This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the ever-evolving world of bigdata, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. Understanding DataLakes A datalake is a centralized repository that stores structured, semi-structured, and unstructured data in its raw format.
Bigdata in the gaming industry has played a phenomenal role in the field. We have previously talked about the benefits of using bigdata by gaming providers that offer cash games, such as slots. However, more mainstream games use bigdata as well. BigData is the Lynchpin of the Fortnite Gaming Experience.
In this contributed article, Tom Scott, CEO of Streambased, outlines the path event streaming systems have taken to arrive at the point where they must adopt analytical use cases and looks at some possible futures in this area.
Unified data storage : Fabric’s centralized datalake, Microsoft OneLake, eliminates data silos and provides a unified storage system, simplifying data access and retrieval. OneLake is designed to store a single copy of data in a unified location, leveraging the open-source Apache Parquet format.
But, the amount of data companies must manage is growing at a staggering rate. Research analyst firm Statista forecasts global data creation will hit 180 zettabytes by 2025. One way to address this is to implement a datalake: a large and complex database of diverse datasets all stored in their original format.
While there is more of a push to use cloud data for off-site backup , this method comes with its own caveats. In the event of a network shutdown or failure, it may take much longer to restore functionality (and therefore connection) to a cloud-hosted off-site backup. BigData Storage Concerns. Conclusion.
Summary: A comprehensive BigData syllabus encompasses foundational concepts, essential technologies, data collection and storage methods, processing and analysis techniques, and visualisation strategies. Fundamentals of BigData Understanding the fundamentals of BigData is crucial for anyone entering this field.
Real-Time ML with Spark and SBERT, AI Coding Assistants, DataLake Vendors, and ODSC East Highlights Getting Up to Speed on Real-Time Machine Learning with Spark and SBERT Learn more about real-time machine learning by using this approach that uses Apache Spark and SBERT. Well, these libraries will give you a solid start.
Summary: Netflix’s sophisticated BigData infrastructure powers its content recommendation engine, personalization, and data-driven decision-making. As a pioneer in the streaming industry, Netflix utilises advanced data analytics to enhance user experience, optimise operations, and drive strategic decisions.
Diagnostic analytics: Diagnostic analytics goes a step further by analyzing historical data to determine why certain events occurred. By understanding the “why” behind past events, organizations can make informed decisions to prevent or replicate them. Ensure that data is clean, consistent, and up-to-date.
In this episode, James Serra, author of “Deciphering Data Architectures: Choosing Between a Modern Data Warehouse, Data Fabric, Data Lakehouse, and Data Mesh” joins us to discuss his book and dive into the current state and possible future of data architectures. Interested in attending an ODSC event?
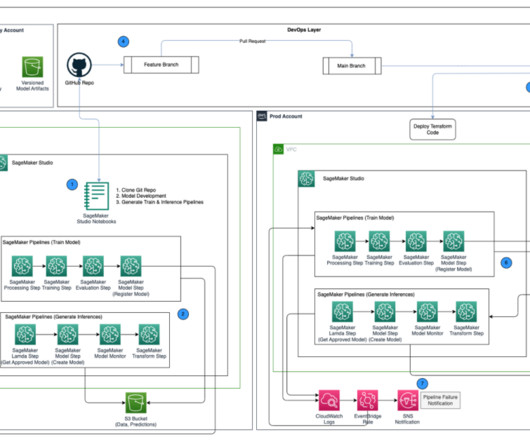
Data and governance foundations – This function uses a data mesh architecture for setting up and operating the datalake, central feature store, and data governance foundations to enable fine-grained data access. This framework considers multiple personas and services to govern the ML lifecycle at scale.
If the question was Whats the schedule for AWS events in December?, AWS usually announces the dates for their upcoming # re:Invent event around 6-9 months in advance. Previously, Karam developed big-data analytics applications and SOX compliance solutions for Amazons Fintech and Merchant Technologies divisions.
It is about hurricanes and bigevents like the California wildfires, but it is also about complex things like satellite launches, for example, or big building projects. A lot of people in our audience are looking at implementing datalakes or are in the middle of bigdatalake initiatives.
Its architecture includes FlowFiles, repositories, and processors, enabling efficient data processing and transformation. With a user-friendly interface and robust features, NiFi simplifies complex data workflows and enhances real-time data integration.
Data Engineer Data engineers are responsible for the end-to-end process of collecting, storing, and processing data. They use their knowledge of data warehousing, datalakes, and bigdata technologies to build and maintain data pipelines. Interested in attending an ODSC event?
The triggers need to be scheduled to write the data to S3 at a period frequency based on the business need for training the models. Prior joining AWS, as a Data/Solution Architect he implemented many projects in BigData domain, including several datalakes in Hadoop ecosystem.
Enterprise data architects, data engineers, and business leaders from around the globe gathered in New York last week for the 3-day Strata Data Conference , which featured new technologies, innovations, and many collaborative ideas. 2) When data becomes information, many (incremental) use cases surface.
To pursue a data science career, you need a deep understanding and expansive knowledge of machine learning and AI. And you should have experience working with bigdata platforms such as Hadoop or Apache Spark. Diagnostic analytics: Diagnostic analytics helps pinpoint the reason an event occurred.
Data Governance Account This account hosts data governance services for datalake, central feature store, and fine-grained data access. The lead data scientist approves the model locally in the ML Dev Account. Follow the sample code to run an ML experiment pipeline using data stored in an S3 bucket.
Collaboration across teams – Shared features allow disparate teams like fraud, marketing, and sales to collaborate on building ML models using the same reliable data instead of creating siloed features. Audit trail for compliance – Administrators can monitor feature usage by all accounts centrally using CloudTrail event logs.
