This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When it comes to data, there are two main types: data lakes and datawarehouses. What is a data lake? An enormous amount of raw data is stored in its original format in a data lake until it is required for analytics applications. Which one is right for your business? Let’s take a closer look.
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a datawarehouse The datawarehouse (DW) was an approach to data architecture and structured data management that really hit its stride in the early 1990s.
Data engineering tools offer a range of features and functionalities, including data integration, data transformation, data quality management, workflow orchestration, and data visualization. Essential data engineering tools for 2023 Top 10 data engineering tools to watch out for in 2023 1.
Data engineers play a crucial role in managing and processing bigdata. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. Implementing data security measures Data security is a critical aspect of data engineering.
Datawarehouse vs. data lake, each has their own unique advantages and disadvantages; it’s helpful to understand their similarities and differences. In this article, we’ll focus on a data lake vs. datawarehouse. Read Many of the preferred platforms for analytics fall into one of these two categories.
Summary: A datawarehouse is a central information hub that stores and organizes vast amounts of data from different sources within an organization. Unlike operational databases focused on daily tasks, datawarehouses are designed for analysis, enabling historical trend exploration and informed decision-making.
It has been ten years since Pentaho Chief Technology Officer James Dixon coined the term “data lake.” While datawarehouse (DWH) systems have had longer existence and recognition, the data industry has embraced the more […]. The post A Bridge Between Data Lakes and DataWarehouses appeared first on DATAVERSITY.
In the ever-evolving world of bigdata, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. Understanding Data Lakes A data lake is a centralized repository that stores structured, semi-structured, and unstructured data in its raw format.
Summary: A comprehensive BigData syllabus encompasses foundational concepts, essential technologies, data collection and storage methods, processing and analysis techniques, and visualisation strategies. Fundamentals of BigData Understanding the fundamentals of BigData is crucial for anyone entering this field.
Discover the nuanced dissimilarities between Data Lakes and DataWarehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are Data Lakes and DataWarehouses. It acts as a repository for storing all the data.
It is comprised of commodity cloud object storage, open data and open table formats, and high-performance open-source query engines. To help organizations scale AI workloads, we recently announced IBM watsonx.data , a data store built on an open data lakehouse architecture and part of the watsonx AI and data platform.
Bigdata analytics: Bigdata analytics is designed to handle massive volumes of data from various sources, including structured and unstructured data. Bigdata analytics is essential for organizations dealing with large-scale data, such as social media platforms, e-commerce giants, and scientific research.
While growing data enables companies to set baselines, benchmarks, and targets to keep moving ahead, it poses a question as to what actually causes it and what it means to your organization’s engineering team efficiency. What’s causing the data explosion? Bigdata analytics from 2022 show a dramatic surge in information consumption.
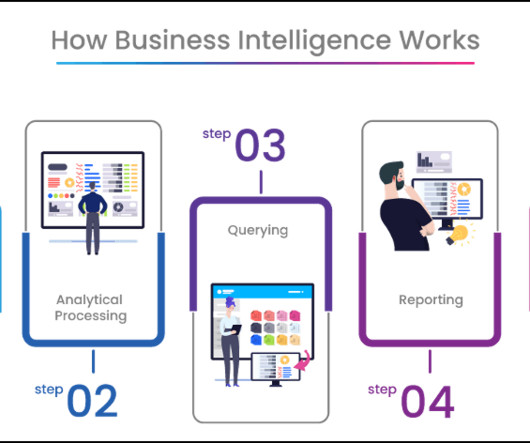
Introduction In the rapidly evolving landscape of data analytics, Business Intelligence (BI) tools have become indispensable for organizations seeking to leverage their bigdata stores for strategic decision-making. Tableau – Tableau is celebrated for its advanced data visualization and interactive dashboard features.
We also made the case that query and reporting, provided by bigdata engines such as Presto, need to work with the Spark infrastructure framework to support advanced analytics and complex enterprise data decision-making. To do so, Presto and Spark need to readily work with existing and modern datawarehouse infrastructures.
