark and Pandas. IBM Infosphere DataStage IBM Infosphere DataStage is an enterprise-level ETL tool that enables users to design, develop, and run datapipelines. Read Further: Azure DataEngineer Jobs.
Enhanced Data Quality : These tools ensure data consistency and accuracy, eliminating errors often occurring during manual transformation. Scalability : Whether handling small datasets or processing bigdata, transformation tools can easily scale to accommodate growing data volumes.
This includes important stages such as feature engineering, model development, datapipeline construction, and data deployment. In the data science industry, effective communication and collaboration play a crucial role. Brainstorming sessions are often held to discuss and plan data collection strategies.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
And because data assets within the catalog have quality scores and social recommendations, Alex has greater trust and confidence in the data she’s using for her decision-making recommendations. This is especially helpful when handling massive amounts of bigdata. Protected and compliant data.
Unified Data Services: Azure Synapse Analytics combines bigdata and data warehousing, offering a unified analytics experience. Azure’s global network of data centres ensures high availability and performance, making it a powerful platform for Data Scientists to leverage for diverse data-driven projects.
Datafold is a tool focused on data observability and quality. It is particularly popular among dataengineers as it integrates well with modern datapipelines (e.g., Source: [link] Monte Carlo is a code-free data observability platform that focuses on data reliability across datapipelines.
Scala is worth knowing if youre looking to branch into dataengineering and working with bigdata more as its helpful for scaling applications. Knowing all three frameworks covers the most ground for aspiring data science professionals, so you cover plenty of ground knowing thisgroup.
The hype around generative AI has shifted the industry narrative overnight from the bigdata era of “every company is a data company” to the new belief that “every company is an AI company.” Validating the DataEngineering Strategy There is no one-size-fits-all approach to chunking unstructured data.
Data ingestion/integration services. Data orchestration tools. These tools are used to manage bigdata, which is defined as data that is too large or complex to be processed by traditional means. How Did the Modern Data Stack Get Started? What Are the Benefits of a Modern Data Stack? Data scientists.
Compute, bigdata, large commoditized models—all important stages. But now we’re entering a period where data investments have massive returns from all performance as well as business impact. The reason is that most teams do not have access to a robust data ecosystem for ML development.
Compute, bigdata, large commoditized models—all important stages. But now we’re entering a period where data investments have massive returns from all performance as well as business impact. The reason is that most teams do not have access to a robust data ecosystem for ML development.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content