This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
BigData tauchte als Buzzword meiner Recherche nach erstmals um das Jahr 2011 relevant in den Medien auf. BigData wurde zum Business-Sprech der darauffolgenden Jahre. In der Parallelwelt der ITler wurde das Tool und Ökosystem Apache Hadoop quasi mit BigData beinahe synonym gesetzt.
1, Data is the new oil, but labeled data might be closer to it Even though we have been in the 3rd AI boom and machine learning is showing concrete effectiveness at a commercial level, after the first two AI booms we are facing a problem: lack of labeled data or data themselves.
Summary: A comprehensive BigData syllabus encompasses foundational concepts, essential technologies, data collection and storage methods, processing and analysis techniques, and visualisation strategies. Fundamentals of BigData Understanding the fundamentals of BigData is crucial for anyone entering this field.
NOTES, DEEP LEARNING, REMOTE SENSING, ADVANCED METHODS, SELF-SUPERVISEDLEARNING A note of the paper I have read Photo by Kelly Sikkema on Unsplash Hi everyone, In today’s story, I would share notes I took from 32 pages of Wang et al., Taxonomy of the self-supervisedlearning Wang et al. 2022’s paper.
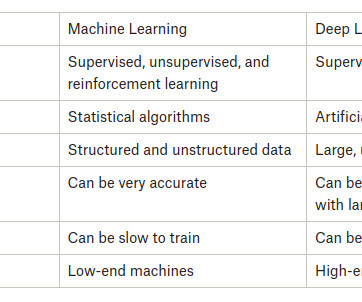
Learning the various categories of machine learning, associated algorithms, and their performance parameters is the first step of machine learning. Machine learning is broadly classified into three types – Supervised. In supervisedlearning, a variable is predicted. Semi-SupervisedLearning.
This automation not only increases efficiency but also enhances the accuracy of data interpretation, allowing organisations to focus on more strategic tasks. Scalability Machine Learning techniques are designed to handle vast amounts of data, making them well-suited for bigdata applications.
Here are three critical areas worth exploring: Machine Learning, Data Visualisation, and BigData. Machine Learning with Python Machine Learning is a vital component of Data Science, enabling systems to learn from data and make predictions.
There are various types of machine learning algorithms, including supervisedlearning, unsupervised learning, and reinforcement learning. In supervisedlearning, the model learns from labeled examples, where the input data is paired with corresponding target labels.
Our focus will be hands-on, with an emphasis on the practical application and understanding of essential machine learning concepts. Attendees will be introduced to a variety of machine learning algorithms, placing a spotlight on logistic regression, a potent supervisedlearning technique for solving binary classification problems.
Empowering Startups and Entrepreneurs | InvestBegin.com | investbegin The success of ChatGPT can be attributed to several key factors, including advancements in machine learning, natural language processing, and bigdata.
This technology allows computers to learn from historical data, identify patterns, and make data-driven decisions without explicit programming. Unsupervised learning algorithms Unsupervised learning algorithms are a vital part of Machine Learning, used to uncover patterns and insights from unlabeled data.
The Bay Area Chapter of Women in BigData (WiBD) hosted its second successful episode on the NLP (Natural Language Processing), Tools, Technologies and Career opportunities. Soumya introduced the Women in BigData organization and its mission to the audience. The event was part of the chapter’s technical talk series 2023.
While data science and machine learning are related, they are very different fields. In a nutshell, data science brings structure to bigdata while machine learning focuses on learning from the data itself. What is data science? This post will dive deeper into the nuances of each field.
A sector that is currently being influenced by machine learning is the geospatial sector, through well-crafted algorithms that improve data analysis through mapping techniques such as image classification, object detection, spatial clustering, and predictive modeling, revolutionizing how we understand and interact with geographic information.
Given the availability of diverse data sources at this juncture, employing the CNN-QR algorithm facilitated the integration of various features, operating within a supervisedlearning framework. Utilizing Forecast proved effective due to the simplicity of providing the requisite data and specifying the forecast duration.
These techniques span different types of learning and provide powerful tools to solve complex real-world problems. SupervisedLearningSupervisedlearning is one of the most common types of Machine Learning, where the algorithm is trained using labelled data.
Alternatively, they might use labels, such as “pizza,” “burger” or “taco” to streamline the learning process through supervisedlearning. It can ingest unstructured data in its raw form (e.g., It can ingest unstructured data in its raw form (e.g.,
We thought we’d structure this more as a conversation where we walk you through some of our thinking around some of the most common themes in data centricity in applied AI. Is more data always better? And the important thing here is really the predictive signal in the data. Maybe I’ll start us off here Robert? AR : Yeah.
We thought we’d structure this more as a conversation where we walk you through some of our thinking around some of the most common themes in data centricity in applied AI. Is more data always better? And the important thing here is really the predictive signal in the data. Maybe I’ll start us off here Robert? AR : Yeah.
