This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Data science has taken over all economic sectors in recent times. To achieve maximum efficiency, every company strives to use various data at every stage of its operations.
It is intended to assist organizations in simplifying the bigdata and analytics process by providing a consistent experience for datapreparation, administration, and discovery. Introduction Microsoft Azure Synapse Analytics is a robust cloud-based analytics solution offered as part of the Azure platform.
Alonside data management frameworks, a holistic approach to data engineering for AI is needed along with data provenance controls and datapreparation tools.
Datapreparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive datapreparation capabilities powered by Amazon SageMaker Data Wrangler. Within the data flow, add an Amazon S3 destination node.
Driven by significant advancements in computing technology, everything from mobile phones to smart appliances to mass transit systems generate and digest data, creating a bigdata landscape that forward-thinking enterprises can leverage to drive innovation. However, the bigdata landscape is just that.
today announced that NVIDIA CUDA-X™ data processing libraries will be integrated with HP AI workstation solutions to turbocharge the datapreparation and processing work that forms the foundation of generative AI development. HP Amplify — NVIDIA and HP Inc.
Bigdata and data science in the digital age The digital age has resulted in the generation of enormous amounts of data daily, ranging from social media interactions to online shopping habits. quintillion bytes of data are created. It is estimated that every day, 2.5
Users: data scientists vs business professionals People who are not used to working with raw data frequently find it challenging to explore data lakes. To comprehend and transform raw, unstructured data for any specific business use, it typically takes a data scientist and specialized tools.
Importing data from the SageMaker Data Wrangler flow allows you to interact with a sample of the data before scaling the datapreparation flow to the full dataset. This improves time and performance because you don’t need to work with the entirety of the data during preparation.
Bigdata processing With the increasing volume of data, bigdata technologies have become indispensable for Applied Data Science. CRISP-DM methodology Cross-Industry Standard Process for Data Mining (CRISP-DM) is a commonly used methodology in Applied Data Science.
Predictive analytics, sometimes referred to as bigdata analytics, relies on aspects of data mining as well as algorithms to develop predictive models. These predictive models can be used by enterprise marketers to more effectively develop predictions of future user behaviors based on the sourced historical data.
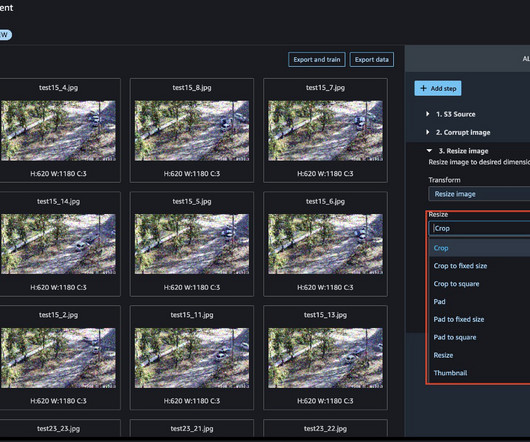
Today, we are happy to announce that with Amazon SageMaker Data Wrangler , you can perform image datapreparation for machine learning (ML) using little to no code. Data Wrangler reduces the time it takes to aggregate and preparedata for ML from weeks to minutes. Choose Import. This can take a few minutes.
Harnessing the power of bigdata has become increasingly critical for businesses looking to gain a competitive edge. However, managing the complex infrastructure required for bigdata workloads has traditionally been a significant challenge, often requiring specialized expertise.
What they’re testing: Basic datapreparation awareness as it relates to visualization. Sample Answer: “First, I’d try to understand why the data is missing is it random, or is there a pattern? The approach depends on the context and the amount of missing data. How would you approach this?
With SageMaker Unified Studio notebooks, you can use Python or Spark to interactively explore and visualize data, preparedata for analytics and ML, and train ML models. With the SQL editor, you can query data lakes, databases, data warehouses, and federated data sources. BigData Architect.
Data Storage and Management Once data have been collected from the sources, they must be secured and made accessible. The responsibilities of this phase can be handled with traditional databases (MySQL, PostgreSQL), cloud storage (AWS S3, Google Cloud Storage), and bigdata frameworks (Hadoop, Apache Spark).
For a comprehensive understanding of the practical applications, including a detailed code walkthrough from datapreparation to model deployment, please join us at the ODSC APAC conference 2023. We have a number of records, each with A target (or label ) column, dessert, containing a binary input (1.0 if the recipe is a dessert, 0.0
Choose Data Wrangler in the navigation pane. On the Import and prepare dropdown menu, choose Tabular. You can review the generated Data Quality and Insights Report to gain a deeper understanding of the data, including statistics, duplicates, anomalies, missing values, outliers, target leakage, data imbalance, and more.
Datapreparation is important at multiple stages in Retrieval Augmented Generation ( RAG ) models. Create a dataflow Complete the following steps to create a data flow in SageMaker Canvas: On the SageMaker Canvas home page, choose Datapreparation. This will land on a data flow page. Choose your domain.
The Women in BigData (WiBD) and DataCamp Donates monthly Zoom Info-Session took place last Friday. Introduction The zoom meeting started with a warm welcome by Srabasti Banerjee , and a brief introduction to the world of Women in BigData by Shala Arshi. It was really neat. Link to the recording.
