This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This post is part of an ongoing series about governing the machine learning (ML) lifecycle at scale. This post dives deep into how to set up data governance at scale using Amazon DataZone for the data mesh. The data mesh is a modern approach to data management that decentralizes data ownership and treats data as a product.
Customers of every size and industry are innovating on AWS by infusing machine learning (ML) into their products and services. Recent developments in generative AI models have further sped up the need of ML adoption across industries.
After decades of digitizing everything in your enterprise, you may have an enormous amount of data, but with dormant value. However, with the help of AI and machine learning (ML), new software tools are now available to unearth the value of unstructured data. These services write the output to a datalake.
It’s been one decade since the “ BigData Era ” began (and to much acclaim!). Analysts asked, What if we could manage massive volumes and varieties of data? Yet the question remains: How much value have organizations derived from bigdata? BigData as an Enabler of Digital Transformation.
With that, the need for data scientists and machine learning (ML) engineers has grown significantly. Data scientists and ML engineers require capable tooling and sufficient compute for their work. Data scientists and ML engineers require capable tooling and sufficient compute for their work.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use data warehouses, datalakes, and analytics tools to load, transform, clean, and aggregate data. Choose Continue.
Real-Time ML with Spark and SBERT, AI Coding Assistants, DataLake Vendors, and ODSC East Highlights Getting Up to Speed on Real-Time Machine Learning with Spark and SBERT Learn more about real-time machine learning by using this approach that uses Apache Spark and SBERT. Well, these libraries will give you a solid start.
Companies are faced with the daunting task of ingesting all this data, cleansing it, and using it to provide outstanding customer experience. Typically, companies ingest data from multiple sources into their datalake to derive valuable insights from the data. Run the AWS Glue ML transform job.
Starting today, you can interactively prepare large datasets, create end-to-end data flows, and invoke automated machine learning (AutoML) experiments on petabytes of data—a substantial leap from the previous 5 GB limit. Organizations often struggle to extract meaningful insights and value from their ever-growing volume of data.
To make your data management processes easier, here’s a primer on datalakes, and our picks for a few datalake vendors worth considering. What is a datalake? First, a datalake is a centralized repository that allows users or an organization to store and analyze large volumes of data.
Amazon SageMaker enables enterprises to build, train, and deploy machine learning (ML) models. Amazon SageMaker JumpStart provides pre-trained models and data to help you get started with ML. MongoDB vector data store MongoDB Atlas Vector Search is a new feature that allows you to store and search vector data in MongoDB.
Amazon DataZone is a data management service that makes it quick and convenient to catalog, discover, share, and govern data stored in AWS, on-premises, and third-party sources. Enterprises can use no-code ML solutions to streamline their operations and optimize their decision-making without extensive administrative overhead.
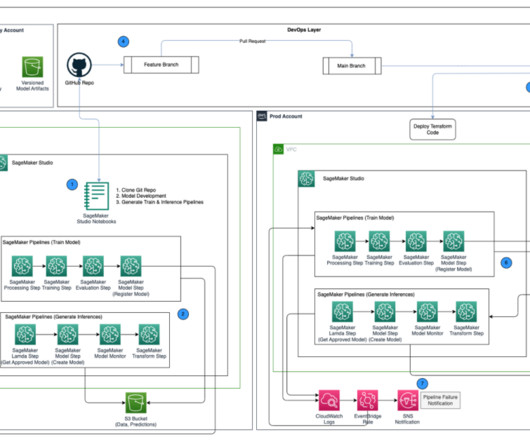
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications. The following diagram illustrates the solution architecture.
This post, part of the Governing the ML lifecycle at scale series ( Part 1 , Part 2 , Part 3 ), explains how to set up and govern a multi-account ML platform that addresses these challenges. An enterprise might have the following roles involved in the ML lifecycles. This ML platform provides several key benefits.
DVC Released in 2017, Data Version Control ( DVC for short) is an open-source tool created by iterative. DVC can be used for versioning data and models, to track experiments and compare any data, code, parameters models and graphical plots of performance. DVC can efficiently handle large files and machine learning models.
By running reports on historical data, a data warehouse can clarify what systems and processes are working and what methods need improvement. Data warehouse is the base architecture for artificial intelligence and machine learning (AI/ML) solutions as well. Modern data warehousing technology can handle all data forms.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
Just as a writer needs to know core skills like sentence structure, grammar, and so on, data scientists at all levels should know core data science skills like programming, computer science, algorithms, and so on. As MLOps become more relevant to ML demand for strong software architecture skills will increase as well.
A data lakehouse architecture combines the performance of data warehouses with the flexibility of datalakes, to address the challenges of today’s complex data landscape and scale AI. How does an open data lakehouse architecture support AI? All of this supports the use of AI.
In entered the BigData space in 2013 and continues to explore that area. He is actively working on projects in the ML space and has presented at numerous conferences including Strata and GlueCon. He is focused on BigData, DataLakes, Streaming and batch Analytics services and generative AI technologies.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and prepare data for machine learning (ML) from weeks to minutes. Data is frequently kept in datalakes that can be managed by AWS Lake Formation , giving you the ability to implement fine-grained access control using a straightforward grant or revoke procedure.
Amazon SageMaker Feature Store is a fully managed, purpose-built repository to store, share, and manage features for machine learning (ML) models. Features are inputs to ML models used during training and inference. SageMaker Feature Store now makes it effortless to share, discover, and access feature groups across AWS accounts.