Our platform combines data insights with human intelligence in pursuit of this mission. Susannah Barnes, an Alation customer and senior datagovernance specialist at American Family Insurance, introduced our team to faculty at the School of Information Studies of the University of Wisconsin, Milwaukee (UWM-SOIS), her alma mater.
In today’s world, data-driven applications demand more flexibility, scalability, and auditability, which traditional datawarehouses and modeling approaches lack. This is where the Snowflake Data Cloud and data vault modeling comes in handy. What is Data Vault Modeling?
Bigdata analytics, IoT, AI, and machine learning are revolutionizing the way businesses create value and competitive advantage. Organizations have come to understand that they can use both internal and external data to drive tremendous business value. This can add stress to data management teams and datagovernance processes.
It is known to have benefits in handling data due to its robustness, speed, and scalability. A typical modern data stack consists of the following: A datawarehouse. Data ingestion/integration services. Data orchestration tools. In the past, data movement was defined by ETL: extract, transform, and load.
This was, without a question, a significant departure from traditional analytic environments, which often meant vendor-lock in and the inability to work with data at scale. Another unexpected challenge was the introduction of Spark as a processing framework for bigdata. Comprehensive data security and datagovernance (i.e.
They’re built on machine learning algorithms that create outputs based on an organization’s data or other third-party bigdata sources. Sometimes, these outputs are biased because the data used to train the model was incomplete or inaccurate in some way. And that makes sense.
Introduction Data Engineering is the backbone of the data-driven world, transforming raw data into actionable insights. As organisations increasingly rely on data to drive decision-making, understanding the fundamentals of Data Engineering becomes essential. What is Data Engineering? million by 2028.
A part of that journey often involves moving fragmented on-premises data to a cloud datawarehouse. You clearly shouldn’t move everything from your on-premises datawarehouses. Otherwise, you can end up with a data swamp. Put differently, you can migrate faster if you know the right data to move.
As bigdata matures, the way you think about it may have to shift also. It’s no longer enough to build the datawarehouse. Self-service analytics environments are giving rise to the data marketplace. Self-service analytics environments are giving rise to the data marketplace.
It utilises the Hadoop Distributed File System (HDFS) and MapReduce for efficient data management, enabling organisations to perform bigdata analytics and gain valuable insights from their data. In a Hadoop cluster, data stored in the Hadoop Distributed File System (HDFS), which spreads the data across the nodes.
As data drives more and more of the modern economy, datagovernance and data management are racing to keep up with an ever-expanding range of requirements, constraints and opportunities. Prior to the BigData revolution, companies were inward-looking in terms of data.
The first generation of data architectures represented by enterprise datawarehouse and business intelligence platforms were characterized by thousands of ETL jobs, tables, and reports that only a small group of specialized data engineers understood, resulting in an under-realized positive impact on the business.
Semantics, context, and how data is tracked and used mean even more as you stretch to reach post-migration goals. This is why, when data moves, it’s imperative for organizations to prioritize data discovery. Data discovery is also critical for datagovernance , which, when ineffective, can actually hinder organizational growth.
Industry leaders like General Electric, Munich Re and Pfizer are turning to self-service analytics and modern datagovernance. They are leveraging data catalogs as a foundation to automatically analyze technical and business metadata, at speed and scale. “By Ventana Research’s 2018 Digital Innovation Award for BigData.
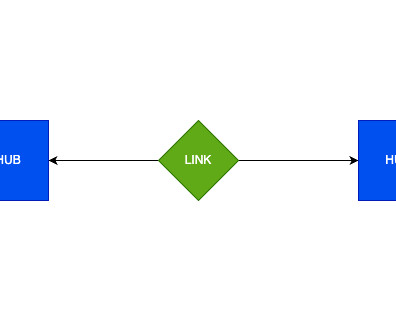
What is a Data Vault Architecture? Created in the 1990s by a team at Lockheed Martin, Data Vault Modeling is a hybrid approach that combines traditional relational datawarehouse models with newer bigdata architectures to build a datawarehouse for enterprise-scale analytics. Contact phData!
