This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A datapipeline is a technical system that automates the flow of data from one source to another. While it has many benefits, an error in the pipeline can cause serious disruptions to your business. Here are some of the best practices for preventing errors in your datapipeline: 1. Monitor Your Data Sources.
Data engineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. It integrates seamlessly with other AWS services and supports various data integration and transformation workflows.
Data engineers play a crucial role in managing and processing bigdata. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. They must also ensure that data privacy regulations, such as GDPR and CCPA , are followed.
Driven by significant advancements in computing technology, everything from mobile phones to smart appliances to mass transit systems generate and digest data, creating a bigdata landscape that forward-thinking enterprises can leverage to drive innovation. However, the bigdata landscape is just that.
With the advent of bigdata in the modern world, RTOS is becoming increasingly important. As software expert Tim Mangan explains, a purpose-built real-time OS is more suitable for apps that involve tons of data processing. The BigData and RTOS connection IoT and embedded devices are among the biggest sources of bigdata.
The rise of data lakes, IOT analytics, and bigdatapipelines has introduced a new world of fast, bigdata. How Data Catalogs Can Help. Data catalogs evolved as a key component of the datagovernance revolution by creating a bridge between the new world and old world of datagovernance.
While growing data enables companies to set baselines, benchmarks, and targets to keep moving ahead, it poses a question as to what actually causes it and what it means to your organization’s engineering team efficiency. What’s causing the data explosion? Bigdata analytics from 2022 show a dramatic surge in information consumption.
Introduction Data Engineering is the backbone of the data-driven world, transforming raw data into actionable insights. As organisations increasingly rely on data to drive decision-making, understanding the fundamentals of Data Engineering becomes essential. What is Data Engineering? million by 2028.
In today’s fast-paced business environment, the significance of Data Observability cannot be overstated. Data Observability enables organizations to detect anomalies, troubleshoot issues, and maintain datapipelines effectively. Schema A data schema defines the structure and organization of your data.
Securing AI models and their access to data While AI models need flexibility to access data across a hybrid infrastructure, they also need safeguarding from tampering (unintentional or otherwise) and, especially, protected access to data. Bias can also find its way into a model’s outputs long after deployment.
The elf teams used data engineering to improve gift matching and deployed bigdata to scale the naughty and nice list long ago , before either approach was even considered within our warmer climes. The best data was discovered, experts were identified, and conversations were starting. Make datagovernance an asset.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Visualization: Matplotlib, Seaborn, Tableau, etc.
A self-service infrastructure portal for infrastructure and governance. Databricks Databricks is a cloud-native platform for bigdata processing, machine learning, and analytics built using the Data Lakehouse architecture. It could help you detect and prevent datapipeline failures, data drift, and anomalies.
With this integration, customers can now harness the full power of Azure’s BigData offerings in a self-service manner to gain immediate value.”. This highlights the two companies’ shared vision on self-service data discovery with an emphasis on collaboration and datagovernance.
Semantics, context, and how data is tracked and used mean even more as you stretch to reach post-migration goals. This is why, when data moves, it’s imperative for organizations to prioritize data discovery. Data discovery is also critical for datagovernance , which, when ineffective, can actually hinder organizational growth.
Let’s demystify this using the following personas and a real-world analogy: Data and ML engineers (owners and producers) – They lay the groundwork by feeding data into the feature store Data scientists (consumers) – They extract and utilize this data to craft their models Data engineers serve as architects sketching the initial blueprint.
This is the practice of creating, updating and consistently enforcing the processes, rules and standards that prevent errors, data loss, data corruption, mishandling of sensitive or regulated data, and data breaches. Learn more about designing the right data architecture to elevate your data quality here.
Enhanced Data Quality : These tools ensure data consistency and accuracy, eliminating errors often occurring during manual transformation. Scalability : Whether handling small datasets or processing bigdata, transformation tools can easily scale to accommodate growing data volumes.
Its architecture includes FlowFiles, repositories, and processors, enabling efficient data processing and transformation. With a user-friendly interface and robust features, NiFi simplifies complex data workflows and enhances real-time data integration.
It synthesizes all the metadata around your organization’s data assets and arranges the information into a simple, easy-to-understand format. Questions to ask each vendor: Does your data integration solution provide access to the metadata? What datagovernance controls do your solutions have in place?
The first generation of data architectures represented by enterprise data warehouse and business intelligence platforms were characterized by thousands of ETL jobs, tables, and reports that only a small group of specialized data engineers understood, resulting in an under-realized positive impact on the business.
And because data assets within the catalog have quality scores and social recommendations, Alex has greater trust and confidence in the data she’s using for her decision-making recommendations. This is especially helpful when handling massive amounts of bigdata. Protected and compliant data.
We already know that a data quality framework is basically a set of processes for validating, cleaning, transforming, and monitoring data. DataGovernanceDatagovernance is the foundation of any data quality framework. It primarily caters to large organizations with complex data environments.
Data ingestion/integration services. Data orchestration tools. These tools are used to manage bigdata, which is defined as data that is too large or complex to be processed by traditional means. How Did the Modern Data Stack Get Started? What Are the Benefits of a Modern Data Stack?
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
In the data-driven world we live in today, the field of analytics has become increasingly important to remain competitive in business. In fact, a study by McKinsey Global Institute shows that data-driven organizations are 23 times more likely to outperform competitors in customer acquisition and nine times […].
Compute, bigdata, large commoditized models—all important stages. But now we’re entering a period where data investments have massive returns from all performance as well as business impact. The reason is that most teams do not have access to a robust data ecosystem for ML development.
Compute, bigdata, large commoditized models—all important stages. But now we’re entering a period where data investments have massive returns from all performance as well as business impact. The reason is that most teams do not have access to a robust data ecosystem for ML development.
Have you ever waited for that one expensive parcel that shows “shipped,” but you have no clue where it is? The tracking history stopped updating five days ago, and you have almost lost hope. But wait, 11 days later, you have it at your doorstep.
Have you ever waited for that one expensive parcel that shows “shipped,” but you have no clue where it is? The tracking history stopped updating five days ago, and you have almost lost hope. But wait, 11 days later, you have it at your doorstep.
To establish trust between the data producers and data consumers, SageMaker Catalog also integrates the data quality metrics and data lineage events to track and drive transparency in datapipelines. Data analysts discover the data and subscribe to the data.
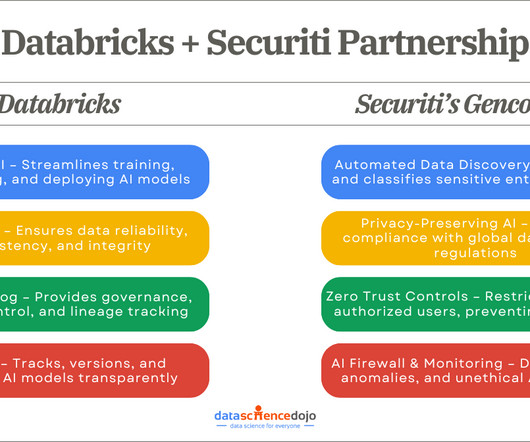
Securiti’s Data Command Graph delivers this foundation by providing comprehensive contextual insights about data objects and their controls, enabling complete monitoring and governance of the entire enterprise AI system across all interconnected components rather than focusing solely on models.
The first step in developing and deploying generative AI use cases is having a well-defined data strategy. Their datapipeline (as shown in the following architecture diagram) consists of ingestion, storage, ETL (extract, transform, and load), and a datagovernance layer.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content