This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the data-driven world […] The post Monitoring Data Quality for Your BigDataPipelines Made Easy appeared first on Analytics Vidhya. Determine success by the precision of your charts, the equipment’s dependability, and your crew’s expertise. A single mistake, glitch, or slip-up could endanger the trip.
In this sponsored post, Devika Garg, PhD, Senior Solutions Marketing Manager for Analytics at Pure Storage, believes that in the current era of data-driven transformation, IT leaders must embrace complexity by simplifying their analytics and data footprint.
.- Dale Carnegie” Apache Kafka is a Software Framework for storing, reading, and analyzing streaming data. The post Build a Simple Realtime DataPipeline appeared first on Analytics Vidhya. The Internet of Things(IoT) devices can generate a large […].
Business leaders are growing weary of making further investments in business intelligence (BI) and bigdata analytics. Beyond the challenging technical components of data-driven projects, BI and analytics services have yet to live up to the hype.
Over the last few years, with the rapid growth of data, pipeline, AI/ML, and analytics, DataOps has become a noteworthy piece of day-to-day business New-age technologies are almost entirely running the world today. Among these technologies, bigdata has gained significant traction. This concept is …
Bigdata is shaping our world in countless ways. Data powers everything we do. Exactly why, the systems have to ensure adequate, accurate and most importantly, consistent data flow between different systems. There are a number of challenges in data storage , which datapipelines can help address.
We can also use AI to perform lower-level software & data system functions that users will be mostly oblivious to to make make users' apps & services work correctly.
Datapipelines have been crucial for brands in a number of ways. In March, Hubspot talked about the shift towards incorporating bigdata into marketing pipelines in B2B campaigns. “A However, it is important to use the right datapipelines to leverage these benefits.
Using Iceberg allows us to pick the optimal "bigdata" compute environment for the specific requirements we have. There's no need to limit yourself to a single solution.
Bigdata has led to many important breakthroughs in the Fintech sector. And BigData is one such excellent opportunity ! BigData is the collection and processing of huge volumes of different data types, which financial institutions use to gain insights into their business processes and make key company decisions.
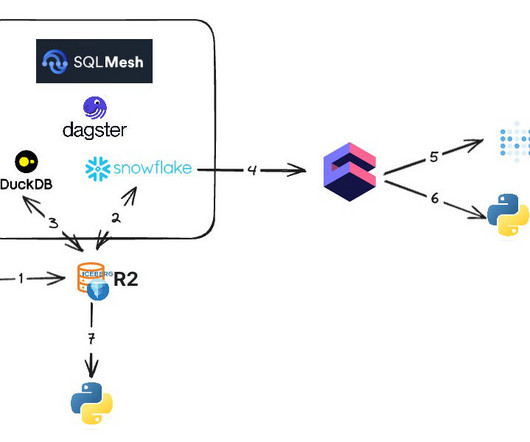
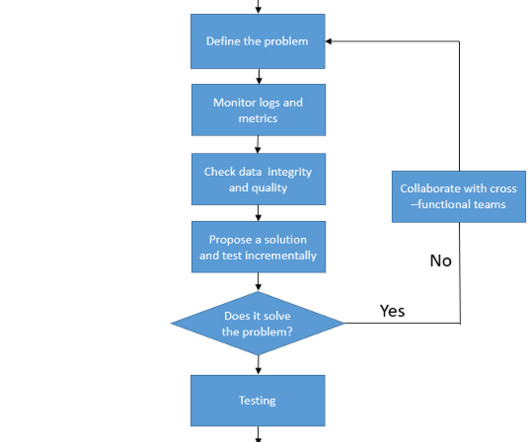
Bigdatapipelines are the backbone of modern data processing, enabling organizations to collect, process, and analyze vast amounts of data in real-time. Issues such as data inconsistencies, performance bottlenecks, and failures are inevitable.In Validate data format and schema compatibility.
A datapipeline is a technical system that automates the flow of data from one source to another. While it has many benefits, an error in the pipeline can cause serious disruptions to your business. Here are some of the best practices for preventing errors in your datapipeline: 1. Monitor Your Data Sources.
Amazon Kinesis is a platform to build pipelines for streaming data at the scale of terabytes per hour. The post Amazon Kinesis vs. Apache Kafka For BigData Analysis appeared first on Dataconomy. Parts of the Kinesis platform are.
Business success is based on how we use continuously changing data. That’s where streaming datapipelines come into play. This article explores what streaming datapipelines are, how they work, and how to build this datapipeline architecture. What is a streaming datapipeline?
Data engineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. It integrates seamlessly with other AWS services and supports various data integration and transformation workflows.
Data engineers play a crucial role in managing and processing bigdata. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. They must also ensure that data privacy regulations, such as GDPR and CCPA , are followed.
Driven by significant advancements in computing technology, everything from mobile phones to smart appliances to mass transit systems generate and digest data, creating a bigdata landscape that forward-thinking enterprises can leverage to drive innovation. However, the bigdata landscape is just that.
