This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary: A comprehensive BigData syllabus encompasses foundational concepts, essential technologies, data collection and storage methods, processing and analysis techniques, and visualisation strategies. Fundamentals of BigData Understanding the fundamentals of BigData is crucial for anyone entering this field.
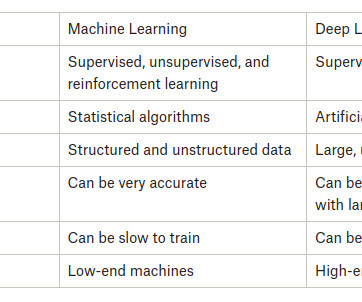
While data science and machine learning are related, they are very different fields. In a nutshell, data science brings structure to bigdata while machine learning focuses on learning from the data itself. What is data science? This post will dive deeper into the nuances of each field.
These algorithms are carefully selected based on the specific decision problem and are trained using the prepared data. Machine learning algorithms, such as neural networks or decisiontrees, learn from the data to make predictions or generate recommendations.
Several algorithms are available, including decisiontrees, neural networks, and supportvectormachines. Train the AI system: Use the collected data to train the AI system. This involves feeding the algorithm with data and tweaking it to improve its accuracy.
Machine Learning Algorithms Candidates should demonstrate proficiency in a variety of Machine Learning algorithms, including linear regression, logistic regression, decisiontrees, random forests, supportvectormachines, and neural networks.
Machine Learning and Neural Networks (1990s-2000s): Machine Learning (ML) became a focal point, enabling systems to learn from data and improve performance without explicit programming. Techniques such as decisiontrees, supportvectormachines, and neural networks gained popularity.
Association Rule Learning: A rule-based Machine Learning method to discover interesting relationships between variables in large databases. B BigData : Large datasets characterised by high volume, velocity, variety, and veracity, requiring specialised techniques and technologies for analysis.
Explore Machine Learning with Python: Become familiar with prominent Python artificial intelligence libraries such as sci-kit-learn and TensorFlow. Begin by employing algorithms for supervised learning such as linear regression , logistic regression, decisiontrees, and supportvectormachines.
DecisionTrees These trees split data into branches based on feature values, providing clear decision rules. SupportVectorMachines (SVM) SVMs are powerful classifiers that separate data into distinct categories by finding an optimal hyperplane.
Model Complexity Machine Learning : Traditional machine learning models have fewer parameters and a simpler structure than deep learning models. They typically rely on simpler algorithms like decisiontrees, supportvectormachines, or linear regression.
Overfitting: The model performs well only for the sample training data. If any new data is given as input to the model, it fails to provide any result. Decisiontrees are more prone to overfitting. Some algorithms that have low bias are DecisionTrees, SVM, etc. Variance: Variance is also a kind of error.
Scala is worth knowing if youre looking to branch into data engineering and working with bigdata more as its helpful for scaling applications. Data Engineering Data engineering remains integral to many data science roles, with workflow pipelines being a key focus.
Several technologies bridge the gap between AI and Data Science: Machine Learning (ML): ML algorithms, like regression and classification, enable machines to learn from data, enhancing predictive accuracy. BigData: Large datasets fuel AI and Data Science, providing the raw material for analysis and model training.
Develop Hybrid Models Combine traditional analytical methods with modern algorithms such as decisiontrees, neural networks, and supportvectormachines. Clustering algorithms, such as k-means, group similar data points, and regression models predict trends based on historical data.
This capability bridges various disciplines, leveraging techniques from statistics, machine learning, and artificial intelligence. Some key areas include: BigData analytics: It helps in interpreting vast amounts of data to extract meaningful insights.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content