This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the era of bigdata and rapid technological advancement, the ability to analyze and interpret data effectively has become a cornerstone of decision-making and innovation. Python, renowned for its simplicity and versatility, has emerged as the leading programming language for data analysis.
Introduction In the realm of BigData, professionals are expected to navigate complex landscapes involving vast datasets, distributed systems, and specialized tools.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Bigdata is the collection of data that is vast. The post Integration of Python with Hadoop and Spark appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction In today’s era of Bigdata and IoT, we are easily. The post A comprehensive guide to Feature Selection using Wrapper methods in Python appeared first on Analytics Vidhya.
The post Relationship Between Facebook and BigData appeared first on Analytics Vidhya. Introduction Source – Unsplash You must often receive birthday notifications from Facebook, like “Amit Pathak and 4 others have their birthday today” What is so special about this notification?
Introduction In the last article, we discussed Apache Spark and the bigdata ecosystem, and we discussed the role of apache spark in data processing in bigdata. The post Learn About Apache Spark Using Python appeared first on Analytics Vidhya. If you haven’t read it yet, you can find it on this page.
Introduction Apache Spark is a powerful bigdata processing engine that has gained widespread popularity recently due to its ability to process massive amounts of data types quickly and efficiently. While Spark can be used with several programming languages, Python and Scala are popular for building Spark applications.
Introduction In this article, we are going to cover Spark SQL in Python. In the last article, we have already introduced Spark and its work and its role in Bigdata. The post End-to-End Beginners Guide on Spark SQL in Python appeared first on Analytics Vidhya. If you haven’t checked it yet, please go to this link.
In the data-driven world […] The post Monitoring Data Quality for Your BigData Pipelines Made Easy appeared first on Analytics Vidhya. Determine success by the precision of your charts, the equipment’s dependability, and your crew’s expertise. A single mistake, glitch, or slip-up could endanger the trip.
This article was published as a part of the Data Science Blogathon. Introduction to BigData File Formats In the digital era, every day we generate thousands of terabytes of data. The most challenging task is to store and process this data.
ArticleVideo Book This article was published as a part of the Data Science Blogathon. In the era of BigData, Python has become the. The post A beginners guide to Multi-Processing in Python appeared first on Analytics Vidhya.
Introduction A couple of months ago a client of mine asked me the following question: “What is the faster data structure object in Python for BigData analysis today?” The post High Performance BigData Analysis Using NumPy, Numba & Python Asynchronous Programming appeared first on Dataconomy.
Overview BigData is becoming bigger by the day, and at an unprecedented pace How do you store, process and use this amount of. The post PySpark for Beginners – Take your First Steps into BigData Analytics (with Code) appeared first on Analytics Vidhya.
Overview A demonstration of statistical analytics by Integrating Python within Power BI Share the findings using dashboards and reports Introduction Power BI is. The post Integrating Python in Power BI: Get the best of both worlds appeared first on Analytics Vidhya.
Overview MongoDB is a popular unstructured database that data scientists should be aware of We will discuss how you can work with a MongoDB. The post MongoDB in Python Tutorial for Beginners (using PyMongo) appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction to Pyspark Spark is an open-source framework for bigdata processing. It was originally written in scala and later on due to increasing demand for machine learning using bigdata a python API of the same was released.
Ramapo College’s Master of Science in Data Science program will teach you to collect, synthesize, and analyze bigdata, become skilled in programming languages like R and Python, and leverage advanced tools to meet the demands of modern business and science.
Explore essential tools and skills for AI engineers: Python, R, bigdata frameworks, and cloud services essential for building and optimizing AI systems.
The generation and accumulation of vast amounts of data have become a defining characteristic of our world. This data, often referred to as BigData , encompasses information from various sources, including social media interactions, online transactions, sensor data, and more. databases), semi-structured data (e.g.,
SQream, the scalable GPU data analytics platform, announced a strategic integration with Dataiku, the platform for everyday AI. This collaboration brings together SQream’s best-in-class bigdata analytics technology with Dataiku’s flexible and scalable data science and machine learning (ML) platform.
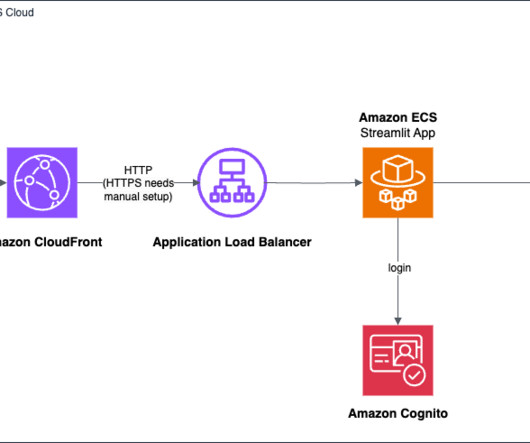
In this post, we explore a practical solution that uses Streamlit , a Python library for building interactive data applications, and AWS services like Amazon Elastic Container Service (Amazon ECS), Amazon Cognito , and the AWS Cloud Development Kit (AWS CDK) to create a user-friendly generative AI application with authentication and deployment.