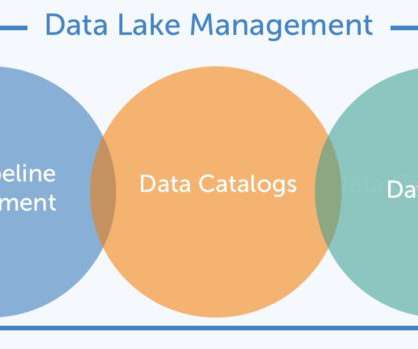
It uses metadata and data management tools to organize all data assets within your organization. It synthesizes the information across your data ecosystem—from data lakes, datawarehouses, and other data repositories—to empower authorized users to search for and access business-ready data for their projects and initiatives.
This brief definition makes several points about data catalogs—data management, searching, data inventory, and data evaluation—but all depend on the central capability to provide a collection of metadata. Data catalogs have become the standard for metadata management in the age of bigdata and self-service analytics.
Its architecture includes FlowFiles, repositories, and processors, enabling efficient data processing and transformation. With a user-friendly interface and robust features, NiFi simplifies complex data workflows and enhances real-time data integration. Its visual interface allows users to design complex ETL workflows with ease.
Wide support for enterprise-grade sources and targets Large organizations with complex IT landscapes must have the capability to easily connect to a wide variety of data sources. Whether it’s a cloud datawarehouse or a mainframe, look for vendors who have a wide range of capabilities that can adapt to your changing needs.
They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. With expertise in programming languages like Python , Java , SQL, and knowledge of bigdata technologies like Hadoop and Spark, data engineers optimize pipelines for data scientists and analysts to access valuable insights efficiently.
Unlike traditional BI tools, its user-friendly interface ensures that users of all technical levels can seamlessly interact with data. The platform’s integration with cloud datawarehouses like Snowflake AI Data Cloud , Google BigQuery, and Amazon Redshift makes it a vital tool for organizations harnessing bigdata.
Modern data catalogs—originated to help data analysts find and evaluate data—continue to meet the needs of analysts, but they have expanded their reach. They are now central to data stewardship, data curation, and datagovernance—all metadata dependent activities.
We already know that a data quality framework is basically a set of processes for validating, cleaning, transforming, and monitoring data. DataGovernanceDatagovernance is the foundation of any data quality framework. It primarily caters to large organizations with complex data environments.
Some of the techniques for data integration include data replication, streaming data integration, extract, transformation and load, bulk movement of data or batch-wise movement of data. BigData Management It involves the management of a large volume of data to improve the operation.
Alation’s TrustCheck technology enables a new and modern approach to agile datagovernance. And, it recently received the 2018 Digital Innovation Award for BigData from Ventana Research. TrustCheck is helping customers improve analytics behavior and ensure compliance, without restricting analytical agility.
Data Warehousing and ETL Processes What is a datawarehouse, and why is it important? A datawarehouse is a centralised repository that consolidates data from various sources for reporting and analysis. It is essential to provide a unified data view and enable business intelligence and analytics.
Every year for the last three years, NewVenture Partners has published an executive survey on AI and bigdata. 72% of businesses do not yet have a data culture despite increasing investment in bigdata and AI.” We have the technology, but we don’t have the data culture to succeed with that technology.
The next stops on the MLDC World Tour include Data Transparency in Washington, Gartner Symposium/ITxpo in Orlando, Teradata Analytics Universe in Las Vegas, Tableau in New Orleans, BigData LDN in London, TDWI in Orlando and Forrester Data Strategy & Insights in Orlando, again. Data Catalogs Are the New Black.
In the data-driven world we live in today, the field of analytics has become increasingly important to remain competitive in business. In fact, a study by McKinsey Global Institute shows that data-driven organizations are 23 times more likely to outperform competitors in customer acquisition and nine times […].
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content