With the recently launched Amazon Monitron Kinesis data export v2 feature , your OT team can stream incoming measurement data and inference results from Amazon Monitron via Amazon Kinesis to AWS Simple Storage Service (Amazon S3) to build an Internet of Things (IoT) datalake. Choose Create delivery stream.
Apache Kafka for Real-Time Machine Learning Without a DataLake Kai Waehner | Global Field CTO, Author, International Speaker This talk compares a cloud-native data streaming architecture to traditional batch and bigdata alternatives and explains benefits like the simplified architecture, the ability to reprocess events in the same order for training (..)
HPCC Systems — The Kit and Kaboodle for BigData and Data Science Bob Foreman | Software Engineering Lead | LexisNexis/HPCC Join this session to learn how ECL can help you create powerful data queries through a comprehensive and dedicated datalake platform. Interested in attending an ODSC event?
Data Morph: A Cautionary Tale of Summary Statistics Visualization in Bayesian Workflow Using Python or R Harnessing Bayesian Statistics for Business-Centric Data Science Data Engineering and BigData Join this track to learn the latest techniques and processes to analyze raw data and automate data into mechanical processes and algorithms.
Introduction Data Engineering is the backbone of the data-driven world, transforming raw data into actionable insights. As organisations increasingly rely on data to drive decision-making, understanding the fundamentals of Data Engineering becomes essential. million by 2028.
Databricks Databricks is a cloud-native platform for bigdata processing, machine learning, and analytics built using the Data Lakehouse architecture. LakeFS LakeFS is an open-source platform that provides datalake versioning and management capabilities.
To combine the collected data, you can integrate different data producers into a datalake as a repository. A central repository for unstructured data is beneficial for tasks like analytics and data virtualization. Data Cleaning The next step is to clean the data after ingesting it into the datalake.
Every year for the last three years, NewVenture Partners has published an executive survey on AI and bigdata. 72% of businesses do not yet have a data culture despite increasing investment in bigdata and AI.” We have the technology, but we don’t have the data culture to succeed with that technology.
Storage Solutions: Secure and scalable storage options like Azure Blob Storage and Azure DataLake Storage. Key features and benefits of Azure for Data Science include: Scalability: Easily scale resources up or down based on demand, ideal for handling large datasets and complex computations.
ML also helps businesses forecast and decrease customer churn (the rate at which a company loses customers), a widespread use of bigdata. ML classification algorithms are also used to label events as fraud, classify phishing attacks and more. Antivirus programs may use AI and ML techniques to detect and block malware.
Supports the ability to interact with the actual data and perform analysis on it. This provides the facility a time or event for a job to run and offers useful post-run information. Similar to a data warehouse schema, this prep tool automates the development of the recipe to match. Automatic sampling to test transformation.
Policy 6 – Attach CloudWatchEventsFullAccess , which is an AWS managed policy that grants full access to CloudWatch Events. She holds a master’s degree in Computer Science specialized in Data Science from the University of Colorado, Boulder. DataLake Architect with AWS Professional Services. Sunita Koppar is a Sr.
A typical data pipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process. Data Ingestion : Involves raw data collection from origin and storage using architectures such as batch, streaming or event-driven.
Bigdata has the power to transform any small business. One study found that 77% of small businesses don’t even have a bigdata strategy. If your company lacks a bigdata strategy, then you need to start developing one today. Using BigData to Fix Your Biggest Problems as a Business Owner.
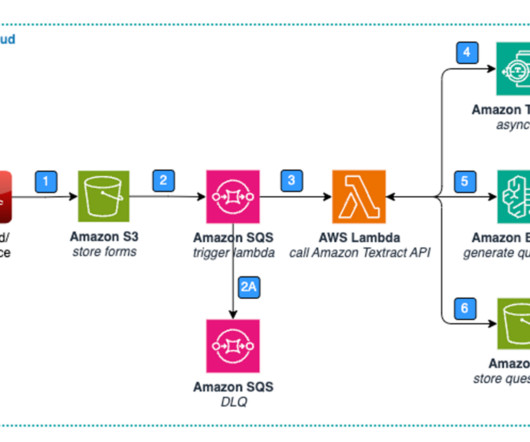
Whenever a new form is loaded, an event is invoked in Amazon SQS. As healthcare organizations continue to digitize their operations, such AI-powered solutions can play a crucial role in improving data management, maintaining compliance, and ultimately enhancing patient care through better insights and decision-making.
Plan for rollback and recovery from production security events and service disruptions such as prompt injection, training data poisoning, model denial of service, and model theft early on, and define the mitigations you will use as you define application requirements.
How Keeper Efficiency is implemented This Bundesliga Match Fact consumes both event and positional data. Positional data is information gathered by cameras on the positions of the players and ball at any moment during the match (x-y coordinates), arriving at 25Hz. Tareq Haschemi is a consultant within AWS Professional Services.
Summary: BigData tools empower organizations to analyze vast datasets, leading to improved decision-making and operational efficiency. Ultimately, leveraging BigData analytics provides a competitive advantage and drives innovation across various industries.
Enterprises are facing challenges in accessing their data assets scattered across various sources because of increasing complexities in managing vast amount of data. Traditional search methods often fail to provide comprehensive and contextual results, particularly for unstructured data or complex queries.
One report shows that the number of annual data breaches increased around 60% between 2010 and 2021. There are a lot of benefits of using Security Information and Event Management (SIEM) systems to protect data from hackers. If the data is incomplete, additional information is sourced and appended (enrichment).
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content