Bigdata engineers are essential in today’s data-driven landscape, transforming vast amounts of information into valuable insights. As businesses increasingly depend on bigdata to tailor their strategies and enhance decision-making, the role of these engineers becomes more crucial.
Apache Spark is one of the hottest and largest open source project in data processing framework with rich high-level APIs for the programming languages like Scala, Python, Java and R. It realizes the potential of bringing together both BigData and machine learning.
Summary: BigData refers to the vast volumes of structured and unstructured data generated at high speed, requiring specialized tools for storage and processing. Data Science, on the other hand, uses scientific methods and algorithms to analyses this data, extract insights, and inform decisions.
This article was published as a part of the Data Science Blogathon. Introduction In this article, we will introduce you to the bigdata ecosystem and the role of Apache Spark in Bigdata. We will also cover the Distributed database system, the backbone of bigdata. In today’s world, data is the fuel.
Strong analytical skills and the ability to work with large datasets are critical, as is familiarity with data modeling and ETL processes. Additionally, knowledge of programming languages like Python or R can be beneficial for advanced analytics. Prepare to discuss your experience and problem-solving abilities with these languages.
Introduction Since the 1970s, relational database management systems have solved the problems of storing and maintaining large volumes of structured data. With the advent of bigdata, several organizations realized the benefits of bigdata processing and started choosing solutions like Hadoop to […].
One of the fields of professionals that are so important for data science projects are Python developers. What is the Python programming language? Why is it so important in the data science profession ? What Is Python? Python is a powerful programming language that is widely used in many different industries today.
This article was published as a part of the Data Science Blogathon. Introduction In this article, we will introduce you to Apache Spark and its role in bigdata and the way it makes a bigdata ecosystem we will also explore Resilient Distributed Dataset (RDD) in spark. As we all have seen the growth of […].
Introduction With the increasing use of technology, data accumulation is faster than ever due to connected smart devices. These devices continuously collect and transmit data that can be processed, transformed, and stored for later use. This collected data, known as bigdata, holds valuable […].
Introduction Data science is one of the professions in high demand nowadays due to the growing focus on analyzing bigdata. Hypothesis and conclusion-making from data broadly involve technical and non-technical skills in the interdisciplinary field of data science.
This article was published as a part of the Data Science Blogathon Introduction Apache Spark is a bigdata processing framework that has long become one of the most popular and frequently encountered in all kinds of projects related to BigData.
Introduction to ETL ETL is a type of three-step data integration: Extraction, Transformation, Load are processing, used to combine data from multiple sources. It is commonly used to build BigData. In this process, data is pulled (extracted) from a source system, to […].
Summary: Python for Data Science is crucial for efficiently analysing large datasets. With numerous resources available, mastering Python opens up exciting career opportunities. Introduction Python for Data Science has emerged as a pivotal tool in the data-driven world. in 2022, according to the PYPL Index.
Introduction The field of data science is evolving rapidly, and staying ahead of the curve requires leveraging the latest and most powerful tools available. In 2024, data scientists have a plethora of options to choose from, catering to various aspects of their work, including programming, bigdata, AI, visualization, and more.
Corporations across all industries have invested significantly in bigdata, establishing analytics departments, particularly in telecommunications, insurance, advertising, financial services, healthcare, and technology. The post Step-by-Step Guide to Becoming a Data Analyst in 2023 appeared first on Analytics Vidhya.
Today, we navigate a landscape dominated by code, algorithms, and digital streams of data, a far cry from those early days. Yet, despite these transformative changes, the […] The post From Parchment to Python: How Smart Data Evolved to What It Is Today appeared first on DATAVERSITY.
The data science lifecycle is designed for bigdata issues and data science projects. Generally, the data science project consists of seven steps which. The post The Lifecycle to Build a Web Application for Prediction from Scratch appeared first on Analytics Vidhya.
Introduction In bigdata and advanced analytics, PySpark has emerged as a powerful tool for processing large datasets and analyzing distributed data. Deploying PySpark on AWS applications on the cloud can be a game-changer, offering scalability and flexibility for data-intensive tasks.
This article was published as a part of the Data Science Blogathon. Introduction on Apache Hive Advanced bigdata tools must handle the massive amounts of structured and unstructured data generated daily. Data is not increasing only in terms of volume, but the variety and veracity of data are also growing.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content