Data Wrangler enables you to access data from a wide variety of popular sources ( Amazon S3 , Amazon Athena , Amazon Redshift , Amazon EMR and Snowflake) and over 40 other third-party sources. Starting today, you can connect to Amazon EMR Hive as a bigdata query engine to bring in large datasets for ML.
The vendors evaluated for this MarketScape offer various software tools needed to support end-to-end machine learning (ML) model development, including datapreparation, model building and training, model operation, evaluation, deployment, and monitoring.
Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machine learning (ML), retail, and data and analytics. You can import data from multiple data sources, such as Amazon Simple Storage Service (Amazon S3), Amazon Athena , Amazon Redshift , Amazon EMR , and Snowflake.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and preparedata for machine learning (ML) from weeks to minutes. We are happy to announce that SageMaker Data Wrangler now supports using Lake Formation with Amazon EMR to provide this fine-grained data access restriction.
SageMaker Data Wrangler has also been integrated into SageMaker Canvas, reducing the time it takes to import, prepare, transform, featurize, and analyze data. In a single visual interface, you can complete each step of a datapreparation workflow: data selection, cleansing, exploration, visualization, and processing.
Datapreparation For this example, you will use the South German Credit dataset open source dataset. After you have completed the datapreparation step, it’s time to train the classification model. An experiment collects multiple runs with the same objective.
Information – data that’s processed, organized, and consumable – drives insights that lead to actions and value generation. This article shares my experience in data analytics and digital tool implementation, focusing on leveraging “BigData” to create actionable insights.
Datapreparation and training The datapreparation and training pipeline includes the following steps: The training data is read from a PrestoDB instance, and any feature engineering needed is done as part of the SQL queries run in PrestoDB at retrieval time.
It was only a few years ago that BI and data experts excitedly claimed that petabytes of unstructured data could be brought under control with data pipelines and orderly, efficient data warehouses. But as bigdata continued to grow and the amount of stored information increased every […].
While both these tools are powerful on their own, their combined strength offers a comprehensive solution for data analytics. In this blog post, we will show you how to leverage KNIME’s Tableau Integration Extension and discuss the benefits of using KNIME for datapreparation before visualization in Tableau.
The Right Use of Tools To Deal With Data. Business teams significantly rely upon data for self-service tools and more. Businesses will need to opt for datapreparation and analytics tasks, ranging from finance to marketing. Therefore, businesses use tools that will ease the process to get the right data.
This feature helps automate many parts of the datapreparation and data model development process. This significantly reduces the amount of time needed to engage in data science tasks. A text analytics interface that helps derive actionable insights from unstructured data sets.
Everyday AI is a core concept of Dataiku, where the systematic use of data for everyday operations makes businesses competent to succeed in competitive markets. Dataiku helps its customers at every stage, from datapreparation to analytics applications, to implement a data-driven model and make better decisions.
The Women in BigData (WiBD) Spring Hackathon 2024, organized by WiDS and led by WiBD’s Global Hackathon Director Rupa Gangatirkar , sponsored by Gilead Sciences, offered an exciting opportunity to sharpen data science skills while addressing critical social impact challenges.
Data Science for Business” by Foster Provost and Tom Fawcett This book bridges the gap between Data Science and business needs. It covers Data Engineering aspects like datapreparation, integration, and quality. Ideal for beginners, it illustrates how Data Engineering aligns with business applications.
Organizations across the world are striving to be data-driven and use data more effectively to inform decision-making at every level of the business. However, according to the 2021 BigData and AI Executive Survey from NewVantage Partners, only 40% of companies today manage their data as if it were a business asset.
There has been an explosion of data, from social and mobile data to bigdata, that is fueling new ways to understand and improve customer experience. We are entering an era of self-service analytics.
This brief definition makes several points about data catalogs—data management, searching, data inventory, and data evaluation—but all depend on the central capability to provide a collection of metadata. Data catalogs have become the standard for metadata management in the age of bigdata and self-service analytics.
This practice vastly enhances the speed of my datapreparation for machine learning projects. This is the first one, where we look at some functions for data quality checks, which are the initial steps I take in EDA. within each project folder. Let’s get started. 🤠 🔗 All code and config are available on GitHub.
Amidst all the new developments, data bricks have emerged as a unified analytics platform. What is Databricks? It is a unified analytics platform that simplifies building bigdata and AI solutions. It brings together Data Engineering, Data Science, and Data Analytics.
Using the BMW data portal, users can request access to on-premises databases or data stored in BMW’s Cloud Data Hub, making it available in their workspace for development and experimentation, from datapreparation and analysis to model training and validation.
We create a custom training container that downloads data directly from the Snowflake table into the training instance rather than first downloading the data into an S3 bucket. Previously, he was a software solutions architect for deep learning, analytics, and bigdata technologies at Intel.
As bigdata matures, the way you think about it may have to shift also. It’s no longer enough to build the data warehouse. Dave Wells, analyst with the Eckerson Group suggests that realizing the promise of the data warehouse requires a paradigm shift in the way we think about data along with a change in how we access and use it.
More recently, we’ve seen Extract, Transform and Load (ETL) tools like Informatica and IBM Datastage disrupted by self-service datapreparation tools. Given the explosion of data, the explosion of tools, and the massive demand for data, there’s no way that IT could keep up with the massive demands for clean, prepareddata.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content