We thought we’d structure this more as a conversation where we walk you through some of our thinking around some of the most common themes in data centricity in applied AI. Is more data always better? And the important thing here is really the predictive signal in the data. Maybe I’ll start us off here Robert? AR : Yeah.
This theorem is crucial in inferential statistics as it allows us to make inferences about the population parameters based on sample data. Differentiate between supervised and unsupervised learning algorithms. What is the Central Limit Theorem, and why is it important in statistics?
As AI adoption continues to accelerate, developing efficient mechanisms for digesting and learning from unstructured data becomes even more critical in the future. This could involve better preprocessing tools, semi-supervisedlearning techniques, and advances in natural language processing.
Read More: BigData and Artificial Intelligence: How They Work Together? Deep Learning (DL) is a more advanced technique within Machine Learning that uses artificial neural networks with multiple layers to learn from and make predictions based on data.
Machine learning encompasses several strategies that teach algorithms to recognize patterns in data, guiding informed actions in similar settings. These strategies include: SupervisedLearning: In this approach, data scientists provide ML systems with training data sets containing inputs and corresponding desired outputs.
e) BigData Analytics: The exponential growth of biological data presents challenges in storing, processing, and analyzing large-scale datasets. Traditional computational infrastructure may not be sufficient to handle the vast amounts of data generated by high-throughput technologies.
Association Rule Learning: A rule-based Machine Learning method to discover interesting relationships between variables in large databases. B BigData : Large datasets characterised by high volume, velocity, variety, and veracity, requiring specialised techniques and technologies for analysis.
In our example, we used unsupervised learning and a custom scoring function calculated by the query engine to fine-tune the results. Such scoring function can be added to any ML pipeline, including supervisedlearning in which you can add it as another metric to common metrics like AUC or accuracy.
Explore Machine Learning with Python: Become familiar with prominent Python artificial intelligence libraries such as sci-kit-learn and TensorFlow. Begin by employing algorithms for supervisedlearning such as linear regression , logistic regression, decision trees, and support vector machines.
The model was fine-tuned to reduce false, harmful, or biased output using a combination of supervisedlearning in conjunction to what OpenAI calls Reinforcement Learning with Human Feedback (RLHF), where humans rank potential outputs and a reinforcement learning algorithm rewards the model for generating outputs like those that rank highly.
In addition to incorporating all the fundamentals of Data Science, this Data Science program for working professionals also includes practical applications and real-world case studies. Additionally, it involves learning the mathematical and computational tools that form the core of Data Science.
MicroMasters Program in Statistics and Data Science MIT – edX 1 year 2 months (INR 1,11,739) This program integrates Data Science, Statistics, and Machine Learning basics. It emphasises probabilistic modeling and Statistical inference for analysing bigdata and extracting information.
Thus, complex multivariate data sequences can be accurately modeled, and the a need to establish pre-specified time windows (which solves many tasks that feed-forward networks cannot solve). The downside of overly time-consuming supervisedlearning, however, remains. In its core, lie gradient-boosted decision trees.
This metadata will help make the data labelling, feature extraction, and model training processes smoother and easier. These processes are essential in AI-based bigdata analytics and decision-making. Data Lakes Data lakes are crucial in effectively handling unstructured data for AI applications.
Instead of memorizing the training data, the objective is to create models that precisely predict unobserved instances. Supervised, unsupervised, and reinforcement learning : Machine learning can be categorized into different types based on the learning approach.
So, if you are eyeing your career in the data domain, this blog will take you through some of the best colleges for Data Science in India. There is a growing demand for employees with digital skills The world is drifting towards data-based decision making In India, a technology analyst can make between ₹ 5.5 Lakhs to ₹ 11.0
Machine learning is a subset of artificial intelligence that enables computers to learn from data and improve over time without being explicitly programmed. Explain the difference between supervised and unsupervised learning. In traditional programming, the programmer explicitly defines the rules and logic.
Several technologies bridge the gap between AI and Data Science: Machine Learning (ML): ML algorithms, like regression and classification, enable machines to learn from data, enhancing predictive accuracy. BigData: Large datasets fuel AI and Data Science, providing the raw material for analysis and model training.
Large language models A large language model refers to any model that undergoes training on extensive and diverse datasets, typically through self-supervisedlearning at a large scale, and is capable of being fine-tuned to suit a wide array of specific downstream tasks.
Understanding Data Structured Data: Organized data with a clear format, often found in databases or spreadsheets. Unstructured Data: Data without a predefined structure, like text documents, social media posts, or images. Data Cleaning: Process of identifying and correcting errors or inconsistencies in datasets.
This capability bridges various disciplines, leveraging techniques from statistics, machine learning, and artificial intelligence. Some key areas include: BigData analytics: It helps in interpreting vast amounts of data to extract meaningful insights.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content