We capitalized on the powerful tools provided by AWS to tackle this challenge and effectively navigate the complex field of machine learning (ML) and predictive analytics. SageMaker is a fully managed ML service. This was a crucial aspect in achieving agility in our operations and a seamless integration of our ML efforts.
Data storage databases. Your SaaS company can store and protect any amount of data using Amazon Simple Storage Service (S3), which is ideal for datalakes, cloud-native applications, and mobile apps. Well, let’s find out. Artificial intelligence (AI).
Previously, he was a Data & Machine Learning Engineer at AWS, where he worked closely with customers to develop enterprise-scale data infrastructure, including datalakes, analytics dashboards, and ETL pipelines.
By using these capabilities, businesses can efficiently store, manage, and analyze time-series data, enabling data-driven decisions and gaining a competitive edge. If you need an automated workflow or direct ML model integration into apps, Canvas forecasting functions are accessible through APIs.
On the client side, Snowpark consists of libraries, including the DataFrame API and native Snowpark machine learning (ML) APIs for model development (public preview) and deployment (private preview). The release of Snowpark makes our customers’ lives simpler by unifying their datalake into a complete data platform.
Real-time Analytics & Built-in Machine Learning Models with a Single Database Akmal Chaudhri, Senior Technical Evangelist at SingleStore, explores the importance of delivering real-time experiences in today’s bigdata industry and how data models and algorithms rely on powerful and versatile data infrastructure.
In entered the BigData space in 2013 and continues to explore that area. He is actively working on projects in the ML space and has presented at numerous conferences including Strata and GlueCon. Enterprise Solutions Architect at AWS, experienced in Software Engineering, Enterprise Architecture, and AI/ML.
Amazon Forecast is a fully managed service that uses machine learning (ML) algorithms to deliver highly accurate time series forecasts. Initially, daily forecasts for each country are formulated through ML models. These daily predictions are subsequently broken down into hourly segments, as depicted in the following graph.
Third, despite the larger adoption of centralized analytics solutions like datalakes and warehouses, complexity rises with different table names and other metadata that is required to create the SQL for the desired sources. About the Authors Sanjeeb Panda is a Data and ML engineer at Amazon.
Amazon Monitron is an end-to-end condition monitoring solution that enables you to start monitoring equipment health with the aid of machine learning (ML) in minutes, so you can implement predictive maintenance and reduce unplanned downtime. For the detailed Amazon Monitron installation guide, refer to Getting started with Amazon Monitron.
Time Series Forecasting for Managers — All Forecasts Are Wrong but Some Are Useful Tanvir Ahmed Shaikh | Data Strategist (Director) | Genentech, Inc Time series forecasting remains an under-appreciated technique in data science education, often overshadowed by more popular machine learning methods.
Machine learning (ML)—the artificial intelligence (AI) subfield in which machines learn from datasets and past experiences by recognizing patterns and generating predictions—is a $21 billion global industry projected to become a $209 billion industry by 2029. At Facebook Messenger, ML powers customer service chatbots.
We use data-specific preprocessing and ML algorithms suited to each modality to filter out noise and inconsistencies in unstructured data. NLP cleans and refines content for text data, while audio data benefits from signal processing to remove background noise. Tools like Unstructured.io
Building out a machine learning operations (MLOps) platform in the rapidly evolving landscape of artificial intelligence (AI) and machine learning (ML) for organizations is essential for seamlessly bridging the gap between data science experimentation and deployment while meeting the requirements around model performance, security, and compliance.
You’ll use MLRun, Langchain, and Milvus for this exercise and cover topics like the integration of AI/ML applications, leveraging Python SDKs, as well as building, testing, and tuning your work. In this session, we’ll demonstrate how you can fine-tune a Gen AI model, build a Gen AI application, and deploy it in 20 minutes.
Managing unstructured data is essential for the success of machine learning (ML) projects. Without structure, data is difficult to analyze and extracting meaningful insights and patterns is challenging. This article will discuss managing unstructured data for AI and ML projects. What is Unstructured Data?
Getir used Amazon Forecast , a fully managed service that uses machine learning (ML) algorithms to deliver highly accurate time series forecasts, to increase revenue by four percent and reduce waste cost by 50 percent. In this post, we describe how we used Forecast to achieve these benefits.
Data Wrangling: Data Quality, ETL, Databases, BigData The modern data analyst is expected to be able to source and retrieve their own data for analysis. Competence in data quality, databases, and ETL (Extract, Transform, Load) are essential.
Generative AI empowers organizations to combine their data with the power of machine learning (ML) algorithms to generate human-like content, streamline processes, and unlock innovation. After data is extracted, the job performs document chunking, data cleanup, and postprocessing.
And, as organizations progress and grow, “data drift” starts to impact data usage, models, and your business. In today’s AI/ML-driven world of data analytics, explainability needs a repository just as much as those doing the explaining need access to metadata, EG, information about the data being used.
To fully realize data’s value, organizations in the travel industry need to dismantle data silos so that they can securely and efficiently leverage analytics across their organizations. What is bigdata in the travel and tourism industry? Using Alation, ARC automated the data curation and cataloging process. “So
Amazon Kendra is an intelligent search service powered by machine learning (ML). Amazon Kendra supports a variety of document formats , such as Microsoft Word, PDF, and text from various data sources. Image captioning with GenAI Image description with GenAI involves using ML algorithms to generate textual descriptions of images.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content