With the advent of bigdata in the modern world, RTOS is becoming increasingly important. As software expert Tim Mangan explains, a purpose-built real-time OS is more suitable for apps that involve tons of data processing. The BigData and RTOS connection IoT and embedded devices are among the biggest sources of bigdata.
It was only a few years ago that BI and data experts excitedly claimed that petabytes of unstructured data could be brought under control with datapipelines and orderly, efficient data warehouses. But as bigdata continued to grow and the amount of stored information increased every […].
With the explosive growth of bigdata over the past decade and the daily surge in data volumes, it’s essential to have a resilient system to manage the vast influx of information without failures. The success of any data initiative hinges on the robustness and flexibility of its bigdatapipeline.
“Data is at the center of every application, process, and business decision,” wrote Swami Sivasubramanian, VP of Database, Analytics, and Machine Learning at AWS, and I couldn’t agree more. A common pattern customers use today is to build datapipelines to move data from Amazon Aurora to Amazon Redshift.
Summary: This article provides a comprehensive guide on BigData interview questions, covering beginner to advanced topics. Introduction BigData continues transforming industries, making it a vital asset in 2025. The global BigData Analytics market, valued at $307.51 What is BigData?
A data fabric is textured approach to combining disparate data sources, datapipelines, databases, data streams and cloud data services into one woven unified entity.
While there is a lot of discussion about the merits of data warehouses, not enough discussion centers around data lakes. We talked about enterprise data warehouses in the past, so let’s contrast them with data lakes. Both data warehouses and data lakes are used when storing bigdata.
Summary: “Data Science in a Cloud World” highlights how cloud computing transforms Data Science by providing scalable, cost-effective solutions for bigdata, Machine Learning, and real-time analytics. This accessibility democratises Data Science, making it available to businesses of all sizes.
Optimized for analytical processing, it uses specialized data models to enhance query performance and is often integrated with business intelligence tools, allowing users to create reports and visualizations that inform organizational strategies. architecture for both structured and unstructured data.
Summary: BigData revolutionises promotional strategies by enabling personalised, data-driven marketing campaigns. Businesses leveraging BigData effectively gain a competitive edge in connecting with audiences and optimising campaign performance while fostering trust through responsible data use.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Choose Delete stack.
Bigdata engineer Potential pay range – US$206,000 to 296,000/yr They operate at the backend to build and maintain complex systems that store and process the vast amounts of data that fuel AI applications. With the growing amount of data for businesses, the demand for bigdata engineers is only bound to grow in 2024.
What businesses need from cloud computing is the power to work on their data without having to transport it around between different clouds, different databases and different repositories, different integrations to third-party applications, different datapipelines and different compute engines.
While growing data enables companies to set baselines, benchmarks, and targets to keep moving ahead, it poses a question as to what actually causes it and what it means to your organization’s engineering team efficiency. What’s causing the data explosion? Bigdata analytics from 2022 show a dramatic surge in information consumption.
It seems straightforward at first for batch data, but the engineering gets even more complicated when you need to go from batch data to incorporating real-time and streaming data sources, and from batch inference to real-time serving. Without the capabilities of Tecton , the architecture might look like the following diagram.
A lot of Open-Source ETL tools house a graphical interface for executing and designing DataPipelines. It can be used to manipulate, store, and analyze data of any structure. It generates Java code for the DataPipelines instead of running Pipeline configurations through an ETL Engine.
These massive storage pools of data are among the most non-traditional methods of data storage around and they came about as companies raced to embrace the trend of BigData Analytics which was sweeping the world in the early 2010s. BigData is, well…big.
The amount of the data that we process every day and make available for researchers in a timely fashion makes it a very complex and really bigdata problem,” said Jay Nanduri , Truveta chief technology officer, in an interview with GeekWire. The Truveta datapipeline. The company also updates its datasets daily.
Experts in data science are needed in all kinds of industries, from companies developing dating apps to government security. Businesses and organizations of all kinds rely on bigdata to find solutions to problems and provide better services, so there are lots of different types of careers you could pursue with a degree in data science.
Datapipelines In cases where you need to provide contextual data to the foundation model using the RAG pattern, you need a datapipeline that can ingest the source data, convert it to embedding vectors, and store the embedding vectors in a vector database.
Working with massive structured and unstructured data sets can turn out to be complicated. It’s obvious that you’ll want to use bigdata, but it’s not so obvious how you’re going to work with it. So, let’s have a close look at some of the best strategies to work with large data sets.
If the data sources are additionally expanded to include the machines of production and logistics, much more in-depth analyses for error detection and prevention as well as for optimizing the factory in its dynamic environment become possible.
BigData As datasets become larger and more complex, knowing how to work with them will be key. Bigdata isn’t an abstract concept anymore, as so much data comes from social media, healthcare data, and customer records, so knowing how to parse all of that is needed.
Rajesh Nedunuri is a Senior Data Engineer within the Amazon Worldwide Returns and ReCommerce Data Services team. He specializes in designing, building, and optimizing large-scale data solutions.
The primary goal of Data Engineering is to transform raw data into a structured and usable format that can be easily accessed, analyzed, and interpreted by Data Scientists, analysts, and other stakeholders. Future of Data Engineering The Data Engineering market will expand from $18.2
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content